用C#做网络爬虫的步骤教学
如今代码圈很多做网络爬虫的例子,今天小编给大家分享的是如何用C#做网络爬虫。注意这次的分享只是分享思路,并不是一整个例子,因为如果要讲解一整个例子的话,牵扯的东西太多。
1、新建一个控制台程序,这个相信大家都懂的
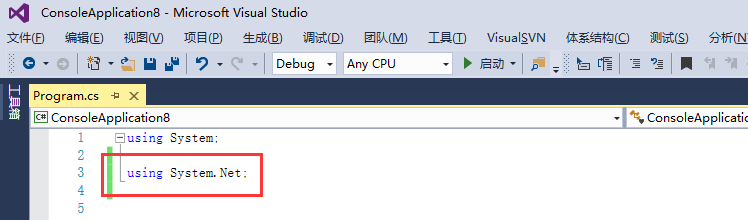
2、建好以后,打开主程序文件,导入发送http请求的库,这里用的是System.NET
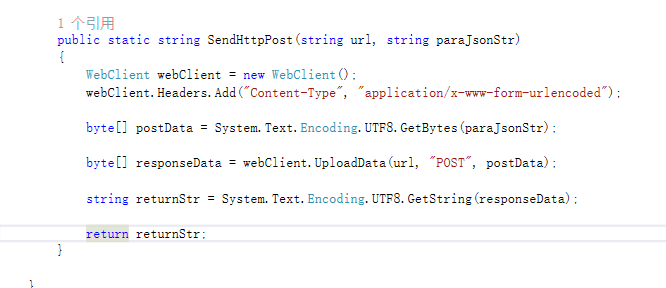
3、编写发送http请求的方法,如下所示:首先实例化WebClient,然后设置头信息,其次转化参数为字节数据,最后调用UploadData方法进行发送。
4、接下来调用我们写的发送http请求的方法,我们这里模拟打开如下的地址

5、运行后我们看返回结果,你会感觉非常的熟悉,没错,返回的就是html文本

6、
下面的操作我想你应该明白了吧,接下来就是分析网页结构,截取你需要的信息,这个可以在后台操作,也可以传到前台用jquery进行操作
下面的操作我想你应该明白了吧,接下来就是分析网页结构,截取你需要的信息,这个可以在后台操作,也可以传到前台用jquery进行操作
7、
总结一下,网络爬虫的思路其实主要就分为:分析网页结构,确认所需要内容的位置,获取网页,最后提取内容,你学会了吗?感谢大家对我们的支持。
相关推荐
-

深入理解Python分布式爬虫原理
首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作者,摘要,正文等信息 (3)存储到硬盘中 上面的三个过程,映射到技术层面上,其实就是:网络请求,抓取结构化数据,数据存储. 我们使用Python写一个简单的程序,实现上面的简单抓取功能. #!/usr/bin/python #-*- coding: utf-8 -*- ''''' Created on 2014-03-16 @author: Kris '
-
Python数据抓取爬虫代理防封IP方法
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法使用代理的IP的,我就来分享一下Python爬虫怎样使用代理IP的经验.(推荐飞猪代理IP注册可免费使用,浏览器搜索可找到) 1.划重点,小编我用的是Python3哦,所以要导入urllib的request,然后我们调用ProxyHandler,它可以接收代理IP的参数.代理可以根据自己需要选择,当然免费的也是有
-
使用Docker Swarm搭建分布式爬虫集群的方法示例
在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况.此时你是怎么操作的呢?逐一SSH登录每个服务器,使用git拉下代码,然后运行?代码修改了,于是又要一个服务器一个服务器登录上去依次更新? 有时候爬虫只需要在一个服务器上面运行,有时候需要在200个服务器上面运行.你是怎么快速切换的呢?一个服务器一个服务器登录上去开关?或者聪明一点,在Redis里面设置一个可以修改的标记,只有标记对应的服务器上面的爬虫运行? A爬虫已经在所有服务器上面部署了,现在又做了一个B爬虫,你是不是又得依次
-
python爬虫获取小区经纬度以及结构化地址
本文实例为大家分享了python爬虫获取小区经纬度.地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然后再利用经纬度Reverse到小区的结构化的地址.另外小区名称如果是'...号',可以在爬虫开始之前在'号'之后加一个'院',得到的精确度更高.这次写到程序更加便于二次利用,只需要给程序传递一个dataframe就可以坐等结果了.现在程序已经写好了,就
-
Scrapy-redis爬虫分布式爬取的分析和实现
Scrapy Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来. 而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件.它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用.scrapy-redi
-
Python3爬虫全国地址信息
PHP方式写的一团糟所以就用python3重写了一遍,所以因为第二次写了,思路也更清晰了些. 提醒:可能会有502的错误,所以做了异常以及数据库事务处理,暂时没有想到更好的优化方法,所以就先这样吧.待更懂python再进一步优化哈 欢迎留言赐教~ #!C:\Users\12550\AppData\Local\Programs\Python\Python37\python.exe # -*- coding: utf-8 -*- from urllib.request import urlopen
-
爬虫技术之分布式爬虫架构的讲解
分布式爬虫架构并不是一开始就出现的.而是一个逐步演化的过程. 最开始入手写爬虫的时候,我们一般在个人计算机上完成爬虫的入门和开发,而在真实的生产环境,就不能用个人计算机来运行爬虫程序了,而是将爬虫程序部署在服务器上.利用服务器不关机的特性,爬虫可以不间断的24小时运行.单机爬虫的结构如下图. 然而,由于爬虫在爬取数据时,爬取频次并不能太快,即使是爬虫在服务器上不间断运行,效率可能也无法满足实际需求.这时候,就需要在多机上部署爬虫程序,用分布式爬虫架构,进行数据爬取.分布式爬虫的架构一般如下所示.
-
分布式爬虫处理Redis里的数据操作步骤
存入MongoDB 1.启动MongoDB数据库:sudo mongod 2.执行下面程序:py2 process_youyuan_mongodb.py # process_youyuan_mongodb.py # -*- coding: utf-8 -*- import json import redis import pymongo def main(): # 指定Redis数据库信息 rediscli = redis.StrictRedis(host='192.168.199.108',
-
PHP一个简单的无需刷新爬虫
由于只是一个小示例,所以过程化简单写了,小菜随便参考,大神大可点解 <?php //设置最大执行时间 set_time_limit(0); function getHtml($url){ // 1. 初始化 $ch = curl_init(); // 2. 设置选项,包括URL curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_setopt($ch,CURLOPT_HEADER,0
-
Python 用Redis简单实现分布式爬虫的方法
Redis通常被认为是一种持久化的存储器关键字-值型存储,可以用于几台机子之间的数据共享平台. 连接数据库 注意:假设现有几台在同一局域网内的机器分别为Master和几个Slaver Master连接时host为localhost即本机的ip _db = redis.Reds(host='localhost', port=6379, db=0) Slaver连接时的host也为Master的ip,端口port和数据库db不写时为默认值6379.0 _db = redis.Redis(host='