50行Python代码获取高考志愿信息的实现方法
最近遇到个任务,需要将高考志愿信息保存成Excel表格,BOSS丢给我一个网址表格之后就让我自己干了。虽然我以前也学习过Python编写爬虫的知识,不过时间长了忘了,于是摸索了一天之后终于完成了任务。不得不说,Python干这个还是挺容易的,最后写完一看代码,只用了50行就完成了任务。

准备工作
首先明确一下任务。首先我们要从网址表格中读取到一大串网址,然后访问每个网址,获取到页面上的学校信息,然后将它们在写到另一个Excel中。显然,我们需要一个爬虫库和一个Excel库来帮助我们完成任务。
第一步自然是安装它们,requests-html是一个非常好用的HTML解析库,拿来做简单的爬虫非常优雅;而openpyxl是一个Excel表格库,可以轻松创建和处理Excel数据。
pip install requests-html openpyxl
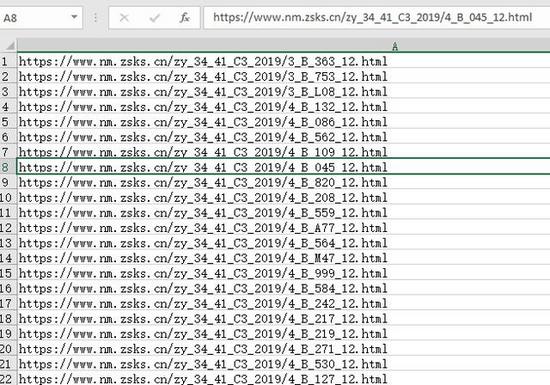
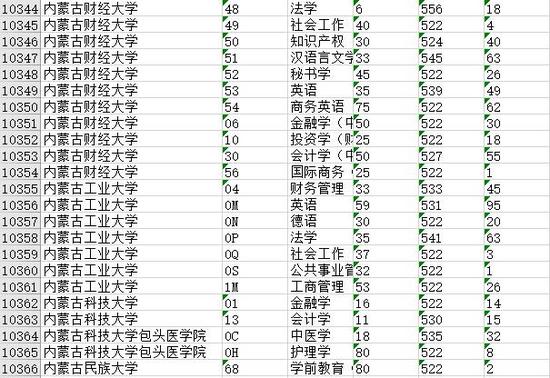
然后就是网址表格,大概长这样,总共大概一千七百多条数据。其中有少量网址是错误的,访问会得到404错误,所以在编写代码的时候还要注意错误处理。
任务分析
任务的核心自然就是分析和获取网页内容了。首先现在浏览器里面打开一个网址,看看网页上的内容是什么。
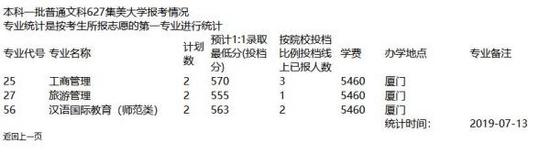
可以看到这个网页格式很乱,学校名字什么的都是混在一起的,一点也不规整,这给我们提取数据造成了不少的麻烦。不过仔细分析之后,其实问题也并不难。
首先要提取的是学校名字,可以看到学校名字和其他文字混在一起,例如"本科一批普通文科627集美大学报考情况"。本来我准备用正则表达式提取,然后发现用正则表达式好像很难。之后我多访问了几个网页,发现学校代码基本上都是数字,如果有字母的话也出现到第一位,所以我采用了以下的算法,首先将字符串从数字处分隔,右边的一个部分就包含了学校名字和“报考情况”几个字,然后删除“报考情况”即可得到学校名字。这个算法唯一的缺点就是,假如出现了字母在中间的代号,就没办法获取到学校名字了,不过实际运行之后,我幸运的发现并没有出现这种情况。
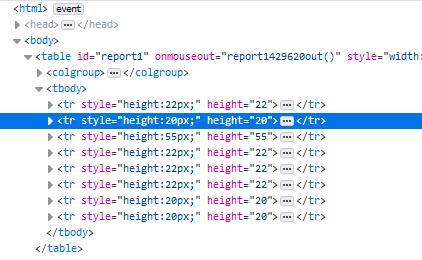
之后要提取的就是专业信息了,在网页源代码中这部分使用tr和td标签来呈现的。一开始我用的是tr加上选择器来提取,但是这个网页生成的时候很有问题,每个tr标签的样式居然还根据内容的多少而不同,导致我写死的选择器没法完美获取所有行。不过后来我发现整个网页内容都是一个表格, 除去表头和结尾的几个固定行之外,剩下的恰好就是要提取的数据行,所以直接获取tr标签,然后切片除去收尾即可。
网页基本上分析完了,下面就是编写代码了。
编写代码
总共50行左右代码,我添加了注释,相信大家应该很容易就可以看懂。
第一部分代码是从网址表格读取所有url,一开始编写的时候,表格里的url是从另一个公式生成的,所以需要在加载的时候添加data_only=True才能读取到公式的结果,否则只能读取到公式本身。
第二部分是创建输出文件,然后编写表头。顺带为了调试方便,我让它如果检测到已经存在目标文件的话就删掉,在建立一个新的。
