pycharm下打开、执行并调试scrapy爬虫程序的方法
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:scrapy startproject test1
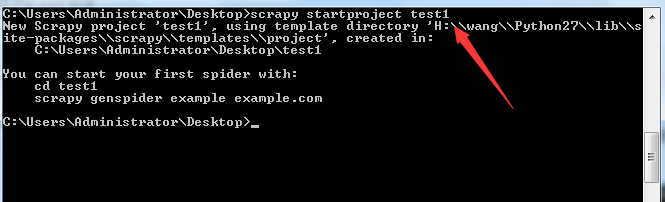
目录结构如下:

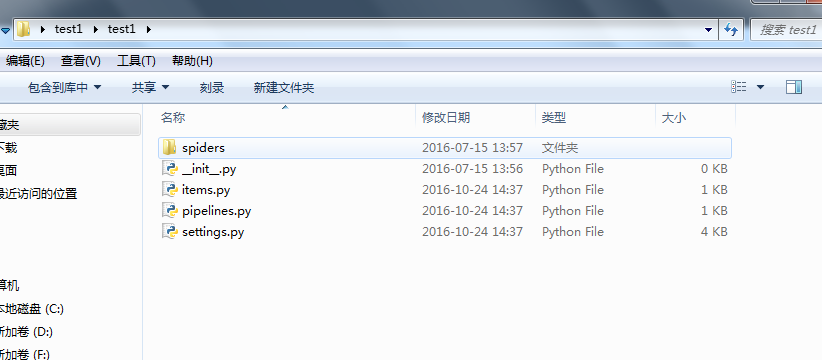
打开Pycharm,选择open

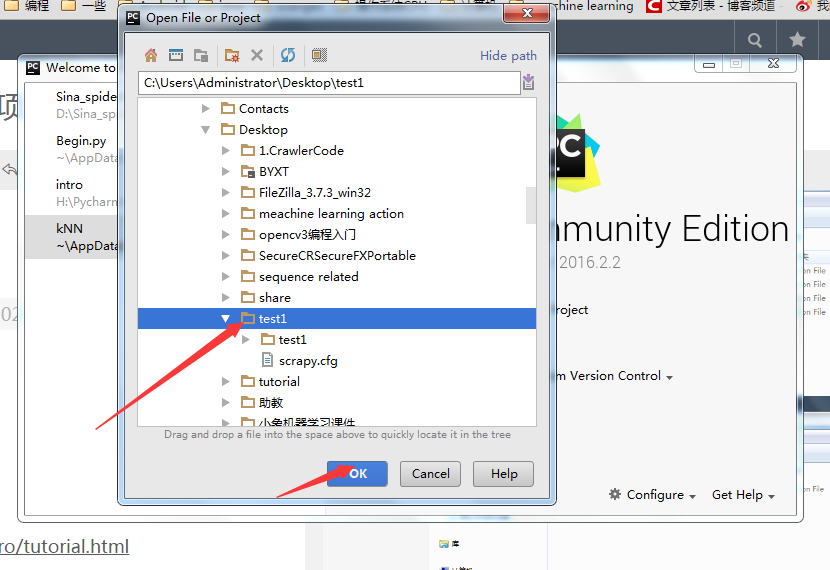
选择项目,ok
打开如下界面之后,按alt + 1, 打开project 面板


在test1/spiders/,文件夹下,新建一个爬虫spider.py, 注意代码中的name="dmoz"。这个名字后面会用到。
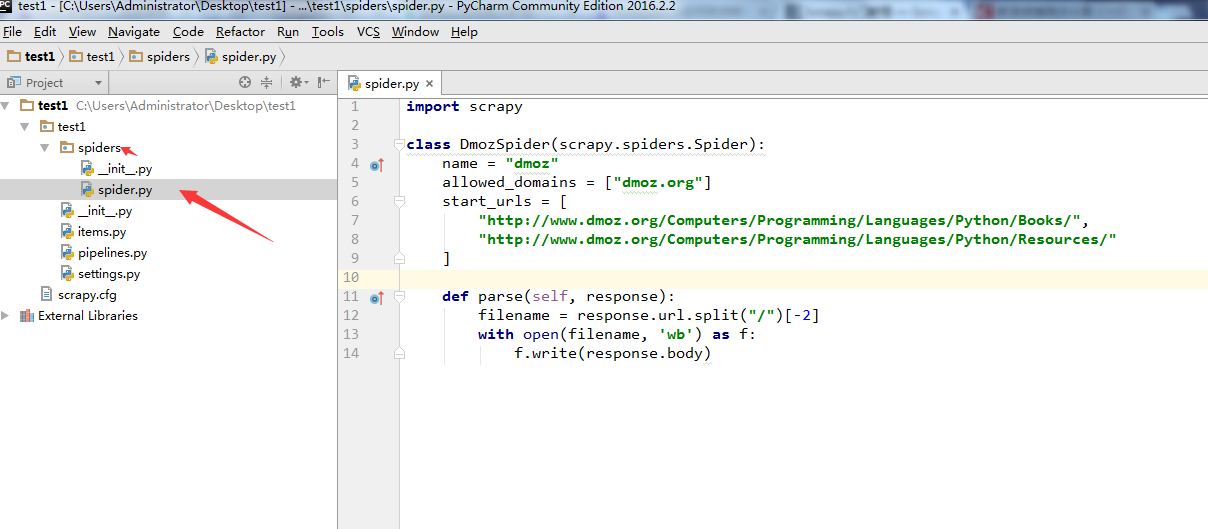
在test1目录和scrapy.cfg同级目录下面,新建一个begin.py文件(便于理解可以写成main.py),注意箭头2所指的名字和第5步中的name='dmoz'名字是一样的。
from scrapy import cmdline
cmdline.execute("scrapy crawl dmoz".split())
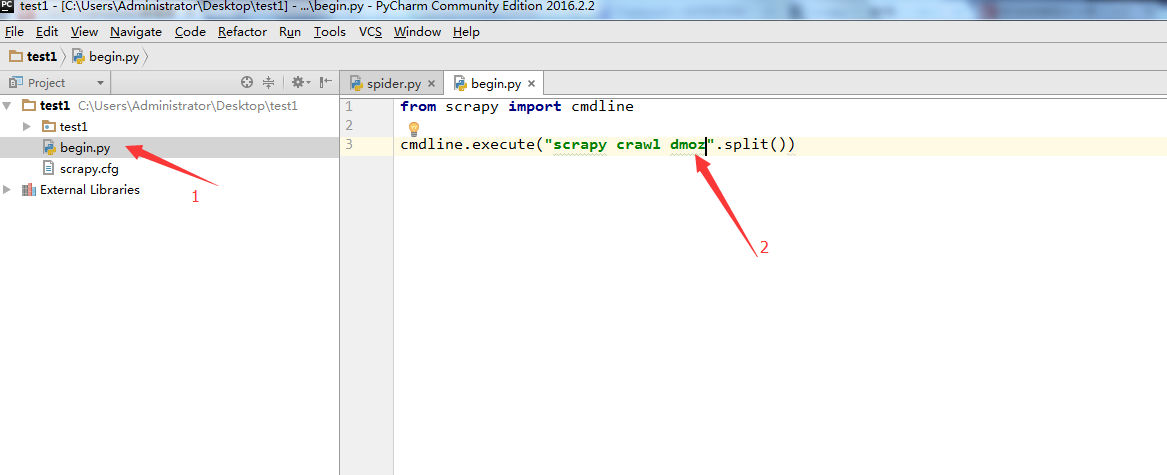
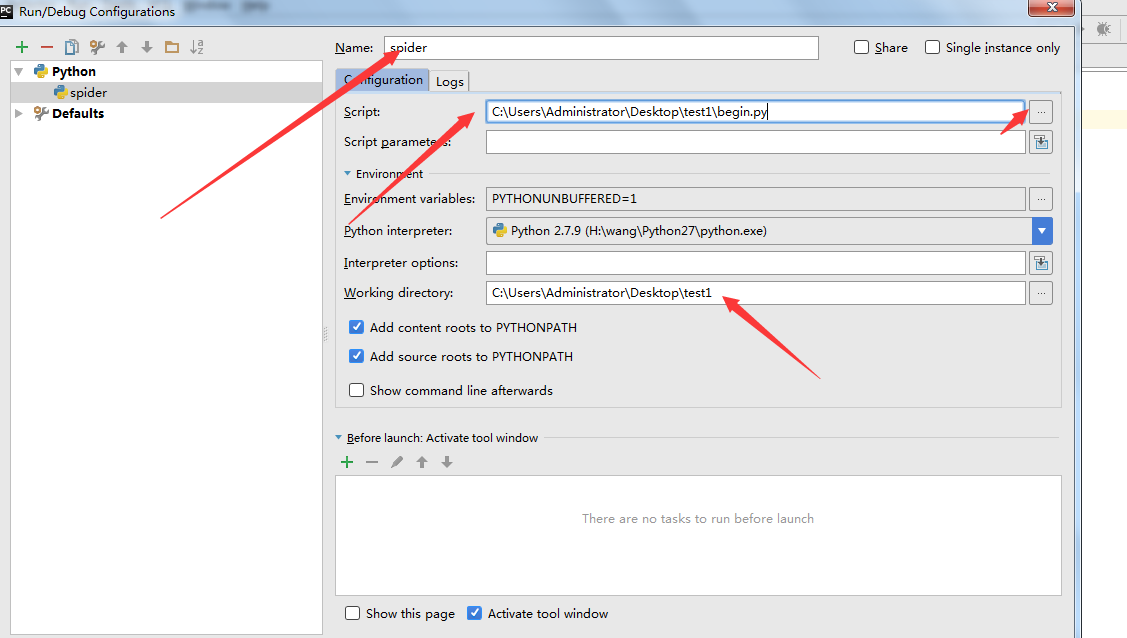
7. 上面把文件搞定了,下面要配置一下pycharm了。点击Run->Edit Configurations
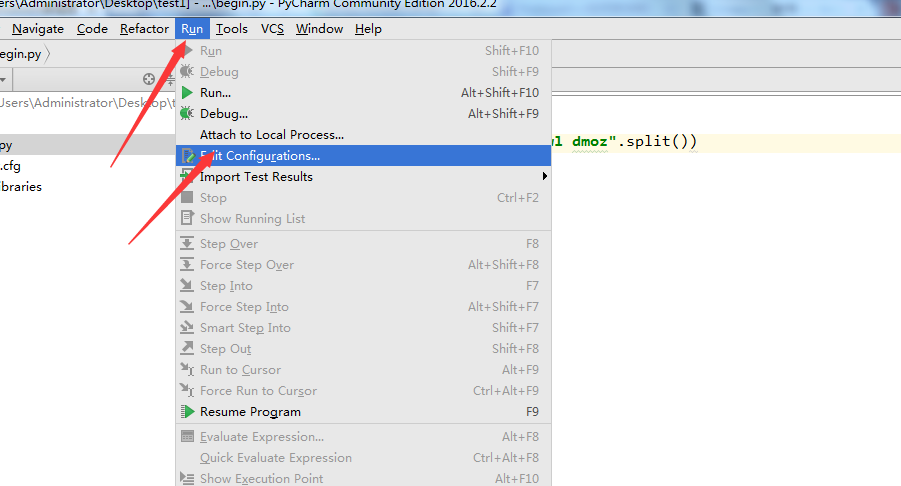
8. 新建一个运行的python模块
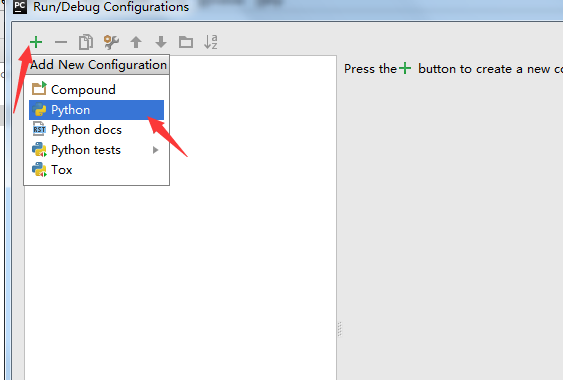
9. Name:改成spider; script:选择刚才新建的那个begin.py文件;Working Direciton:改成自己的工作目录
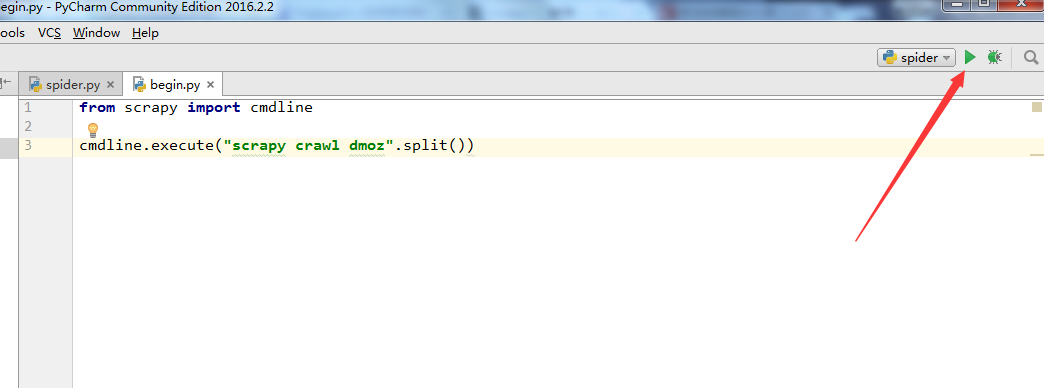
10. 至此,大功告成了,点击下图,右上角的按钮就能运行了。
调试
可以在其他代码中设置断点,就可以debug运行
