Python Excel vlookup函数实现过程解析
用法:注意是用英文的逗号",",且之间没有空格。
文件名,[工作表名称,不写则默认当前激活的表],[从第几行开始,不写则默认第二行,因为很多表第一行是title],列名(第一列是要查找的元素,列名可以不连续,比如“ade”)
脚本会自动把要查找的第一列进行大小写变换,去除空格等操作,下面的例子中,第一列的名字有的是大写,有的小写,前后还有空格,脚本会默认它们相同
现有Sheet1,内容如下
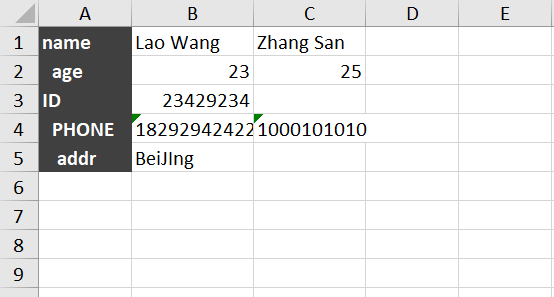
Sheet2内容如下

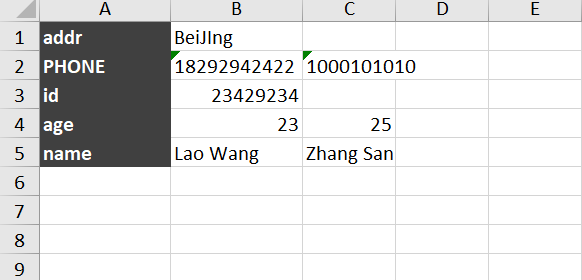
想把 Sheet1 的 B,C 列的信息复制到 Sheet2 的 B,C列上,执行脚本:
Source fileName,[sheetName],[row],columns:
vlookup.xlsx,Sheet1,1,abc
Target fileName,[sheetName],[row],columns:
vlookup.xlsx,Sheet2,1,abc
{'name': ['Lao Wang', 'Zhang San'], 'age': [23, 25], 'id': [23429234, None], 'phone': ['18292942422', '1000101010'], 'addr': ['BeiJIng', None]}
{'addr': [None, None], 'phone': [None, None], 'id': [None, None], 'age': [None, None], 'name': [None, None]}
Processing...
Done.
然后Sheet2的内容就变成了:
import openpyxl
def read_Excel(path,sheetName,row,*col):
# 默认从第二行开始,因为很多表都有表头
if row == '':
row = 2
else:
row = int(row)
workbook = openpyxl.load_workbook(path)
# 默认打开当前激活的工作表
if sheetName == "":
sheet0 = workbook.active # 获取当前激活的工作表
else:
sheet0 = workbook[sheetName] # 如果制定了工作表,就打开指定的工作表
highest = sheet0.max_row
case_list = {}
# title 所在列,对比的那一列,假设A列
title = col[0]
for i in range(row,highest+1): # 遍历行
value_list = []
if sheet0[title+str(i)].value == None: # 如果A5是空的,pass
pass
else:
v1 = sheet0[title+str(i)].value.lower().strip() # 忽略大小写和前后空格
# 除去 title的其他列
for j in range(1,len(col)):
v2 = sheet0[col[j]+str(i)].value
value_list.append(v2)
case_list[v1] = value_list
print(case_list)
return case_list
def write_Excel(dict,path,sheetName,row,*col):
# 将处理好的数据再次写入excel
if row == "":
row = 2
else:
row = int(row)
workbook = openpyxl.load_workbook(path)
if sheetName == "":
sheet0 = workbook.active # 获取当前激活的工作表
else:
sheet0 = workbook[sheetName]
highest = sheet0.max_row
# case title 所在列
title = col[0]
for i in range(row,highest+1):
if sheet0[title + str(i)].value != None:
v1 = sheet0[title + str(i)].value.lower().strip() # 忽略大小写和前后空格
for key in dict:
if key == v1:
for j in range(1,len(col)):
v2 = sheet0[col[j]+str(i)]
v2.value = dict[key][j-1]
workbook.save(path)
def process(r1,r2):
# 对比处理两次读取的内容,然后更新r2的内容
print('Processing...')
