使用python实现希尔、计数、基数基础排序的代码
希尔排序
希尔排序是一个叫希尔的数学家提出的一种优化版本的插入排序。
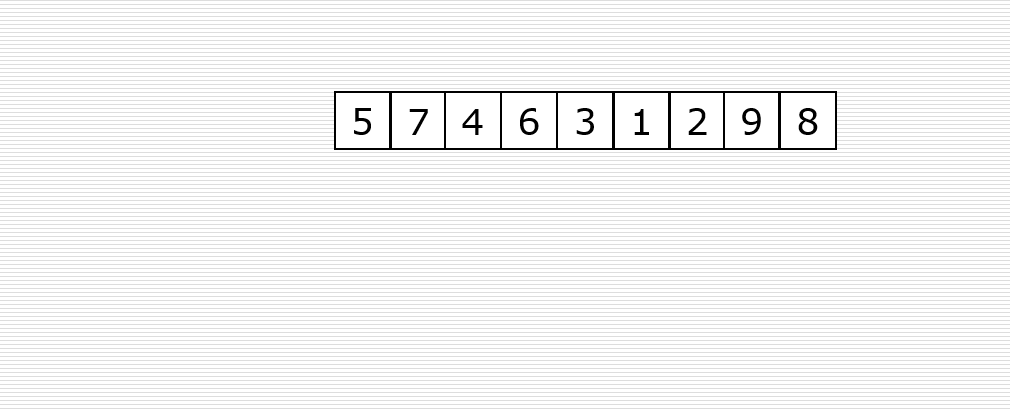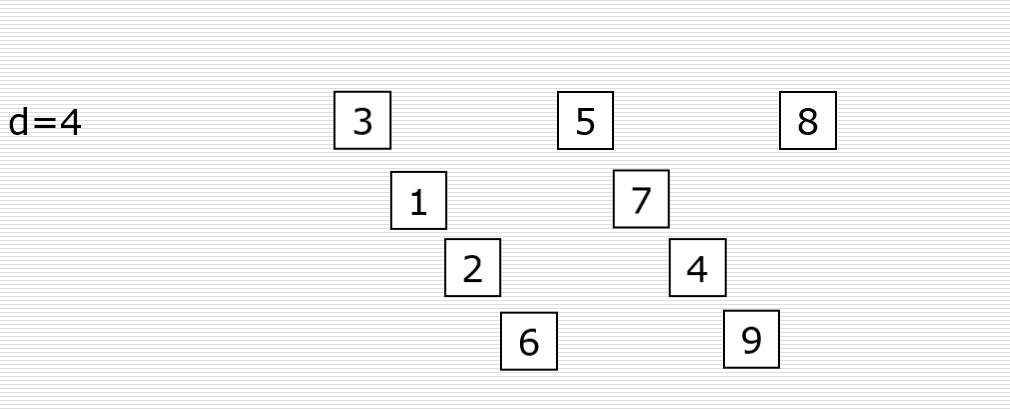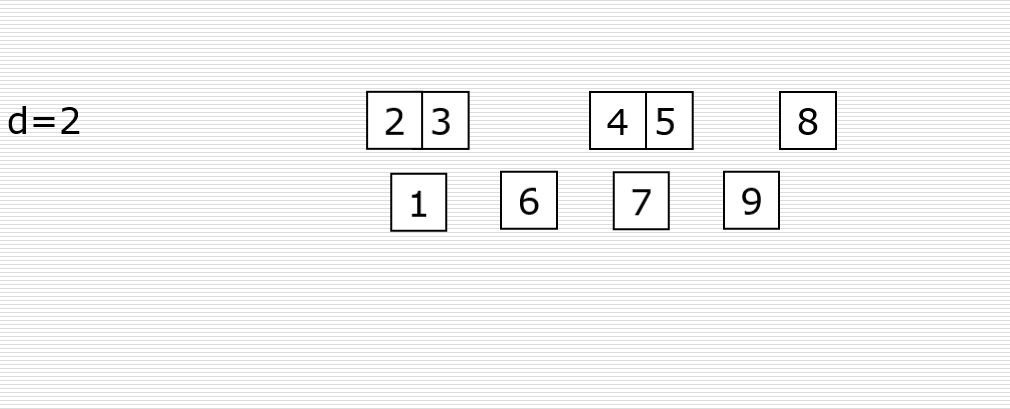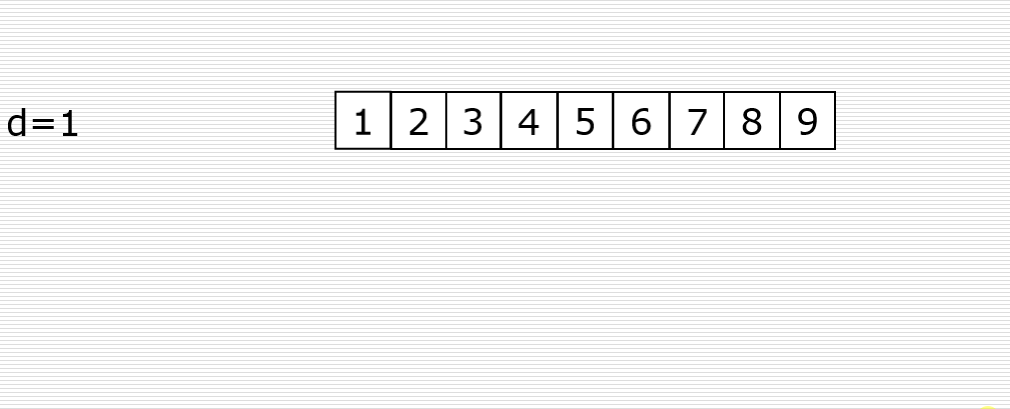
首先取一个整数d1=n//2,将元素分为d1个组,每组相邻元素之间的距离为d1,在各组内进行直接插入排序。
取第二个整数d2=d1//2,重复上述分组排序过程,直到di=1,即所有元素在同一组内进行直接插入排序。
希尔排序是使整体数据越来越接近有序;最后一趟排序使得所有数据有序。
实现
# 希尔排序
def shell_sort(li):
n = len(li)
gap = n // 2
while gap > 0:
for i in range(gap, n):
temp = li[i]
j = i - gap
while j >= 0 and li[j] > temp:
li[j + gap] = li[j]
j -= gap
li[j + gap] = temp
gap //= 2
算法分析
- 时间复杂度:O(n1.3)
- 最好时间复杂度:O(n)
- 最坏时间复杂度:O(n2)
- 空间复杂度:O(1)
- 稳定性:不稳定
计数排序
计数排序是一种非比较性质的排序算法,元素从未排序状态变为已排序状态的过程,是由额外空间的辅助和元素本身的值决定的。
