Selenium 4.2.0 标签定位8种方法详解
目录
- 背景
- 元素定位
- 定位元素的方法
- 实例
- 测试目的
- ID、CSS_SELECTOR
- NAME、LINK_TEXT、PARTIAL_LINK_TEXT
- CSS、XPATH
- TAG_NAME、CLASS
背景
Selenium4使用find_element(by=By.**, value=*)来替换了原来的find_element_by_* 的方法,使用find_elements(by=By.*, value=*)来替换了原来的find_elements_by_* 的方法。
By类定义在 site-packages\selenium\webdriver\common\by.py中:
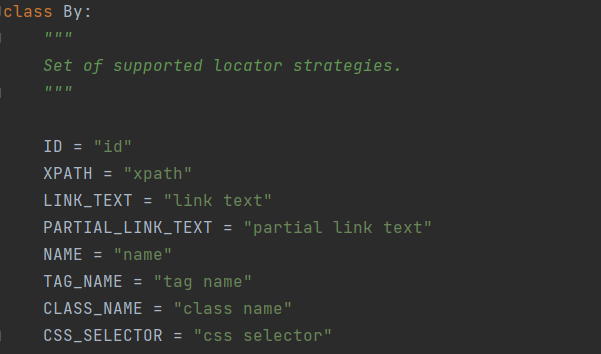
这就是Selenium4的8种定位方法
元素定位
元素本身是什么:HTML静态页面中的的一个标签
元素定位一般而言是基于元素自身所包含有的特点来进行定位的。
包括:标签的名称(决定元素是什么)、标签的属性(决定元素有什么特质),标签的文本
定位元素的方法
ID = “id”
XPATH = “xpath”
LINK_TEXT = “link text”
PARTIAL_LINK_TEXT = “partial link text”
NAME = “name”
TAG_NAME = “tag name”
CLASS_NAME = “class name”
CSS_SELECTOR = “css selector”
- id:有ID就用ID定位,基本不会重复
- name:有name可以考虑用,name类似于人的名字,虽然相对少见的值,但是容易重名
- link text:基于文本定位链接标签
- partial link text:类似于SQL中的like%,模糊查找
- tag name:基于标签名称来查找元素,大概率有多个结果,一般用于查找多个重复的内容的时候使用。
- class:基于class属性进行元素查找,非必要不推荐,重复率高
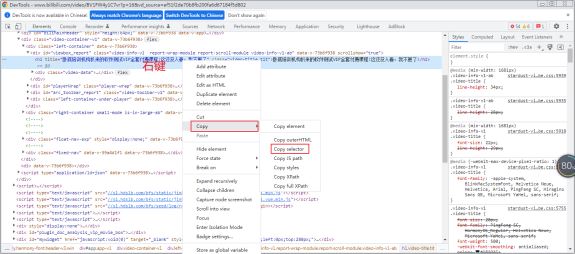
- css selector:定位界万金油,有自己的独特语法,定位语法麻烦,基于标签的class内容进行定位,使用copy
- selector确定位置
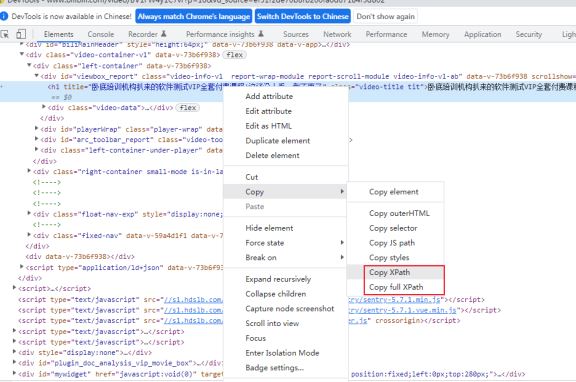
xpath:定位界万金油,有自己的独特语法,定位速度慢,基于树状结构形态定位,使用Copy XPath, Copy full
XPath来确定位置
总结:有id用id,没id用name,都不行用css/xpath,链接可以用link text。find_element元素定位如果同时有多个结果,默认返回定位的第一个结果;find_elements元素定位返回一个列表
实例
测试目的
测试Selenium4的8种元素定位方法
ID、CSS_SELECTOR
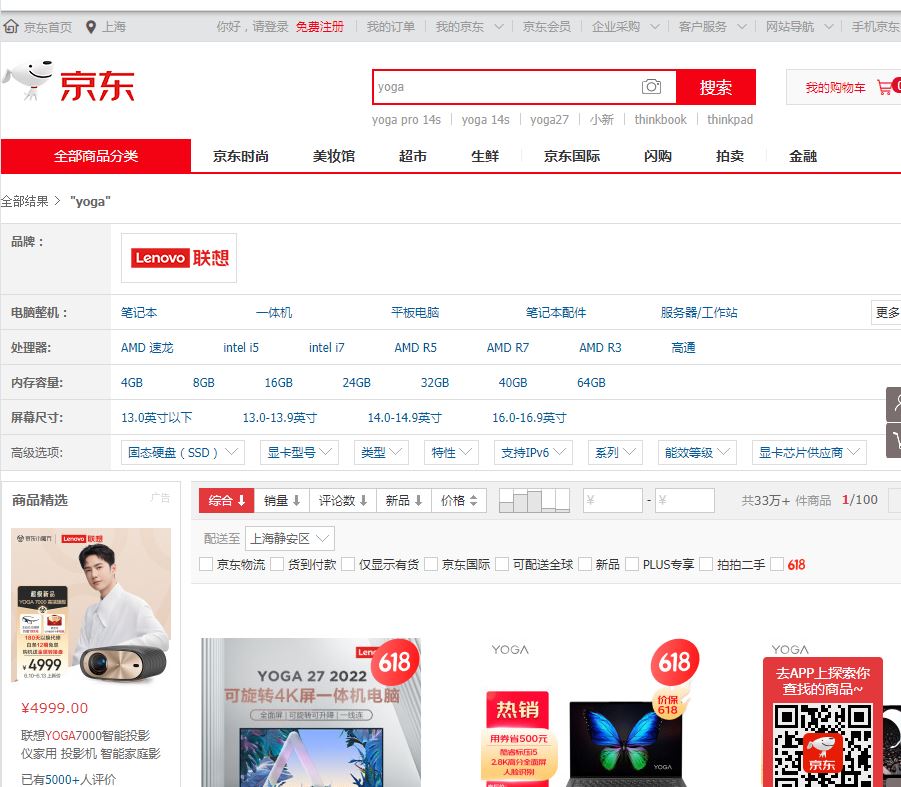
输入栏输入yoga,点击搜索
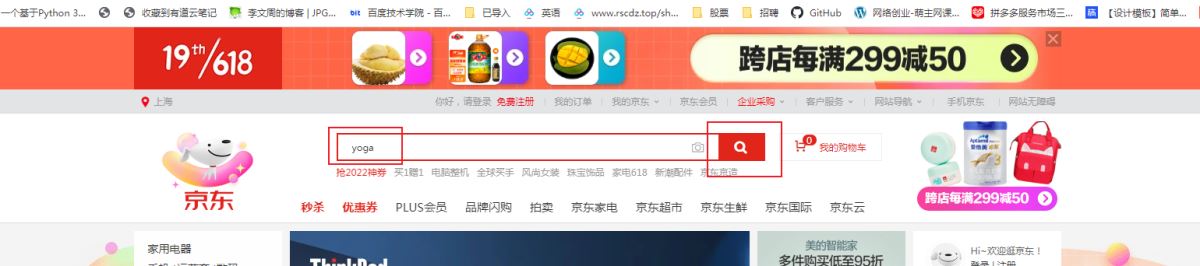
实例网站
京东

实例代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get(url="https://www.jd.com/")
# id
driver.find_element(by=By.ID,value="key").send_keys("yoga")
# css selector
driver.find_element(by=By.CSS_SELECTOR,value="#search > div > div.form > button").click()
time.sleep(3)
driver.quit()
结果展示
NAME、LINK_TEXT、PARTIAL_LINK_TEXT
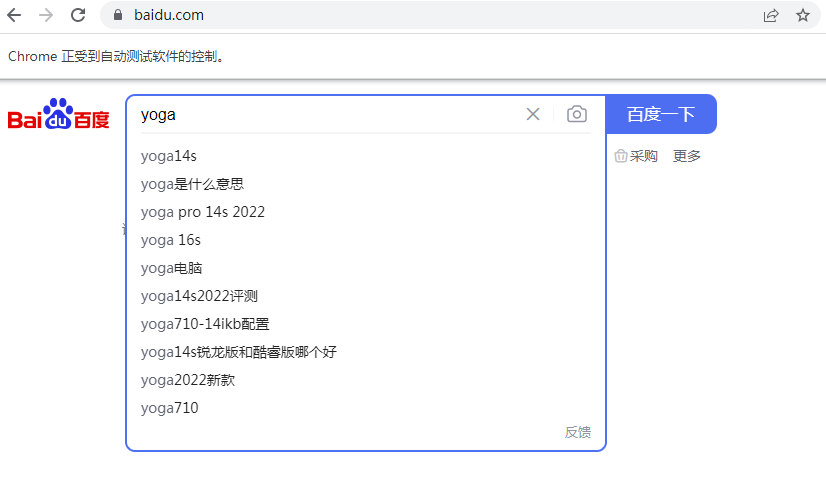
用NAME元素输入yoga,用LINK_TEXT定位how123,用PARTIAL_LINK_TEXT定位hao123

实例网站
可以自行百度