for key in r1:
if key in r2:
length = len(r1[key])
if length > 0:
for i in range(0, len(r1[key])):
# 如果想要不想覆盖原有的数值,可以取消注释,然后删除下面那行
# if r2[key][i] == None:
# r2[key][i] = r1[key][i]
r2[key][i] = r1[key][i]
else:
pass
return r2
def manual():
info1 = input('Read from fileName,[sheetName],[row],columns:\n')
file1,sheetName1,row1,list1 = info1.split(',')
info2 = input('Write into fileName,[sheetName],[row],columns:\n')
file2,sheetName2,row2,list2 = info2.split(',')
r1 = read_Excel(file1,sheetName1,row1,*list1)
r2 = read_Excel(file2,sheetName2,row2,*list2)
r3 = process(r1,r2)
write_Excel(r3,file2,sheetName2,row2,*list2)
print('Done.')
if __name__ == "__main__":
manual()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python使用Excel将数据写入多个sheet
将一个列表数据写入output.xlsx的a,b,c--等sheet中 import pandas as pd df1 = pd.DataFrame({'a':[3,1],'b':[4,3]}) df2 = df1.copy() with pd.ExcelWriter('F:\\python入门\\数据2\\output.xlsx') as writer: str1 = ['a','b','c','d','e','f','g','h','i',\ 'j','k','l','m','n','o',
-
基于python实现把json数据转换成Excel表格
json数据: [{"authenticate":-99,"last_ip":"156.2.98.429","last_time":"2020/05/23 01:41:36","member_id":5067002,"mg_id":1,"name":"yuanfang","status":0,"us
-
Python3使用xlrd、xlwt处理Excel方法数据
说在前头 最近在做毕设,题目是道路拥堵预测系统,学长建议我使用SVM算法进行预测,但是在此之前需要把Excel中的数据进行二次处理,原始数据不满足我的需要,可是..有346469条数据,不能每一条都自己进行运算并且将它进行归一化运算!! 作为一个Java开发者,Python的使用我是从来没用过的啊,也是作死选了个这么难的题目..后来在网上查阅发现xlrd可以通过Python代码读取Excel的文件,他的含义是xls文件的read(只读),另外它的同类是xlwt(xls的write喽~),这个是可
-
利用python在excel中画图的实现方法
一.前言 以前大学时候,学EXCEL看到N多大神利用excel画图,觉得很不可思议.今个学了一个来月python,膨胀了就想用excel画图.当然,其实用画图这个词不甚严谨,实际上是利用opencv遍历每一个像素的rgb值,再将其转化为16进制,最后调用openpyxl进行填充即可. 1.1.实现效果 效果如下图 1.2.需要用到的库的安装 需要用到库如下: import cv2 #导入OpenCV库 import xlsxwriter #利用这个调整行高列宽 import openpyxl #
-
Python导入数值型Excel数据并生成矩阵操作
riginal_Data 因为程序是为了实现对纯数值型Excel文档进行导入并生成矩阵,因此有必要对第五列文本值进行删除处理. Import_Data import numpy as np import xlrd def import_excel_matrix(path): table = xlrd.open_workbook(path).sheets()[0] # 获取第一个sheet表 row = table.nrows # 行数 col = table.ncols # 列数 datamat
-
解决python执行较大excel文件openpyxl慢问题
我就废话不多说了,大家还是直接看代码吧! talk is cheap from openpyxl import Workbook from openpyxl.utils import get_column_letter from openpyxl import load_workbook import time wb = load_workbook("E:/a.xlsx", read_only=True) sh = wb["Sheet"] # rowItem = {
-
Python读取excel文件中带公式的值的实现
在进行excel文件读取的时候,我自己设置了部分直接从公式获取单元格的值 但是用之前的读取方法进行读取的时候,返回值为空 import os import xlrd from xlutils.copy import copy file_path = os.path.abspath(os.path.dirname(__file__)) # 获取当前文件目录 print(file_path) root_path = os.path.dirname(file_path) # 获取文件上级目录 data
-

python2 对excel表格操作完整示例
本文实例讲述了python2 对excel表格操作.分享给大家供大家参考,具体如下: #!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Sat Dec 2 15:40:35 2017 @author: 260207 """ from xlutils.copy import copy import xlrd import xlwt def set_style(name = '
