理解zookeeper选举机制
zookeeper集群
配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。
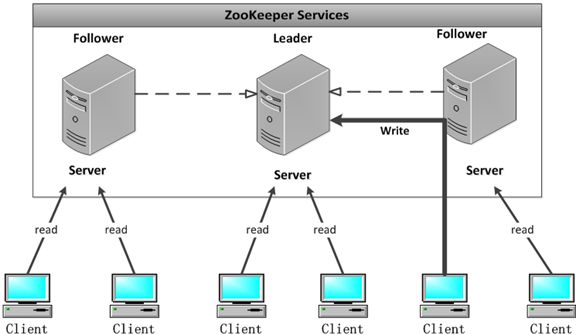
这篇主要分析leader的选择机制,zookeeper提供了三种方式:
- LeaderElection
- AuthFastLeaderElection
- FastLeaderElection
默认的算法是FastLeaderElection,所以这篇主要分析它的选举机制。
选择机制中的概念
服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
数据ID
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
逻辑时钟
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态。
选举消息内容
在投票完成后,需要将投票信息发送给集群中的所有服务器,它包含如下内容。
- 服务器ID
- 数据ID
- 逻辑时钟
- 选举状态
选举流程图
因为每个服务器都是独立的,在启动时均从初始状态开始参与选举,下面是简易流程图。

选举状态图
描述Leader选择过程中的状态变化,这是假设全部实例中均没有数据,假设服务器启动顺序分别为:A,B,C。

源码分析
QuorumPeer
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止。
public void run() {
//.......
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}
FastLeaderElection
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException {
//...
try {
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized(this){
//给自己投票
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//将投票信息发送给集群中的每个服务器
sendNotifications();
//循环,如果是竞选状态一直到选举出结果
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
//没有收到投票信息
if(n == null){
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
//...
}
//收到投票信息
else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) {
switch (n.state) {
case LOOKING:
// 判断投票是否过时,如果过时就清除之前已经接收到的信息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
//更新投票信息
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//发送投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid, proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
//忽略
break;
case FOLLOWING:
case LEADING:
//如果是同一轮投票
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if(termPredicate(recvset, new Vote(n.leader,
n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
//记录投票已经完成
outofelection.put(n.sid, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
if (termPredicate(outofelection, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, IGNOREVALUE)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
//忽略
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
} finally {
//...
}
}
判断是否已经胜出
默认是采用投票数大于半数则胜出的逻辑。
选举流程简述
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-
使用curator实现zookeeper锁服务的示例分享
复制代码 代码如下: import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.TimeUnit; import com.netflix.curator.RetryPolicy;import com.netflix.curator.framework.
-
Shell脚本实现自动安装zookeeper
A:本脚本运行的机器,Linux RHEL6 B,C,D,...:待安装zookeeper cluster的机器, Linux RHEL6 首先在脚本运行的机器A上确定可以ssh无密码登录到待安装zk的机器B,C,D,...上,然后就可以在A上运行本脚本: 复制代码 代码如下: $ ./install_zookeeper 前提: B, C, D机器必须配置好repo,本脚本使用的是cdh5的repo, 下面的内容保存到:/etc/yum.repos.d/cloudera-cdh5.repo: 复
-
apache zookeeper使用方法实例详解
本文涉及了Apache Zookeeper使用方法实例详解的相关知识,接下来我们就看看具体内容. 简介 Apache Zookeeper 是由 Apache Hadoop 的 Zookeeper 子项目发展而来,现在已经成为了 Apache 的顶级项目.Zookeeper 为分布式系统提供了高效可靠且易于使用的协同服务,它可以为分布式应用提供相当多的服务,诸如统一命名服务,配置管理,状态同步和组服务等. Zookeeper 接口简单,开发人员不必过多地纠结在分布式系统编程难于处理的同步和一致性问
-
源码阅读之storm操作zookeeper-cluster.clj
storm操作zookeeper的主要函数都定义在命名空间backtype.storm.cluster中(即cluster.clj文件中). backtype.storm.cluster定义了两个重要protocol:ClusterState和StormClusterState. clojure中的protocol可以看成java中的接口,封装了一组方法.ClusterState协议中封装了一组与zookeeper进行交互的基础函数,如获取子节点函数,获取子节点数据函数等,ClusterStat
-