实例代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get(url="https://www.baidu.com/")
# id
driver.find_element(by=By.NAME,value="wd").send_keys("yoga")
time.sleep(3)
driver.get(url="https://www.baidu.com/")
# link text
driver.find_element(by=By.LINK_TEXT,value="hao123").click()
time.sleep(3)
# css selector
driver.get(url="https://www.baidu.com/")
driver.find_element(by=By.PARTIAL_LINK_TEXT,value="1").click()
time.sleep(3)
driver.quit()
结果展示
CSS、XPATH
点击热搜第一
实例网站
实例代码
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe") driver = webdriver.Chrome(service=service) driver.get(url="https://weibo.com/newlogin?tabtype=search&openLoginLayer=0&url=") time.sleep(6) # Redirect # css selector driver.find_element(by=By.CSS_SELECTOR,value="#scroller > div.vue-recycle-scroller__item-wrapper > div:nth-child(2) > div > div > a > div > div > div.woo-box-item-flex").click() time.sleep(3) # xpath driver.get(url="https://weibo.com/newlogin?tabtype=search&openLoginLayer=0&url=") time.sleep(6) driver.find_element(by=By.XPATH,value='//*[@id="scroller"]/div[1]/div[2]/div/div/a/div/div/div[1]').click() time.sleep(3) driver.quit()
结果展示
CSDN判定图片违规,无法上传
TAG_NAME、CLASS
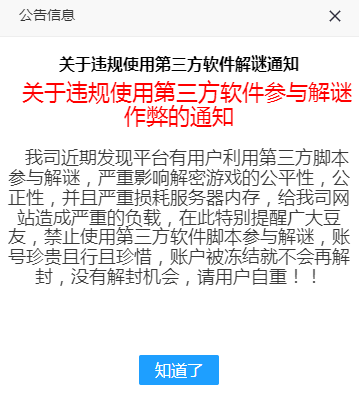
去除首页作弊通知弹窗
实例平台
实例代码
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe") driver = webdriver.Chrome(service=service) driver.get(url="http://doudouwan.com/") # tag name el = driver.find_elements(by=By.TAG_NAME,value="a")[83] # el2 = driver.find_elements(by=By.CLASS_NAME,value='layui-layer-btn0')[0] # for i in range(len(el)): # if el[i] == el2: # print(i) time.sleep(3) # delete all cookies in this website, and do not need to refresh driver driver.delete_all_cookies() # xpath driver.get(url="http://doudouwan.com/") time.sleep(6) driver.find_elements(by=By.CLASS_NAME,value='layui-layer-btn0')[0].click() time.sleep(3) driver.quit()
结果展示
