python实现TF-IDF算法解析
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。
同样,理论我这里不再赘述,因为和阮一峰大神早在2013年就将TF-IDF用一种非常通俗的方式讲解出来
TF-IDF与余弦相似性的应用(一):自动提取关键词
材料
1.语料库(已分好词)
2.停用词表(哈工大停用词表)
3.python3.5
语料库的准备
这里使用的语料库是《人民日报》2015年1月16日至1月18日的发表的新闻。并且在进行TFIDF处理之前已经进行了人工分词(当然也可以使用jieba分词,但效果不好)
三天的新闻篇章数量如下:
语料库中共103篇新闻。每篇新闻存入在txt文件中,编码为UTF-8无BOM
这里放一篇文章示例下:

我在自己的项目路径下新建一个corpus的文件夹,用于存放已经分好词待计算的语料。corpus文件夹的架构如下:
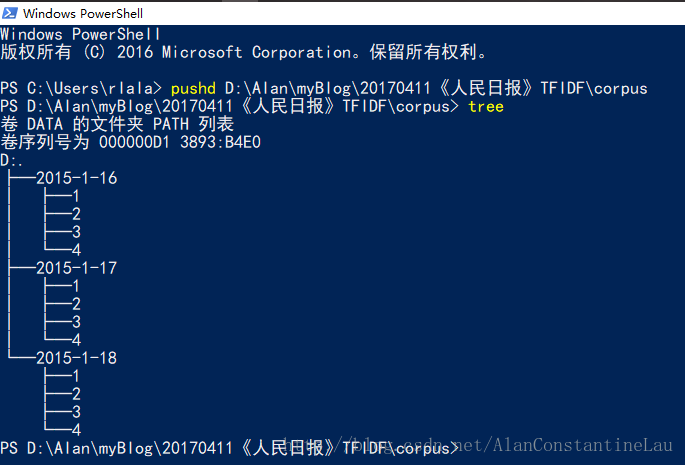
2015年1月16日至1月18日共三天,每天可获取的新闻分了四版,因此针对每一天下的每一版我又分别建了编号为1、2、3、4的文件夹,用于存放每一版的新闻。
其实也没必要这么麻烦,可以直接把所有的新闻都放到一个文件夹下,只是我个人的文件管理习惯。当然放到数据库里面更好。
关于停用词表
较好用的停用词表有哈工大停用词表、百度停用词表、川大停用词表,网上一查一大堆。我这里选择的是哈工大停用词表。
代码实现
# -*- coding: utf-8 -*-
# @Date : 2017-04-11 09:31:55
# @Author : Alan Lau (rlalan@outlook.com)
# @Language : Python3.5
import os
import codecs
import math
import operator
def fun(filepath): # 遍历文件夹中的所有文件,返回文件list
arr = []
for root, dirs, files in os.walk(filepath):
for fn in files:
arr.append(root+"\\"+fn)
return arr
def wry(txt, path): # 写入txt文件
f = codecs.open(path, 'a', 'utf8')
f.write(txt)
f.close()
return path
def read(path): # 读取txt文件,并返回list
f = open(path, encoding="utf8")
data = []
for line in f.readlines():
data.append(line)
return data
def toword(txtlis): # 将一片文章按照‘/'切割成词表,返回list
wordlist = []
alltxt = ''
for i in txtlis:
alltxt = alltxt+str(i)
ridenter = alltxt.replace('\n', '')
wordlist = ridenter.split('/')
return wordlist
def getstopword(path): # 获取停用词表
swlis = []
for i in read(path):
outsw = str(i).replace('\n', '')
swlis.append(outsw)
return swlis
def getridofsw(lis, swlist): # 去除文章中的停用词
afterswlis = []
for i in lis:
if str(i) in swlist:
continue
else:
afterswlis.append(str(i))
return afterswlis
def freqword(wordlis): # 统计词频,并返回字典
freword = {}
for i in wordlis:
if str(i) in freword:
count = freword[str(i)]
freword[str(i)] = count+1
else:
freword[str(i)] = 1
return freword
def corpus(filelist, swlist): # 建立语料库
alllist = []
for i in filelist:
afterswlis = getridofsw(toword(read(str(i))), swlist)
alllist.append(afterswlis)
return alllist
def wordinfilecount(word, corpuslist): # 查出包含该词的文档数
count = 0 # 计数器
for i in corpuslist:
for j in i:
if word in set(j): # 只要文档出现该词,这计数器加1,所以这里用集合
