对Pytorch神经网络初始化kaiming分布详解
函数的增益值
torch.nn.init.calculate_gain(nonlinearity, param=None)
提供了对非线性函数增益值的计算。
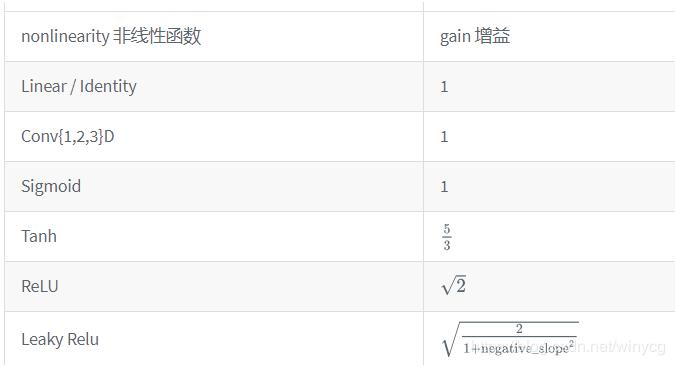
增益值gain是一个比例值,来调控输入数量级和输出数量级之间的关系。
fan_in和fan_out
pytorch计算fan_in和fan_out的源码
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.ndimension()
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed
for tensor with fewer than 2 dimensions")
if dimensions == 2: # Linear
fan_in = tensor.size(1)
fan_out = tensor.size(0)
else:
num_input_fmaps = tensor.size(1)
num_output_fmaps = tensor.size(0)
receptive_field_size = 1
if tensor.dim() > 2:
receptive_field_size = tensor[0][0].numel()
fan_in = num_input_fmaps * receptive_field_size
fan_out = num_output_fmaps * receptive_field_size
return fan_in, fan_out

xavier分布
xavier分布解析:https://prateekvjoshi.com/2016/03/29/understanding-xavier-initialization-in-deep-neural-networks/
假设使用的是sigmoid函数。当权重值(值指的是绝对值)过小,输入值每经过网络层,方差都会减少,每一层的加权和很小,在sigmoid函数0附件的区域相当于线性函数,失去了DNN的非线性性。
当权重的值过大,输入值经过每一层后方差会迅速上升,每层的输出值将会很大,此时每层的梯度将会趋近于0.
xavier初始化可以使得输入值x x x<math><semantics><mrow><mi>x</mi></mrow><annotation encoding="application/x-tex">x</annotation></semantics></math>x方差经过网络层后的输出值y y y<math><semantics><mrow><mi>y</mi></mrow><annotation encoding="application/x-tex">y</annotation></semantics></math>y方差不变。
(1)xavier的均匀分布
torch.nn.init.xavier_uniform_(tensor, gain=1)
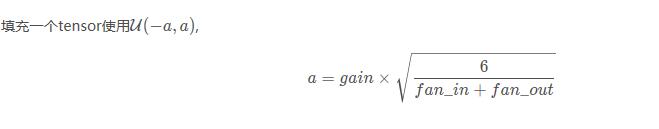
也称为Glorot initialization。
>>> w = torch.empty(3, 5)
>>> nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
(2) xavier正态分布
torch.nn.init.xavier_normal_(tensor, gain=1)
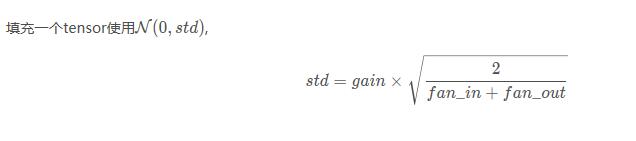
也称为Glorot initialization。
kaiming分布
Xavier在tanh中表现的很好,但在Relu激活函数中表现的很差,所何凯明提出了针对于relu的初始化方法。pytorch默认使用kaiming正态分布初始化卷积层参数。
(1) kaiming均匀分布
torch.nn.init.kaiming_uniform_ (tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')

也被称为 He initialization。
a – the negative slope of the rectifier used after this layer (0 for ReLU by default).激活函数的负斜率,
mode – either ‘fan_in' (default) or ‘fan_out'. Choosing fan_in preserves the magnitude of the variance of the weights in the forward pass. Choosing fan_out preserves the magnitudes in the backwards
pass.默认为fan_in模式,fan_in可以保持前向传播的权重方差的数量级,fan_out可以保持反向传播的权重方差的数量级。
