pyspark对Mysql数据库进行读写的实现
pyspark是Spark对Python的api接口,可以在Python环境中通过调用pyspark模块来操作spark,完成大数据框架下的数据分析与挖掘。其中,数据的读写是基础操作,pyspark的子模块pyspark.sql 可以完成大部分类型的数据读写。文本介绍在pyspark中读写Mysql数据库。
1 软件版本
在Python中使用Spark,需要安装配置Spark,这里跳过配置的过程,给出运行环境和相关程序版本信息。
- win10 64bit
- java 13.0.1
- spark 3.0
- python 3.8
- pyspark 3.0
- pycharm 2019.3.4
2 环境配置
pyspark连接Mysql是通过java实现的,所以需要下载连接Mysql的jar包。

选择下载Connector/J,然后选择操作系统为Platform Independent,下载压缩包到本地。

然后解压文件,将其中的jar包mysql-connector-java-8.0.19.jar放入spark的安装目录下,例如D:\spark\spark-3.0.0-preview2-bin-hadoop2.7\jars。
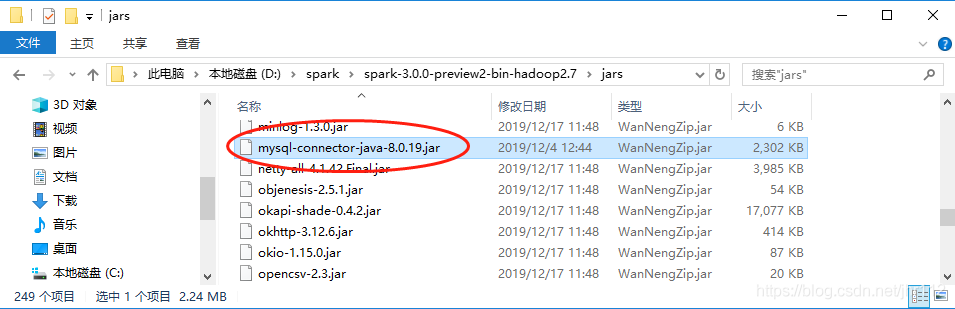
环境配置完成!
3 读取Mysql
脚本如下:
from pyspark.sql import SQLContext, SparkSession
if __name__ == '__main__':
# spark 初始化
spark = SparkSession. \
Builder(). \
appName('sql'). \
master('local'). \
getOrCreate()
# mysql 配置(需要修改)
prop = {'user': 'xxx',
'password': 'xxx',
'driver': 'com.mysql.cj.jdbc.Driver'}
# database 地址(需要修改)
url = 'jdbc:mysql://host:port/database'
# 读取表
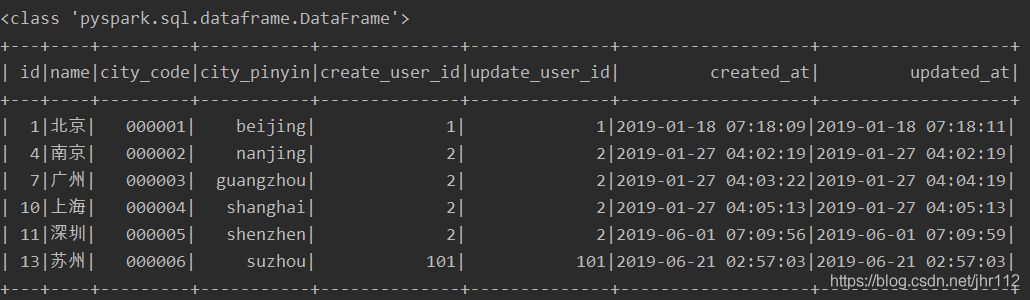
data = spark.read.jdbc(url=url, table='tb_newCity', properties=prop)
# 打印data数据类型
print(type(data))
# 展示数据
data.show()
# 关闭spark会话
spark.stop()
- 注意点:
prop参数需要根据实际情况修改,文中用户名和密码用xxx代替了,driver参数也可以不需要;url参数需要根据实际情况修改,格式为jdbc:mysql://主机:端口/数据库;- 通过调用方法
read.jdbc进行读取,返回的数据类型为spark DataFrame;
运行脚本,输出如下:
4 写入Mysql
脚本如下:
import pandas as pd
from pyspark import SparkContext
from pyspark.sql import SQLContext, Row
if __name__ == '__main__':
# spark 初始化
sc = SparkContext(master='local', appName='sql')
spark = SQLContext(sc)
# mysql 配置(需要修改)
prop = {'user': 'xxx',
'password': 'xxx',
'driver': 'com.mysql.cj.jdbc.Driver'}
# database 地址(需要修改)
url = 'jdbc:mysql://host:port/database'
# 创建spark DataFrame
# 方式1:list转spark DataFrame
l = [(1, 12), (2, 22)]
# 创建并指定列名
list_df = spark.createDataFrame(l, schema=['id', 'value'])
# 方式2:rdd转spark DataFrame
rdd = sc.parallelize(l) # rdd
col_names = Row('id', 'value') # 列名
tmp = rdd.map(lambda x: col_names(*x)) # 设置列名
rdd_df = spark.createDataFrame(tmp)