-
Python pandas如何向excel添加数据
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
Python Excel vlookup函数实现过程解析
用法:注意是用英文的逗号",",且之间没有空格. 文件名,[工作表名称,不写则默认当前激活的表],[从第几行开始,不写则默认第二行,因为很多表第一行是title],列名(第一列是要查找的元素,列名可以不连续,比如"ade") 脚本会自动把要查找的第一列进行大小写变换,去除空格等操作,下面的例子中,第一列的名字有的是大写,有的小写,前后还有空格,脚本会默认它们相同 现有Sheet1,内容如下 Sheet2内容如下 想把 Sheet1 的 B,C 列的信息复制到 She
-
Python测试线程应用程序过程解析
这篇文章主要介绍了Python测试线程应用程序过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在本章中,我们将学习线程应用程序的测试.我们还将了解测试的重要性. 为什么要测试? 在我们深入讨论测试的重要性之前,我们需要知道测试的内容.一般来说,测试是一种了解某些东西是如何运作的技术.另一方面,特别是如果我们谈论计算机程序或软件,那么测试就是访问软件程序功能的技术. 在本节中,我们将讨论软件测试的重要性.在软件开发中,必须在向客户端发布软
-
python全局变量引用与修改过程解析
这篇文章主要介绍了python全局变量引用与修改过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.引用 使用到的全局变量只是作为引用,不在函数中修改它的值的话,不需要加global关键字.如: #! /usr/bin/python a = 1 b = [2, 3] def func(): if a == 1: print("a: %d" %a) for i in range(4): if i in b: print(&quo
-
Python Decorator的设计模式演绎过程解析
目录 关于代理模式.装饰模式 Python中的代理/装饰 还有什么不理想的地方呢? 补充 关于代理模式.装饰模式 设计模式中经常提到的代理模式.装饰模式,这两种叫法实际上是说的同一件事,只是侧重点有所不同而已. 这两者都是通过在原有对象的基础上封装一层对象,通过调用封装后的对象而不是原来的对象来实现代理/装饰的目的. 例如:(以Java为例) public class CountProxy implements Count { private CountImpl countImpl; publi
-
python打包成so文件过程解析
这篇文章主要介绍了python打包成so文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 wget https://bootstrap.pypa.io/get-pip.py python get-pip.py pip install cython 编写setput.py文件: setup.py文件内容如下: from distutils.core import setup from distutils.extension import
-
python文字转语音实现过程解析
这篇文章主要介绍了python文字转语音实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用百度接口 接口地址 https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top 安装接口 pip install baidu-aip from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID =
-
python使用rsa非对称加密过程解析
这篇文章主要介绍了python使用rsa非对称加密过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.安装rsa 支持python 2.7 或者 python 3.5 以上版本 使用豆瓣pypi源来安装rsa pip install -i https://pypi.douban.com/simple rsa 2.加密解密 2.1.生成公私钥对 import rsa # 1.接收者(A)生成512位公私钥对 # a. lemon_pub为
-
Python namedtuple命名元组实现过程解析
这篇文章主要介绍了Python namedtuple命名元组实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 命名元组(namedtuple)是一种带有属性的元组,它们是组合只读数据的很好的方式. 相比一般的元组,构造命名元组需要先导入namedtuple,因为它不在默认的命名空间里.然后通过名字和属性来定义一个命名元组.这会返回一个像类一样的对象,可以进行多次实例化. 命名元组可以被打包.解包以及做所有可以对普通元组做的事,并且还可
-
python自动化unittest yaml使用过程解析
这篇文章主要介绍了python自动化unittest yaml使用过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在编写unittest自动化用例时,一个请求需要编写多条用例,而涉及的参数基本相同,这时候就会用到配置文件,可以把参数配置项统一管理,避免重复代码,也方便后期维护 此处用到的是yaml,首先需要安装yaml库,pip install yaml 安装成功后,脚本导入语句,import yaml,具体语法可参照如上入门教程 举例
-
python中namedtuple函数的用法解析
源码解释: def namedtuple(typename, field_names, *, rename=False, defaults=None, module=None): """Returns a new subclass of tuple with named fields. >>> Point = namedtuple('Point', ['x', 'y']) >>> Point.__doc__ # docstring for