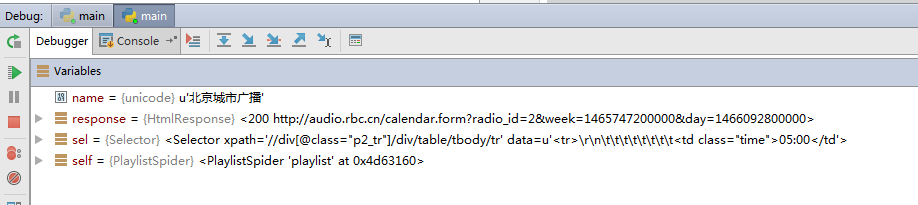
遇到问题
1. Unknown command: crawl
调试运行,断点并未命中,控制台输出信息如下:
H:\Python\Python36\python.exe "H:\Program Files (x86)\JetBrains\PyCharm Community Edition 4.5.4\helpers\pydev\pydevd.py" --multiproc --client 127.0.0.1 --port 59810 --file H:/Python/Python36/Lib/site-packages/scrapy/cmdline.py crawl quotes -o quotes.jl pydev debugger: process 4740 is connecting Connected to pydev debugger (build 141.3058) Scrapy 1.3.2 - no active project Unknown command: crawl Use "scrapy" to see available commands Process finished with exit code 2
工作目录设置有误,造成无法识别 scrapy 命令,按照上文所说,将工作目录设置为包含 scrapy.cfg,重新运行,问题解决。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
复制代码 代码如下: #!/usr/bin/env python# -*- coding: utf-8 -*- from scrapy.contrib.spiders import CrawlSpider, Rulefrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom scrapy.selector import Selector from cnbeta.items import CnbetaItemclass
-

深入剖析Python的爬虫框架Scrapy的结构与运作流程