# 方式3:pandas dataFrame 转spark DataFrame
df = pd.DataFrame({'id': [1, 2], 'value': [12, 22]})
pd_df = spark.createDataFrame(df)
# 写入数据库
pd_df.write.jdbc(url=url, table='new', mode='append', properties=prop)
# 关闭spark会话
sc.stop()
注意点:
prop和url参数同样需要根据实际情况修改;
写入数据库要求的对象类型是spark DataFrame,提供了三种常见数据类型转spark DataFrame的方法;
通过调用write.jdbc方法进行写入,其中的model参数控制写入数据的行为。
| model | 参数解释 |
|---|---|
| error | 默认值,原表存在则报错 |
| ignore | 原表存在,不报错且不写入数据 |
| append | 新数据在原表行末追加 |
| overwrite | 覆盖原表 |
5 常见报错
Access denied for user …
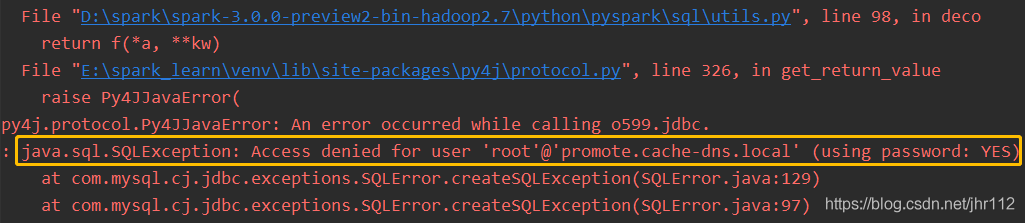
原因:mysql配置参数出错
解决办法:检查user,password拼写,检查账号密码是否正确,用其他工具测试mysql是否能正常连接,做对比检查。
No suitable driver

原因:没有配置运行环境
解决办法:下载jar包进行配置,具体过程参考本文的2 环境配置。
到此这篇关于pyspark对Mysql数据库进行读写的实现的文章就介绍到这了,更多相关pyspark Mysql读写内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL的使用中实现读写分离的教程
mysql-proxy实现读写分离 MySQL Proxy是一个处于你的client端和MySQL server端之间的简单程序,它可以监测.分析或改变它们的通信.它使用灵活,没有限制,常见的用途包括:负载平衡,故障.查询分析,查询过滤和修改等等. MySQL Proxy就是这么一个中间层代理,简单的说,MySQL Proxy就是一个连接池,负责将前台应用的连接请求转发给后台的数据库,并且通过使用lua脚本,可以实现复杂的连接控制和过滤,从而实现读写分离和负载平衡.对于应用来说,MySQL Pr
-

mysql 读写分离(实战篇)
MySQL Proxy最强大的一项功能是实现"读写分离(Read/Write Splitting)".基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询.数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库. Jan Kneschke在<MySQL Proxy learns R/W Splitting>中详细的介绍了这种技巧以及连接池问题: 为了实现读写分离我们需要连接池.我们仅在已打开了到一个后端的一条经过认证的连接的情况下,才切换到该后端.My
-
使用PHP实现Mysql读写分离
本代码是从uchome的代码修改的,是因为要解决uchome的效率而处理的.这个思维其实很久就有了,只是一直没有去做,相信也有人有同样的想法,如果有类似的,那真的希望提出相关的建议. 封装的方式比较简单,增加了只读数据库连接的接口扩展,不使用只读数据库也不影响原代码使用.有待以后不断完善..为了方便,试试建立了google的一个项目:http://code.google.com/p/mysql-rw-php/希望给有需要的朋友带来帮助. PHP实现的Mysql读写分离主要特性:1.简单的读写分离
-
PHP+MYSQL实现读写分离简单实战
1.Introduction 之前写过2篇文章,分别是: Mysql主从同步的原理 Myql主从同步实战 基于此,我们再实现简单的PHP+Mysql读写分离,从而提高数据库的负载能力. 2.代码实战 <?php class Db { private $res; function __construct($sql) { $querystr = strtolower(trim(substr($sql,0,6))); //如果是select,就连接slave服务器 if($querystr == 's
-
MySQL主从同步、读写分离配置步骤