第三部分就是代码的核心了。Python代码看着可能有点奇怪,不过对照上面的分析,我想大家应该很容易看懂。需要注意保存文件在最后,假如半路代码出现异常,整个就白干了,而一千七百多条网址不可能保证都正常运行。由于输出格式是“学校名+专业信息”这样的格式,所以我获取学校名之后,还要将学校插入到每行专业信息之前。所以我这里索性直接用try-except包起来,如果出错的话只打印一下出错的网址。
import os
from requests_html import HTMLSession
from openpyxl import Workbook, load_workbook
# 从网址表格获取urls
def get_urls():
input_file = 'source.xlsx'
wb = load_workbook(input_file, data_only=True)
ws = wb.active
urls = [row[0] for row in ws.values]
wb.close()
return urls
# 输出Excel文件,如果已存在则删除已有的
out_file = 'data.xlsx'
if os.path.exists(out_file):
os.remove(out_file)
wb = Workbook()
ws = wb.active
# 编写第一行表头
ws['a1'] = '学校'
ws['b1'] = '专业代号'
ws['c1'] = '专业名称'
ws['d1'] = '计划数'
ws['e1'] = '预计1:1录取最低分(投档分)'
ws['f1'] = '按院校投档比例投档线上已报人数'
ws['g1'] = '学费'
ws['h1'] = '办学地点'
ws['i1'] = '专业备注'
# 发起网络请求,解析网页信息,并写入文件
session = HTMLSession()
urls = get_urls()
for url in urls:
import re
page = session.get(url)
page.html.encoding = 'gb2312'
try:
college_info = page.html.xpath('//td[@class="report1_1_1"]/text()', first=True)
college = re.split('\d+', college_info)[1].replace('报考情况', '')
rows = page.html.xpath('//tr')[3:-2]
for r in rows:
info = [x.text for x in r.xpath('//td')]
info.insert(0, college)
ws.append(info)
print(info)
except:
print(url)
# 保存文件
wb.save(out_file)
运行结果
好了,费了大半天的劲,代码终于完成了。让我们运行一下看看结果。整个代码大概需要运行7-8分钟,最后完成之后得到了一个500多k的Excel文件。
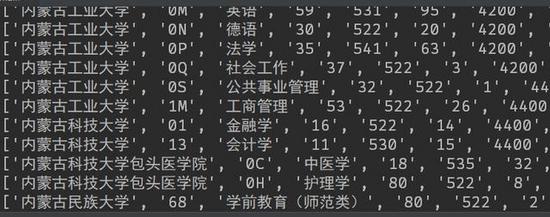
打开之后,可以发现Excel文件填的满满的,最后总共获取到了大约一万多条数据,任务圆满完成。
总结
以上所述是小编给大家介绍的50行Python代码获取高考志愿信息的实现方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

网红编程语言Python将纳入高考你怎么看?