计数排序过程中不存在元素之间的比较和交换操作,根据元素本身的值,将每个元素出现的次数记录到辅助空间后,通过对辅助空间内数据的计算,即可确定每一个元素最终的位置。
- 根据待排序集合中最大元素和最小元素的差值范围,申请额外空间;
- 遍历待排序集合,将每一个元素出现的次数记录到元素值对应的额外空间内;
- 对额外空间内数据进行计算,得出每一个元素的正确位置;
- 将待排序集合每一个元素移动到计算得出的正确位置上。

实现
def count_sort(li, max_num=100):
count = [0 for _ in range(max_num + 1)]
for val in li:
count[val] += 1
li.clear()
# 表示i这个数出现了v次
for i, v in enumerate(count):
for _ in range(v):
li.append(i)
算法分析
假定原始数列的规模是N
最大值和最小值的差是M
计数排序的时间复杂度是O(N+M)
如果不考虑结果数组,只考虑中间数组大小的话,空间复杂度是O(M)
基数排序
基数排序(英语:Radix sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
多关键字排序:现在有一个员工,要求按照薪资排序,年龄相同的员工按照按照年龄排序。
先按照年龄进行排序,再按照薪资进行稳定的排序。
对32,13,94,52,17,54,93进行排序,是否可以看作多关键字排序?