现在使用的两台服务器已经安装了MySQL,全是rpm包装的,能正常使用. 为了避免不必要的麻烦,主从服务器MySQL版本尽量保持一致; 环境:192.168.0.1 (Master) 192.168.0.2 (Slave) MySQL Version:Ver 14.14 Distrib 5.1.48, for pc-linux-gnu (i686) using readline 5.1 1.登录Master服务器,修改my.cnf,添加如下内容: server-id = 1 //数据库ID号,
-
mysql 读写分离(基础篇)
基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询.数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库. Jan Kneschke在<MySQL Proxy learns R/W Splitting>中详细的介绍了这种技巧以及连接池问题: 为了实现读写分离我们需要连接池.我们仅在已打开了到一个后端的一条经过认证的连接的情况下,才切换到该后端.MySQL协议首先进行握手.当进入到查询/返回结果的阶段再认证新连接就太晚了.我们必须保证拥有足够的打开的连接才能保持运作正常
-
Mysql(MyISAM)的读写互斥锁问题的解决方法
由于没办法在短期内增加读的服务器,所以采取对Mysql进行了一些配置,以牺牲数据实时性为代价,来换取所有服务器的生命安全.呵呵,具体相关调整以及思路如下: MyISAM在读操作占主导的情况下是很高效的.可一旦出现大量的读写并发,同InnoDB相比,MyISAM的效率就会直线下降,而且,MyISAM和 InnoDB的数据存储方式也有显著不同:通常,在MyISAM里,新数据会被附加到数据文件的结尾,可如果时常做一些UPDATE,DELETE操作之后,数据文件就不再是连续的,形象一点来说,就是数据文件
-
mysql主从复制读写分离的配置方法详解
一.说明 前面我们说了mysql的安装配置,mysql语句使用以及备份恢复mysql数据;本次要介绍的是mysql的主从复制,读写分离;及高可用MHA; 环境如下: master:CentOS7_x64 mysql5.721 172.16.3.175 db1 slave1:CentOS7_x64 mysql5.7.21 172.16.3.235 db2 slave2:CentOS7_x64 mysql5.7.21 172.16.3.235 db3 proxysql/MHA:CentOS7_x64
-
详解MySQL的主从复制、读写分离、备份恢复
一.MySQL主从复制 1.简介 我们为什么要用主从复制? 主从复制目的: 可以做数据库的实时备份,保证数据的完整性: 可做读写分离,主服务器只管写,从服务器只管读,这样可以提升整体性能. 原理图: 从上图可以看出,同步是靠log文件同步读写完成的. 2.更改配置文件 两天机器都操作,确保 server-id 要不同,通常主ID要小于从ID.一定注意. # 3306和3307分别代表2台机器 # 打开log-bin,并使server-id不一样 #vim /data/3306/my.cnf lo
-
pyspark对Mysql数据库进行读写的实现
pyspark是Spark对Python的api接口,可以在Python环境中通过调用pyspark模块来操作spark,完成大数据框架下的数据分析与挖掘.其中,数据的读写是基础操作,pyspark的子模块pyspark.sql 可以完成大部分类型的数据读写.文本介绍在pyspark中读写Mysql数据库. 1 软件版本 在Python中使用Spark,需要安装配置Spark,这里跳过配置的过程,给出运行环境和相关程序版本信息. win10 64bit java 13.0.1 spark 3.0
-
Python使用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写.首先我们需要了解点ORM方面的知识 ORM技术 对象关系映射技术,即ORM(Object-Relational Mapping)技术,指的是把关系数据库的表结构映射到对象上,通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中. 在Python中,最有名的ORM框架是SQLAlchemy.Java中典型的ORM中间件有:Hibernate,ibatis,speedframework. SQ
-
Mysql数据库之主从分离实例代码
介绍 MySQL数据库设置读写分离,可以使对数据库的写操作和读操作在不同服务器上执行,提高并发量和相应速度. 现在的网站一般大点的,都采用有数据库主从分离.读写分离,即起到备份作用也可以减轻数据库的读写的压力,一直听说过这些,但是自己从没有自己动手亲手实践过,今天有时间实践一下,记录下过程. 实验环境 我准备了两台服务器,一个是本机电脑,一个是远程vps,分别在两台机子上装的有数据库. MySQL安装我就不介绍了,这里需要注意的是:MySQL安装的版本最好一致,如果不一致,低版本向高版本读的时候