近日,2018年最具就业前景的7大编程语言排行榜出炉了.这次的编程语言排行榜是由CodingDojo(编码道场)发布.在此次的最有"钱"途的编程语言榜单上,Java排名第一,网红编程语言Python排名第二,JavaScript排名第三.Python简直可以评得上2017年网红编程的语言,在此次榜单上,它又火了一把.Python加入浙江省高考,而且还成为了山东省小学生教材. 小学生都开始学的编程语言,你敢说它未来几年不火呢?这多半也是由于:未来是AI的时代,Python语言是最接近人工
-
50行Python代码获取高考志愿信息的实现方法
最近遇到个任务,需要将高考志愿信息保存成Excel表格,BOSS丢给我一个网址表格之后就让我自己干了.虽然我以前也学习过Python编写爬虫的知识,不过时间长了忘了,于是摸索了一天之后终于完成了任务.不得不说,Python干这个还是挺容易的,最后写完一看代码,只用了50行就完成了任务. 准备工作 首先明确一下任务.首先我们要从网址表格中读取到一大串网址,然后访问每个网址,获取到页面上的学校信息,然后将它们在写到另一个Excel中.显然,我们需要一个爬虫库和一个Excel库来帮助我们完成任务. 第
-
如何通过50行Python代码获取公众号全部文章
前言 我们平时阅读公众号的文章会遇到一个问题--阅读历史文章体验不好. 我们知道爬取公众号的方式常见的有两种:通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章.通过微信公众号的素材管理,获取公众号文章.缺点是需要申请自己的公众号. 今天介绍一种通过抓包PC端微信的方式去获取公众号文章的方法.相比其他的方法非常方便. 如上图,通过抓包工具获取微信的网络信息请求,我们发现每次下拉刷新文章的时候都会请求 mp.weixin.qq.com/mp/xxx (公众号不让添加主页链接,xxx表示profi
-
只用50行Python代码爬取网络美女高清图片
一.技术路线 requests:网页请求 BeautifulSoup:解析html网页 re:正则表达式,提取html网页信息 os:保存文件 import re import requests import os from bs4 import BeautifulSoup 二.获取网页信息 常规操作,获取网页信息的固定格式,返回的字符串格式的网页内容,其中headers参数可模拟人为的操作,'欺骗'网站不被发现 def getHtml(url): #固定格式,获取html内容 headers
-
50行Python代码实现人脸检测功能
现在的人脸识别技术已经得到了非常广泛的应用,支付领域.身份验证.美颜相机里都有它的应用.用iPhone的同学们应该对下面的功能比较熟悉 iPhone的照片中有一个"人物"的功能,能够将照片里的人脸识别出来并分类,背后的原理也是人脸识别技术. 这篇文章主要介绍怎样用Python实现人脸检测.人脸检测是人脸识别的基础.人脸检测的目的是识别出照片里的人脸并定位面部特征点,人脸识别是在人脸检测的基础上进一步告诉你这个人是谁. 好了,介绍就到这里.接下来,开始准备我们的环境. 准备工作 本文的人
-
使用50行Python代码从零开始实现一个AI平衡小游戏
集智导读: 本文会为大家展示机器学习专家 Mike Shi 如何用 50 行 Python 代码创建一个 AI,使用增强学习技术,玩耍一个保持杆子平衡的小游戏.所用环境为标准的 OpenAI Gym,只使用 Numpy 来创建 agent. 各位看官好,我(作者 Mike Shi--译者注)将在本文教大家如何用 50 行 Python 代码,教会 AI 玩一个简单的平衡游戏.我们会用到标准的 OpenAI Gym 作为测试环境,仅用 Numpy 创建我们的 AI,别的不用. 这个小游戏就是经典的
-
50行Python代码实现视频中物体颜色识别和跟踪(必须以红色为例)
目前计算机视觉(CV)与自然语言处理(NLP)及语音识别并列为人工智能三大热点方向,而计算机视觉中的对象检测(objectdetection)应用非常广泛,比如自动驾驶.视频监控.工业质检.医疗诊断等场景. 目标检测的根本任务就是将图片或者视频中感兴趣的目标提取出来,目标的识别可以基于颜色.纹理.形状.其中颜色属性运用十分广泛,也比较容易实现.下面就向大家分享一个我做的小实验---通过OpenCV的Python接口来实现从视频中进行颜色识别和跟踪. 下面就是我们完整的代码实现(已调试运行): i
-
仅用50行Python代码实现一个简单的代理服务器
之前遇到一个场景是这样的: 我在自己的电脑上需要用mongodb图形客户端,但是mongodb的服务器地址没有对外网开放,只能通过先登录主机A,然后再从A连接mongodb服务器B. 本来想通过ssh端口转发的,但是我没有从机器A连接ssh到B的权限.于是就自己用python写一个. 原理很简单. 1.开一个socket server监听连接请求 2.每接受一个客户端的连接请求,就往要转发的地址建一条连接请求.即client->proxy->forward.proxy既是socket服务端(监
-
只用40行Python代码就能写出pdf转word小工具
一.图示 上面为pdf截图内容,下面为转化后的word截图内容 接下来,我们试试自己动作写这个工具吧! 二.前期准备 由于我们采用的是python进行工具编写,并最终需要打包成一个exe文件供我们使用.为了降低包体大小,我们需要先创建一个虚拟环境备用. 另外,pdf转word有现成的第三方库pdf2docx,同时关于gui我们用的是pysimplegui,打包成exe采用的是pyinstaller.在创建虚拟环境后,我们将这些需要用到的第三方库也一一安装吧. # 创建虚拟环境 conda cre
-
10 行Python 代码实现 AI 目标检测技术【推荐】
只需10行Python代码,我们就能实现计算机视觉中目标检测. from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_b
-
100行Python代码实现每天不同时间段定时给女友发消息
每天不同时间段通过微信发消息提醒女友 简介 有时候,你很想关心她,但是你太忙了,以至于她一直抱怨,觉得你不够关心她.你暗自下决心,下次一定要准时发消息给她,哪怕是几句话,可是你又忘记了.你觉得自己很委屈