count = count+1
else:
continue
return count
def tf_idf(wordlis, filelist, corpuslist): # 计算TF-IDF,并返回字典
outdic = {}
tf = 0
idf = 0
dic = freqword(wordlis)
outlis = []
for i in set(wordlis):
tf = dic[str(i)]/len(wordlis) # 计算TF:某个词在文章中出现的次数/文章总词数
# 计算IDF:log(语料库的文档总数/(包含该词的文档数+1))
idf = math.log(len(filelist)/(wordinfilecount(str(i), corpuslist)+1))
tfidf = tf*idf # 计算TF-IDF
outdic[str(i)] = tfidf
orderdic = sorted(outdic.items(), key=operator.itemgetter(
1), reverse=True) # 给字典排序
return orderdic
def befwry(lis): # 写入预处理,将list转为string
outall = ''
for i in lis:
ech = str(i).replace("('", '').replace("',", '\t').replace(')', '')
outall = outall+'\t'+ech+'\n'
return outall
def main():
swpath = r'D:\Alan\myBlog\20170411《人民日报》TFIDF\code\哈工大停用词表.txt'#停用词表路径
swlist = getstopword(swpath) # 获取停用词表列表
filepath = r'D:\Alan\myBlog\20170411《人民日报》TFIDF\corpus'
filelist = fun(filepath) # 获取文件列表
wrypath = r'D:\Alan\myBlog\20170411《人民日报》TFIDF\result\TFIDF.txt'
corpuslist = corpus(filelist, swlist) # 建立语料库
outall = ''
for i in filelist:
afterswlis = getridofsw(toword(read(str(i))), swlist) # 获取每一篇已经去除停用的词表
tfidfdic = tf_idf(afterswlis, filelist, corpuslist) # 计算TF-IDF
titleary = str(i).split('\\')
title = str(titleary[-1]).replace('utf8.txt', '')
echout = title+'\n'+befwry(tfidfdic)
print(title+' is ok!')
outall = outall+echout
print(wry(outall, wrypath)+' is ok!')
if __name__ == '__main__':
main()
运行效果:

最终结果
这里放两篇新闻的TFIDF


可以看到,第一篇新闻的关键词可以认为为:核工业、发展、安全
第二篇新闻:习近平总书记、廉政、党风
关于\u3000\u3000这个问题实在不知道怎么替换掉,各种方法使用过了,不知哪位大神看到恳请指点下。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

TF-IDF算法解析与Python实现方法详解
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术.比较容易理解的一个应用场景是当我们手头有一些文章时,我们希望计算机能够自动地进行关键词提取.而TF-IDF就是可以帮我们完成这项任务的一种统计方法.它能够用于评估一个词语对于一个文集或一个语料库中的其中一份文档的重要程度. 在一份给定的文件里,词频 (term frequency, T
-
Python实现印章代码的算法解析
目录 1.题目 2.代码 3.代码解析 1.题目 2.代码 #共有n种图案的印章,每种图案的出现概率相同.小A买了m张印章,求小A集齐n种印章的概率. n,m=map(int,input().split()) dp=[[0 for i in range(n+1)]for j in range(m+1)] for i in range(1,m+1): for j in range(1,n+1): if(j>i): dp[i][j]=0 elif(j==1): dp[i][j]=pow(1/n,i-
-
Python内存管理方式和垃圾回收算法解析