到此这篇关于Selenium 4.2.0 标签定位8种方法的文章就介绍到这了,更多相关Selenium标签定位内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Selenium+BeautifulSoup+json获取Script标签内的json数据
Selenium爬虫遇到 数据是以 JSON 字符串的形式包裹在 Script 标签中, 假设Script标签下代码如下: <script id="DATA_INFO" type="application/json" > { "user": { "isLogin": true, "userInfo": { "id": 123456, "nickname":
-

Selenium处理select标签的下拉框
Selenium是一个开源的和便携式的自动化软件测试工具,用于测试Web应用程序有能力在不同的浏览器和操作系统运行.Selenium真的不是一个单一的工具,而是一套工具,帮助测试者更有效地基于Web的应用程序的自动化. 有时候我们会碰到<select></select>标签的下拉框.直接点击下拉框中的选项不一定可行.Selenium专门提供了Select类来处理下拉框. <select id="status" class="form-contro
-
Python+Selenium实现浏览器标签页的切换
目录 selenium 实现浏览器标签页句柄的切换 浏览器标签页本地文件准备 利用 selenium 实现浏览器页面的切换 在实际工作中,我们经常会遇到页面切换的情况.就比如当点击了某个功能的按钮后,浏览器出现了新的标签页,需要在这些标签页之间进行切换.要如何通过 selenium 来实现这样的场景呢?这就是我们今天要学习的内容. selenium 实现浏览器标签页句柄的切换 浏览器标签页本地文件准备 这一段纯粹是因为内容太少,拿来凑字数的... 同样的,这里所使用的是我们本地的 multi.h
-
python selenium 对浏览器标签页进行关闭和切换的方法
1.关闭浏览器全部标签页 driver.quit() 2.关闭当前标签页(从标签页A打开新的标签页B,关闭标签页A) driver.close() 3.关闭当前标签页(从标签页A打开新的标签页B,关闭标签页B) 可利用浏览器自带的快捷方式对打开的标签进行关闭 Firefox自身的快捷键分别为: Ctrl+t 新建tab Ctrl+w 关闭tab Ctrl+Tab /Ctrl+Page_Up 定位当前标签页的下一个标签页 Ctrl+Shift+Tab/Ctrl+Page_Down 定位当前标签页的
-
python selenium 获取标签的属性值、内容、状态方法
获取标签内容 使用element.attribute()方法获取dom元素的内容,如: dr = driver.find_element_by_id('tooltip') dr.get_attribute('data-original-title') #获取tooltip的内容 dr.text #获取该链接的text 获取标签属性 link=dr.find_element_by_id('tooltip') link.value_of_css_property('color') #获取toolti
-
Selenium 4.2.0 标签定位8种方法详解
目录 背景 元素定位 定位元素的方法 实例 测试目的 ID.CSS_SELECTOR NAME.LINK_TEXT.PARTIAL_LINK_TEXT CSS.XPATH TAG_NAME.CLASS 背景 Selenium4使用find_element(by=By.**, value=*)来替换了原来的find_element_by_* 的方法,使用find_elements(by=By.*, value=*)来替换了原来的find_elements_by_* 的方法. By类定义在 site
-
Mybatis 逆向工程的三种方法详解
Mybatis 逆向工程 逆向工程通常包括由数据库的表生成 Java 代码 和 通过 Java 代码生成数据库表.而Mybatis 逆向工程是指由数据库表生成 Java 代码. Mybaits 需要程序员自己编写 SQL 语句,但是 Mybatis 官方提供逆向工程可以针对单表自动生成 Mybaits 执行所需要的代码,包括 POJO.Mapper.java.Mapper.xml -. 一.通过 Eclipse 插件完成 Mybatis 逆向工程 1. 在线安装 Eclipse 插件