网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人.当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个"机器人"其实也就是一段程序,并且它也不是乱爬,而是有一定目的的,并且在爬行的时候会搜集一些信息.例如 Google 就有一大堆爬虫会在 Internet 上搜集网页内容以及它们之间的链接等信息:又比如一些别有用心的爬虫会在 Internet 上搜集诸如 foo@bar.com 或者 foo [at] bar [dot] com 之类的东
-
实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7).官方文档中介绍了三种方法进行安装,我采用的是使用 easy_install 进行安装,首先是下载Windows版本的setuptools(下载地址:http://pypi.python.org/pypi/setuptools),下载完后一路NEXT就可以了. 安装完setuptool以后.执行CMD,然后运行一下命令: easy_i
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-
Python的Scrapy爬虫框架简单学习笔记
一.简单配置,获取单个网页上的内容. (1)创建scrapy项目 scrapy startproject getblog (2)编辑 items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy.item import
-
使用Python的Scrapy框架编写web爬虫的简单示例
在这个教材中,我们假定你已经安装了Scrapy.假如你没有安装,你可以参考这个安装指南. 我们将会用开放目录项目(dmoz)作为我们例子去抓取. 这个教材将会带你走过下面这几个方面: 创造一个新的Scrapy项目 定义您将提取的Item 编写一个蜘蛛去抓取网站并提取Items. 编写一个Item Pipeline用来存储提出出来的Items Scrapy由Python写成.假如你刚刚接触Python这门语言,你可能想要了解这门语言起,怎么最好的利用这门语言.假如你已经熟悉其它类似的语言,想要快速
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