>>> w = torch.empty(3, 5) >>> nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu')
(2) kaiming正态分布
torch.nn.init.kaiming_normal_ (tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
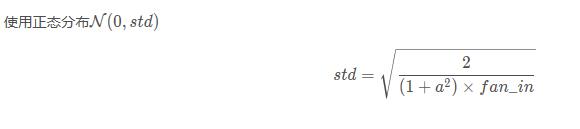
也被称为 He initialization。
>>> w = torch.empty(3, 5) >>> nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu')
以上这篇对Pytorch神经网络初始化kaiming分布详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
PyTorch上搭建简单神经网络实现回归和分类的示例
本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一.PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可得到Linux下conda指令: conda install pytorch torchvision -c soumith 目前PyTorch仅支持MacOS和Linux,暂不支持Windows.安装 PyTorch 会安装两个模块,一个是torch,一个 torch
-
PyTorch上实现卷积神经网络CNN的方法
一.卷积神经网络 卷积神经网络(ConvolutionalNeuralNetwork,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此CNN在
-

python PyTorch参数初始化和Finetune
前言 这篇文章算是论坛PyTorch Forums关于参数初始化和finetune的总结,也是我在写代码中用的算是"最佳实践"吧.最后希望大家没事多逛逛论坛,有很多高质量的回答. 参数初始化 参数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了data,grad等借口,这就意味着我们可以直接对这些参数进行操作赋值了.这就是PyTorch简洁高效所在. 所以我们可以进行如下操作进行初始化,当然其实有其他的方法,但是这种方法
-
pytorch自定义初始化权重的方法
在常见的pytorch代码中,我们见到的初始化方式都是调用init类对每层所有参数进行初始化.但是,有时我们有些特殊需求,比如用某一层的权重取优化其它层,或者手动指定某些权重的初始值. 核心思想就是构造和该层权重同一尺寸的矩阵去对该层权重赋值.但是,值得注意的是,pytorch中各层权重的数据类型是nn.Parameter,而不是Tensor或者Variable. import torch import torch.nn as nn import torch.optim as optim imp
-
PyTorch快速搭建神经网络及其保存提取方法详解
有时候我们训练了一个模型, 希望保存它下次直接使用,不需要下次再花时间去训练 ,本节我们来讲解一下PyTorch快速搭建神经网络及其保存提取方法详解 一.PyTorch快速搭建神经网络方法 先看实验代码: import torch import torch.nn.functional as F # 方法1,通过定义一个Net类来建立神经网络 class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output):
-
pytorch神经网络之卷积层与全连接层参数的设置方法
当使用pytorch写网络结构的时候,本人发现在卷积层与第一个全连接层的全连接层的input_features不知道该写多少?一开始本人的做法是对着pytorch官网的公式推,但是总是算错. 后来发现,写完卷积层后可以根据模拟神经网络的前向传播得出这个. 全连接层的input_features是多少.首先来看一下这个简单的网络.这个卷积的Sequential本人就不再啰嗦了,现在看nn.Linear(???, 4096)这个全连接层的第一个参数该为多少呢? 请看下文详解. class AlexN
-
PyTorch的深度学习入门教程之构建神经网络
前言 本文参考PyTorch官网的教程,分为五个基本模块来介绍PyTorch.为了避免文章过长,这五个模块分别在五篇博文中介绍. Part3:使用PyTorch构建一个神经网络 神经网络可以使用touch.nn来构建.nn依赖于autograd来定义模型,并且对其求导.一个nn.Module包含网络的层(layers),同时forward(input)可以返回output. 这是一个简单的前馈网络.它接受输入,然后一层一层向前传播,最后输出一个结果. 训练神经网络的典型步骤如下: (1) 定义
-
对Pytorch神经网络初始化kaiming分布详解