-
Java实现Excel转PDF的两种方法详解
目录 一.使用spire转化PDF 1.使用spire将整个Excel文件转为PDF 2.指定单个的sheet页转为PDF 二.使用jacob实现Excel转PDF(推荐使用) 1.环境准备 2.执行导出PDF 使用具将Excel转为PDF的方法有很多,在这里我给大家介绍两种常用的方法,分别应对两种不一样的使用场景,接下来我在springboot环境下给大家做一下演示! 一.使用spire转化PDF 首先介绍一种比较简单的方法,这种方法可以使用短短的几行代码就可以将我们的Excel文件中的某一个
-
使用Java构造和解析Json数据的两种方法(详解二)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面接着介绍用org.json构造和解析Json数据的方法
-
iOS Webview自适应实际内容高度的4种方法详解
//第一种方法 - (void)webViewDidFinishLoad:(UIWebView *)webView { CGFloat webViewHeight=[webView.scrollView contentSize].height; CGRect newFrame = webView.frame; newFrame.size.height = webViewHeight; webView.frame = newFrame; _webTablewView.contentSize = C
-
使用Java构造和解析Json数据的两种方法(详解一)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面首先介绍用json-lib构造和解析Json数据的方法
-
js表单元素checked、radio被选中的几种方法(详解)
0.环境 <input type="checkbox" value="lol"/>lol var lol = document.getElementsByTagName("input")[0]; 1.HTML DOM a.lol.checked = true; 属性的值可以不是lol,只要转为布尔值的时候为true就可以,取值时只有true.false两种 不会增加checked标记 b.lol.click(); 不会增加check
-
Python3日期与时间戳转换的几种方法详解
日期和时间的相互转换可以利用Python内置模块 time 和 datetime 完成,且有多种方法供我们选择,当然转换时我们可以直接利用当前时间或指定的字符串格式的时间格式. 获取当前时间转换 我们可以利用内置模块 datetime 获取当前时间,然后将其转换为对应的时间戳. import datetime import time # 获取当前时间 dtime = datetime.datetime.now() un_time = time.mktime(dtime.timetuple())
-
对Python获取屏幕截图的4种方法详解
Python获取电脑截图有多种方式,具体如下: PIL中的ImageGrab模块 windows API PyQt pyautogui PIL中的ImageGrab模块 import time import numpy as np from PIL import ImageGrab img = ImageGrab.grab(bbox=(100, 161, 1141, 610)) img = np.array(img.getdata(), np.uint8).reshape(img.size[1]
-
SpringBoot注入配置文件的3种方法详解
这篇文章主要介绍了SpringBoot注入配置文件的3种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 方案1:@ConfigurationProperties+@Component 定义spring的一个实体bean装载配置文件信息,其它要使用配置信息是注入该实体bean /** * 将配置文件中配置的每一个属性的值,映射到这个组件中 * @ConfigurationProperties:告诉SpringBoot将本类中的所有属性和配