概要 在列表,元组,实例,类,字典和函数中存在循环引用问题.有 __del__ 方法的实例会以健全的方式被处理.给新类型添加GC支持是很容易的.支持GC的Python与常规的Python是二进制兼容的. 分代式回收能运行工作(目前是三个分代).由 pybench 实测的结果是大约有百分之四的开销.实际上所有的扩展模块都应该依然如故地正常工作(我不得不修改了标准发行版中的 new 和 cPickle 模块).一个叫做 gc 的新模块马上就可以用来调试回收器和设置调试选项. 回收器应该是跨平台可移植
-
Python计算不规则图形面积算法实现解析
这篇文章主要介绍了Python计算不规则图形面积算法实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 介绍:大三上做一个医学影像识别的项目,医生在原图上用红笔标记病灶点,通过记录红色的坐标位置可以得到病灶点的外接矩形,但是后续会涉及到红圈内的面积在外接矩形下的占比问题,有些外接矩形内有多个红色标记,在使用网上的opencv的fillPoly填充效果非常不理想,还有类似python计算任意多边形方法也不理想的情况下,自己探索出的一种效果还不
-
python实现TF-IDF算法解析
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术. 同样,理论我这里不再赘述,因为和阮一峰大神早在2013年就将TF-IDF用一种非常通俗的方式讲解出来 TF-IDF与余弦相似性的应用(一):自动提取关键词 材料 1.语料库(已分好词) 2.停用词表(哈工大停用词表) 3.python3.5 语料库的准备 这里使用的语料库是<人民日报>2015年1月16日至1月18日的发表的新闻.并且在进行TFIDF处
-
Python机器学习logistic回归代码解析
本文主要研究的是Python机器学习logistic回归的相关内容,同时介绍了一些机器学习中的概念,具体如下. Logistic回归的主要目的:寻找一个非线性函数sigmod最佳的拟合参数 拟合.插值和逼近是数值分析的三大工具 回归:对一直公式的位置参数进行估计 拟合:把平面上的一些系列点,用一条光滑曲线连接起来 logistic主要思想:根据现有数据对分类边界线建立回归公式.以此进行分类 sigmoid函数:在神经网络中它是所谓的激励函数.当输入大于0时,输出趋向于1,输入小于0时,输出趋向0
-
Python cookbook(数据结构与算法)对切片命名清除索引的方法
本文实例讲述了Python对切片命名清除索引的方法.分享给大家供大家参考,具体如下: 问题:如何清理掉到处都是硬编码的切片索引 解决方案:对切片命名 假设有一些代码用来从字符串的固定位置中取出具体的数据(比如从一个平面文件或类似的格式:平面文件flat file是一种包含没有相对关系结构的记录文件): ########0123456789012345678901234567890123456789012345678901234567890123456789 record='...........
-
Python cookbook(数据结构与算法)从序列中移除重复项且保持元素间顺序不变的方法
本文实例讲述了Python从序列中移除重复项且保持元素间顺序不变的方法.分享给大家供大家参考,具体如下: 问题:从序列中移除重复的元素,但仍然保持剩下的元素顺序不变 解决方案: 1.如果序列中的值时可哈希(hashable)的,可以通过使用集合和生成器解决. # example.py # # Remove duplicate entries from a sequence while keeping order def dedupe(items): seen = set() for item i
-
Python实现加载及解析properties配置文件的方法
本文实例讲述了Python实现加载及解析properties配置文件的方法.分享给大家供大家参考,具体如下: 这里参考前面一篇:http://www.jb51.net/article/137393.htm 我们都是在java里面遇到要解析properties文件,在python中基本没有遇到这中情况,今天用python跑深度学习的时候,发现有些参数可以放在一个global.properties全局文件中,这样使用的时候更加方便.原理都是加载文件,然后用line方法进行解析判断"=",自
-
Python实现基于POS算法的区块链
区块链中的共识算法 在比特币公链架构解析中,就曾提到过为了实现去中介化的设计,比特币设计了一套共识协议,并通过此协议来保证系统的稳定性和防攻击性. 并且我们知道,截止目前使用最广泛,也是最被大家接受的共识算法,是我们先前介绍过的POW(proof of work)工作量证明算法.目前市值排名前二的比特币和以太坊也是采用的此算法. 虽然POW共识算法取得了巨大的成功,但对它的质疑也从来未曾停止过. 其中最主要的一个原因就是电力消耗.据不完全统计,基于POW的挖矿机制所消耗的电量是非常巨大的,甚至比