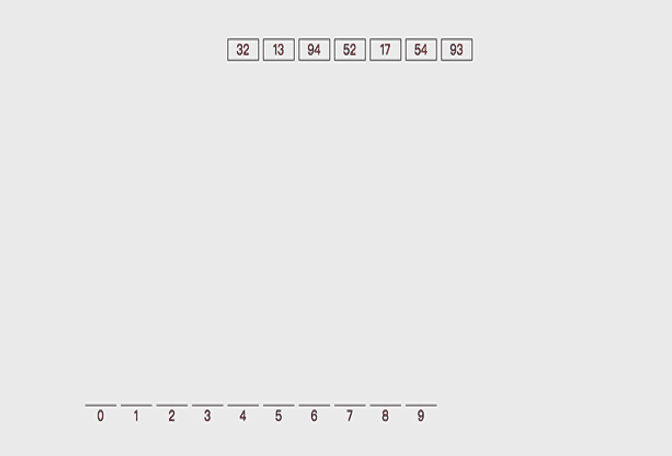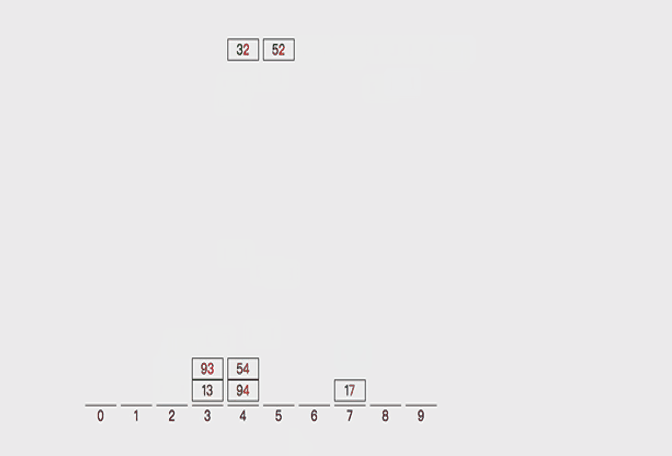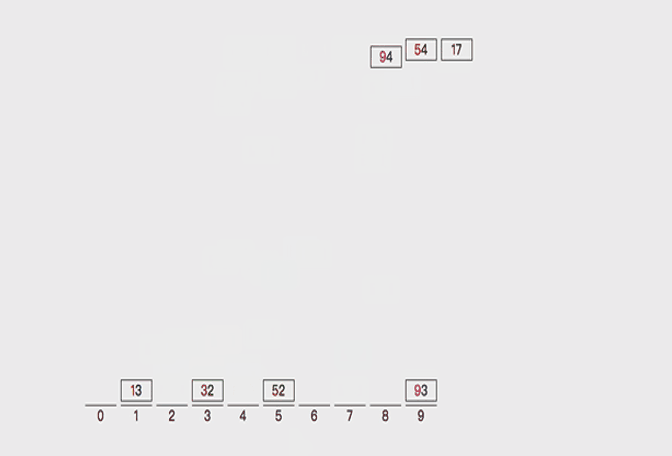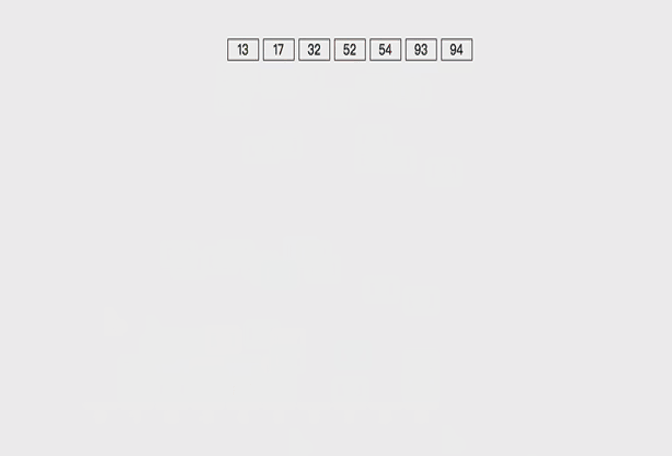
实现
# 基数排序
def radix_sort(li):
max_num = max(li)
i = 0
while (10 ** i <= max_num):
buckets = [[] for _ in range(10)]
for val in li:
# i=0 个位 i=1 十位 i=2 百位 ..
digit = val // (10**i) % 10
buckets[digit].append(val)
li.clear()
for bucket in buckets:
for val in bucket:
li.append(val)
i += 1
算法分析
- 时间复杂度:O(kn)
- 最好时间复杂度:O(kn)
- 最坏时间复杂度:O(kn)
- 空间复杂度:O(n+k)
- 稳定性:稳定
总结
以上所述是小编给大家介绍的使用python实现希尔、计数、基数基础排序,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python将列表中的元素转化为数字并排序的示例
本文实例讲述了Python中列表元素转为数字的方法.分享给大家供大家参考,具体如下: 有一个数字字符的列表: numbers = ['2', '4', '1', '3'] 想要把每个元素转换为数字: numbers = [2, 4, 1, 3] 1. Python2.x,可以使用map函数: numbers = map(int, numbers) 2. Python3.x,map返回的是map对象,当然也可以转换为List: numbers = list(map(int, numbers)) 排
-
python list多级排序知识点总结
在python3的sorted中去掉了cmp参数,转而推荐"key+lambda"的方式来排序. 如果需要对python的list进行多级排序.有如下的数据: list_num = [[12,3],[18,34],[18,10],[12,45],[18,10],[8,34]] 需要从小到大的排序.先比较第一个数,如果第一个数相等的话比较第二个数.代码如下: #默认的sort函数会先对第一个比较,如果第一个相等再比较第二个 print(sorted(list_num)) //OUTPUT
-
Python实现快速排序的方法详解
本文实例讲述了Python实现快速排序的方法.分享给大家供大家参考,具体如下: 说起快排的Python实现,首先谈一下,快速排序的思路: 1.取一个参考值放到列表中间,初次排序后,让左侧的值都比他小,右侧的值,都比他大. 2.分别对左侧和右侧的部分递归第1步的操作 实现思路: 两个指针left,right分别指向列表的第一个元素和最后一个元素,然后取一个参考值,默认为第一个列表的第一个元素list[0],称为K 然后left指向的值先和参考值K进行比较,若list[left]小于或等于K值,le
-
python 实现多维数组(array)排序
关于多维数组如何复合排序 如数组: >>> import numpy as np >>> data = np.array([[2,2,5],[2,1,3],[1,2,3],[3,1,4]]) >>>> data array([[2, 2, 5], [2, 1, 3], [1, 2, 3], [3, 1, 4]]) 将数组先按照第一列升序,第二列升序,第三列升序的方式排序: >>> idex=np.lexsort([data[:,
-
python中字典按键或键值排序的实现代码
字典排序 在程序中使用字典进行数据信息统计时,由于字典是无序的所以打印字典时内容也是无序的.因此,为了使统计得到的结果更方便查看需要进行排序.Python中字典的排序分为按"键"排序和按"值"排序. 按"值"排序 按"值"排序就是根据字典的值进行排序,可以使用内置的sorted()函数. sorted(iterable[, cmp[, key[, reverse]]]) iterable:是可迭代类型类型; cmp:用于比较的
-
Python函数参数类型及排序原理总结
这篇文章主要介绍了Python函数参数类型及排序原理总结,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python中函数的参数问题有点复杂,主要是因为参数类型问题导致的情况比较多,下面来分析一下. 参数类型:缺省参数,关键字参数,不定长位置参数,不定长关键字参数. 其实总共可以分为 位置参数和关键字参数,因为位置参数被放在list里面,关键字参数放在dict里面,Python在解读的时候首先处理list,没有遇到关键字就append到list