函数的增益值 torch.nn.init.calculate_gain(nonlinearity, param=None) 提供了对非线性函数增益值的计算. 增益值gain是一个比例值,来调控输入数量级和输出数量级之间的关系. fan_in和fan_out pytorch计算fan_in和fan_out的源码 def _calculate_fan_in_and_fan_out(tensor): dimensions = tensor.ndimension() if dimensions < 2:
-
Python深度学习pytorch神经网络图像卷积运算详解
目录 互相关运算 卷积层 特征映射 由于卷积神经网络的设计是用于探索图像数据,本节我们将以图像为例. 互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算.在卷积层中,输入张量和核张量通过互相关运算产生输出张量. 首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示.下图中,输入是高度为3.宽度为3的二维张量(即形状为 3 × 3 3\times3 3×3).卷积核的高度和宽度都是2. 注意,
-
TensorFlow卷积神经网络AlexNet实现示例详解
2012年,Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本.AlexNet以显著的优势赢得了竞争激烈的ILSVRC 2012比赛,top-5的错误率降低至了16.4%,远远领先第二名的26.2%的成绩.AlexNet的出现意义非常重大,它证明了CNN在复杂模型下的有效性,而且使用GPU使得训练在可接受的时间范围内得到结果,让CNN和GPU都大火了一把.AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深
-
基于Pytorch实现分类器的示例详解
目录 Softmax分类器 定义 训练 测试 感知机分类器 定义 训练 测试 本文实现两个分类器: softmax分类器和感知机分类器 Softmax分类器 Softmax分类是一种常用的多类别分类算法,它可以将输入数据映射到一个概率分布上.Softmax分类首先将输入数据通过线性变换得到一个向量,然后将向量中的每个元素进行指数函数运算,最后将指数运算结果归一化得到一个概率分布.这个概率分布可以被解释为每个类别的概率估计. 定义 定义一个softmax分类器类: class SoftmaxCla
-
C++对象内存分布详解(包括字节对齐和虚函数表)
1.C++对象的内存分布和虚函数表: C++对象的内存分布和虚函数表注意,对象中保存的是虚函数表指针,而不是虚函数表,虚函数表在编译阶段就已经生成,同类的不同对象中的虚函数指针指向同一个虚函数表,不同类对象的虚函数指针指向不同虚函数表. 2.何时进行动态绑定: (1)每个类对象在被构造时不用去关心是否有其他类从自己派生,也不需要关心自己是否从其他类派生,只要按照一个统一的流程:在自身的构造函数执行之前把自己所属类(即当前构造函数所属的类)的虚函数表的地址绑定到当前对象上(一般是保存在对象内存空间
-
基于pytorch的lstm参数使用详解
lstm(*input, **kwargs) 将多层长短时记忆(LSTM)神经网络应用于输入序列. 参数: input_size:输入'x'中预期特性的数量 hidden_size:隐藏状态'h'中的特性数量 num_layers:循环层的数量.例如,设置' ' num_layers=2 ' '意味着将两个LSTM堆叠在一起,形成一个'堆叠的LSTM ',第二个LSTM接收第一个LSTM的输出并计算最终结果.默认值:1 bias:如果' False',则该层不使用偏置权重' b_ih '和' b
-
PyTorch安装与基本使用详解
什么要学习PyTorch? 有的人总是选择,选择的人最多的框架,来作为自己的初学框架,比如Tensorflow,但是大多论文的实现都是基于PyTorch的,如果我们要深入论文的细节,就必须选择学习入门PyTorch 安装PyTorch 一行命令即可 官网 pip install torch===1.6.0 torchvision===0.7.0 - https://download.pytorch.org/whl/torch_stable.html 时间较久,耐心等待 测试自己是否安装成功 运行
-
人工智能学习Pytorch教程Tensor基本操作示例详解
目录 一.tensor的创建 1.使用tensor 2.使用Tensor 3.随机初始化 4.其他数据生成 ①torch.full ②torch.arange ③linspace和logspace ④ones, zeros, eye ⑤torch.randperm 二.tensor的索引与切片 1.索引与切片使用方法 ①index_select ②... ③mask 三.tensor维度的变换 1.维度变换 ①torch.view ②squeeze/unsqueeze ③expand,repea
-
人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式