理解zookeeper选举机制
zookeeper集群 配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的. 这篇主要分析leader的选择机制,zookeeper提供了三种方式: LeaderElection AuthFastLeaderElection FastLeaderElection 默认的算法是FastLeaderElection,所以这篇主要分析它的选举机制. 选择机制中的概
-
zookeeper watch机制的理解
首先我们看看为什么添加Watch. ZooKeeper是用来协调(同步)分布式进程的服务,提供了一个简单高性能的协调内核,用户可以在此之上构建更多复杂的分布式协调功能. 多个分布式进程通过ZooKeeper提供的 API来操作共享的ZooKeeper内存数据对象ZNode来达成某种一致的行为或结果,这种模式本质上是基于状态共享的并发模型,与Java的多线程并发模型一致,他们的线程或进程都是"共享式内存通信".Java没有直接提供某种响应式通知接口来监控某个对象状态的变化,只能要么浪费C
-
elasticsearch的灵魂唯一master选举机制原理分析
master作为cluster的灵魂必须要有,还必须要唯一,否则集群就出大问题了.因此master选举在cluster分析中尤为重要.对于这个问题我将分两篇来分析.第一篇也就是本篇,首先会简单说一说mater选举的一些算法,及elasticsearch的选举原理.第二篇也就是下一篇,会结合zenDiscovery代码为仔细分析elasticsearch的master选举的实现. 简单来说master的作用跟单个jvm中的同步关键字synchronized相同,集群中多节点协调工作必须要保证数据的
-
Android从源码的角度彻底理解事件分发机制的解析(下)
记得在前面的文章中,我带大家一起从源码的角度分析了Android中View的事件分发机制,相信阅读过的朋友对View的事件分发已经有比较深刻的理解了. 还未阅读过的朋友,请先参考Android从源码的角度彻底理解事件分发机制的解析. 那么今天我们将继续上次未完成的话题,从源码的角度分析ViewGroup的事件分发. 首先我们来探讨一下,什么是ViewGroup?它和普通的View有什么区别? 顾名思义,ViewGroup就是一组View的集合,它包含很多的子View和子VewGroup,是And
-
详解redis集群选举机制
概要 当redis集群的主节点故障时,Sentinel集群将从剩余的从节点中选举一个新的主节点,有以下步骤: 故障节点主观下线 故障节点客观下线 Sentinel集群选举Leader Sentinel Leader决定新主节点 选举过程 1.主观下线 Sentinel集群的每一个Sentinel节点会定时对redis集群的所有节点发心跳包检测节点是否正常.如果一个节点在down-after-milliseconds时间内没有回复Sentinel节点的心跳包,则该redis节点被该Sentinel
-
一文理解Python命名机制
目录 1.初探 2.迷踪 3.探究 4.真相 猜测下面这段程序的输出: class A(object): def __init__(self): self.__private() self.public() def __private(self): print 'A.__private()' def public(self): print 'A.public()' class B(A): def __private(self): print 'B.__private()' def public(
-
elasticsearch的zenDiscovery和master选举机制原理分析
目录 前言 join的代码 findMaster方法 总结 前言 上一篇通过 ElectMasterService源码,分析了master选举的原理的大部分内容:master候选节点ID排序保证选举一致性及通过设置最小可见候选节点数目避免brain split.节点排序后选举只能保证局部一致性,如果发生节点接收到了错误的集群状态就会选举出错误的master,因此必须有其它措施来保证选举的一致性.这就是上一篇所提到的第二点:被选举的数量达到一定的数目同时自己也选举自己,这个节点才能成为master
-
深入理解java异常处理机制及应用
1. 引子 try-catch-finally恐怕是大家再熟悉不过的语句了,而且感觉用起来也是很简单,逻辑上似乎也是很容易理解.不过,我亲自体验的"教训"告诉我,这个东西可不是想象中的那么简单.听话.不信?那你看看下面的代码,"猜猜"它执行后的结果会是什么?不要往后看答案.也不许执行代码看真正答案哦.如果你的答案是正确,那么这篇文章你就不用浪费时间看啦. package Test; public class TestException { public TestEx
-
深入理解java异常处理机制的原理和开发应用
Java异常处理机制其最主要的几个关键字:try.catch.finally.throw.throws,以及各种各样的Exception.本篇文章主要在基础的使用方法上,介绍了如何更加合理的使用异常机制. try-catch-finally try-catch-finally块的用法比较简单,使用频次也最高.try块中包含可能出现异常的语句(当然这是人为决定的,try理论上可以包含任何代码),catch块负责捕获可能出现的异常,finally负责执行必须执行的语句,这里的代码不论是否发生了异常,
-
理解js回收机制通俗易懂版
之前文章中,讲解过js中的回收机制,但是对于当时的我来说,我自己对回收机制的这个概念也有些懵懵懂懂,现在对回收机制有了更深入的理解,所以特此发布此文给于总结,也好加深记忆. 为什么要有回收机制?why? 打个比方,我有一个内存卡,这个内存是8G的,我把文件,视频,音乐,都保存到了这个内存卡,随着我的储存的内容越来越多,这个内存卡已经保存不了了,如果我还想再把其他的文件保存到这个内存卡就需要删除一些文件,但是这些被删除的文件是我们自己手动删除的对吧,手动删除就相当于js中的delete. 在这些程