pycharm下打开、执行并调试scrapy爬虫程序的方法
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:scrapy startproject test1 目录结构如下: 打开Pycharm,选择open 选择项目,ok 打开如下界面之后,按alt + 1, 打开project 面板 在test1/spiders/,文件夹下,新建一个爬虫spider.py, 注意代码中的name="dmoz".这个名字后面会用到. 在test1目录和scrapy.cfg同级目
-
Windows下CMD执行Go出现中文乱码的解决方法
在cmd下运行go程序或者是GOLAND的Terminal下运行go程序会出现中文乱码的情况. go run ttypemain.go ���� Ping [127.0.0.1] ���� 32 �ֽڵ�����:���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128���� 127.
-
使用VSCode开发和调试.NET Core程序的方法
电脑不想装几十个G的 VS2017,那就用 VS Code 吧 目标: 创建一个类库项目 Skany.Core,并用 Nuget 引用第三方组件 Hash 实现加密算法 创建一个单元测试项目 Skany.Tests,引用类库 Skany.Core,并测试其中的方法 创建一个控制台应用程序项目 Skany.Output,引用类库 Skany.Core,并输出方法执行结果 创建一个解决方案 Skany.sln,包括以上三项目 环境 .NET Core SDK 2.2.202 开始 首先在 VS Co
-
python网络爬虫之如何伪装逃过反爬虫程序的方法
有的时候,我们本来写得好好的爬虫代码,之前还运行得Ok, 一下子突然报错了. 报错信息如下: Http 800 Internal internet error 这是因为你的对象网站设置了反爬虫程序,如果用现有的爬虫代码,会被拒绝. 之前正常的爬虫代码如下: from urllib.request import urlopen ... html = urlopen(scrapeUrl) bsObj = BeautifulSoup(html.read(), "html.parser") 这
-
python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
解决pycharm下os.system执行命令返回有中文乱码的问题
如下所示: source = ['C:\\Users\\admin\\Desktop\\pythonLearning'] target_dir = 'C:\\Users\\admin\\Desktop' print(time.strftime('%Y%m%d%H%M%S')) target = target_dir + os.sep + time.strftime('%Y%m%d%H%M%S') + '.zip' if not os.path.exists(target_dir): os.mkd
-
windows下搭建python scrapy爬虫框架步骤
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windows下搭建scrapy框架,官方文档是建议使用集成包的,以免安装太过复杂而出现问题,首先百度scrapy,就可以找到scrapy的官方文档 1.找到windows下的框架安装的文档教程,这里建议我们安装Anaconda或者Miniconda集成包,下面我选择安装Miniconda安装包来安装scrapy框架 2.
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
详解python3 + Scrapy爬虫学习之创建项目
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个scrapy项目 请确保已经安装了scrapy,twisted,pypiwin32 一:进入你所需要的路径,这个路径存储你创建的项目 我的将放在E盘的Scrapy目录下 二:创建项目:scrapy startproject ***(这个是项目名) 这样就创建好了一个名为tencent的项目 三:进入项目新建一个爬虫:
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将