-
Python操作MySQL数据库的两种方式实例分析【pymysql和pandas】
本文实例讲述了Python操作MySQL数据库的两种方式.分享给大家供大家参考,具体如下: 第一种 使用pymysql 代码如下: import pymysql #打开数据库连接 db=pymysql.connect(host='1.1.1.1',port=3306,user='root',passwd='123123',db='test',charset='utf8') cursor=db.cursor()#使用cursor()方法获取操作游标 sql = "select * from tes
-
thinkphp下MySQL数据库读写分离代码剖析
当采用原生态的sql语句进行写入操作的时候,要用execute,读操作要用query. MySQL数据主从同步还是要靠MySQL的机制来实现,所以这个时候MySQL主从同步的延迟问题是需要优化,延迟时间太长不仅影响业务,还影响用户体验. thinkphp核心类Thinkphp/library/Model.class.php 中,query 方法,调用Thinkphp/library/Think/Db/Driver/Mysql.class.php /** * SQL查询 * @access pub
-
Yii实现MySQL多数据库和读写分离实例分析
本文实例分析了Yii实现MySQL多数据库和读写分离的方法.分享给大家供大家参考.具体分析如下: Yii Framework是一个基于组件.用于开发大型 Web 应用的高性能 PHP 框架.Yii提供了今日Web 2.0应用开发所需要的几乎一切功能,也是最强大的框架之一,下文我们来介绍Yii实现MySQL多库和读写分离的方法 前段时间为SNS产品做了架构设计,在程序框架方面做了不少相关的压力测试,最终选定了YiiFramework,至于为什么没选用公司内部的 PHP框架,其实理由很充分,公司的框
-
shell脚本连接、读写、操作mysql数据库实例
本文介绍了如何在shell中读写mysql数据库.主要介绍了如何在shell 中连接mysql数据库,如何在shell中创建数据库,创建表,插入csv文件,读取mysql数据库,导出mysql数据库为xml或html文件, 并分析了核心语句.本文介绍的方法适用于PostgreSQL ,相对mysql而言,shell 中读写PostgreSQL会更简单些. 1. 连接mysql 数据库 shell中连接数据库的方法很简单,只需要指定用户名,密码,连接的数据库名称,然后通过重定向,输入mysql的语
-
spring集成mybatis实现mysql数据库读写分离
前言 在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈.幸运的是目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库的数据更新同步到另一台服务器上.网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力.如下图所示: 应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据.为了便于应用程序访问读写分离后的数据库,通常在应用服务器使用专门的数
-
详解如何利用amoeba(变形虫)实现mysql数据库读写分离
关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的.由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用: amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk: 前期准备工作: 1.两个数据库,一主一从,主从同步: master: 172.22.10.237:3306 :主库负责写入操作: slave: 10.4.66.58
-
SpringBoot自定义注解使用读写分离Mysql数据库的实例教程
需求场景 为了防止代码中有的SQL慢查询,影响我们线上主数据库的性能.我们需要将sql查询操作切换到从库中进行.为了使用方便,将自定义注解的形式使用. mysql导入的依赖 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.16</version> </dependency&