-
Python 使用多属性来进行排序
Python 中 list.sort() 是列表中非常常用的排序函数, key 参数可以对单个属性进行排序. 但是想要实现类似 sql 中 order by id, age 一样,对多个字段进行排序就不支持了. py2 中 sort() 函数还有个 cmp 参数可以传入一个方法,可以自定义对多个属性进行排序,py3 中移除了这个字段. py3 想要实现这个功能,需要使用 functools 模块中的方法,实例如下 #!/usr/bin/env python # -*- coding:utf-8
-
python字典排序的方法
python字典怎么排序? 定义一个字典类型 mydict = {2: '小路', 3: '黎明', 1: '郭富城', 4:'周董'} 可分别打印 key和value 看一下数据 按KEY排序,使用了 lambda和 reverse= False(正序) key和value都输出 reverse= True(逆序) 按value排序,汉字次序不是按拼音输出 sorted并不改变字典本身的数据次序. 输出后为列表和元组 可以 A = sorted(mydict.items(),key = lam
-
python快速排序的实现及运行时间比较
快速排序的基本思想:首先选定一个数组中的一个初始值,将数组中比该值小的放在左边,比该值大的放在右边,然后分别对左边的数组进行如上的操作,对右边的数组进行如上的操作.(分治+递归) 1.利用匿名函数lambda 匿名函数的基本用法func_name = lambda x:array,冒号左边的x代表传入的参数,冒号右边的array代表返回值,当然名字是可以自己取的. quick_sort = lambda array: \ array if len(array) <= 1 \ else quic
-

利用python实现冒泡排序算法实例代码
冒泡排序 冒泡排序(英语:Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 冒泡排序算法的运作如下: 1.比较相邻的元素.如果第一个比第二个大(升序),就交换他们两个. 2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.这步做完后,最后的元素会是最大的数.
-
10个python3常用排序算法详细说明与实例(快速排序,冒泡排序,桶排序,基数排序,堆排序,希尔排序,归并排序,计数排序)
我简单的绘制了一下排序算法的分类,蓝色字体的排序算法是我们用python3实现的,也是比较常用的排序算法. Python3常用排序算法 1.Python3冒泡排序--交换类排序 冒泡排序(Bubble Sort)也是一种简单直观的排序算法. 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来. 走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 作为最简单的排序算法
-
python实现堆排序的实例讲解
堆排序 堆是一种完全二叉树(是除了最后一层,其它每一层都被完全填充,保持所有节点都向左对齐),首先需要知道概念:最大堆问题,最大堆就是根节点比子节点值都大,并且所有根节点都满足,那么称它为最大堆.反之最小堆. 当已有最大堆,如下图,首先将7提出,然后将堆中最后一个元素放到顶点上,此时这个堆不满足最大堆了,那么我们要给它构建成最大堆,需要找到此时堆中对打元素然后交换,此时最大值为6,符合最大堆后,我们将6提取出来,然后将堆中最后一个元素放到堆的顶部...以此类推.最后提取的数值7,6,5,4,3,
-
python常用排序算法的实现代码
这篇文章主要介绍了python常用排序算法的实现代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 排序是计算机语言需要实现的基本算法之一,有序的数据结构会带来效率上的极大提升. 1.插入排序 插入排序默认当前被插入的序列是有序的,新元素插入到应该插入的位置,使得新序列仍然有序. def insertion_sort(old_list): n=len(old_list) k=0 for i in range(1,n): temp=old_lis