springboot基于Mybatis mysql实现读写分离
近日工作任务较轻,有空学习学习技术,遂来研究如果实现读写分离。这里用博客记录下过程,一方面可备日后查看,同时也能分享给大家(网上的资料真的大都是抄来抄去,,还不带格式的,看的真心难受)。
完整代码:https://github.com/FleyX/demo-project/tree/master/dxfl
1、背景
一个项目中数据库最基础同时也是最主流的是单机数据库,读写都在一个库中。当用户逐渐增多,单机数据库无法满足性能要求时,就会进行读写分离改造(适用于读多写少),写操作一个库,读操作多个库,通常会做一个数据库集群,开启主从备份,一主多从,以提高读取性能。当用户更多读写分离也无法满足时,就需要分布式数据库了(可能以后会学习怎么弄)。
正常情况下读写分离的实现,首先要做一个一主多从的数据库集群,同时还需要进行数据同步。这一篇记录如何用 mysql 搭建一个一主多次的配置,下一篇记录代码层面如何实现读写分离。
2、搭建一主多从数据库集群
主从备份需要多台虚拟机,我是用 wmware 完整克隆多个实例,注意直接克隆的虚拟机会导致每个数据库的 uuid 相同,需要修改为不同的 uuid。
•主库配置
主数据库(master)中新建一个用户用于从数据库(slave)读取主数据库二进制日志,sql 语句如下:
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY '123456';#创建用户 mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';#分配权限 mysql>flush privileges; #刷新权限
同时修改 mysql 配置文件开启二进制日志,新增部分如下:
[mysqld] server-id=1 log-bin=master-bin log-bin-index=master-bin.index
然后重启数据库,使用show master status;语句查看主库状态,如下所示:

•从库配置
同样先新增几行配置:
[mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin
然后重启数据库,使用如下语句连接主库:
CHANGE MASTER TO MASTER_HOST='192.168.226.5', MASTER_USER='root', MASTER_PASSWORD='123456', MASTER_LOG_FILE='master-bin.000003', MASTER_LOG_POS=154;
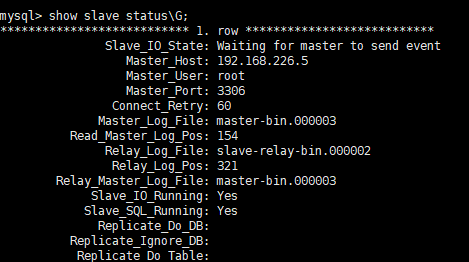
接着运行start slave;开启备份,正常情况如下图所示:Slave_IO_Running 和 Slave_SQL_Running 都为 yes。
可以用这个步骤开启多个从库。
默认情况下备份是主库的全部操作都会备份到从库,实际可能需要忽略某些库,可以在主库中增加如下配置:
# 不同步哪些数据库 binlog-ignore-db = mysql binlog-ignore-db = test binlog-ignore-db = information_schema # 只同步哪些数据库,除此之外,其他不同步 binlog-do-db = game
3、代码层面进行读写分离
代码环境是 springboot+mybatis+druib 连接池。想要读写分离就需要配置多个数据源,在进行写操作是选择写的数据源,读操作时选择读的数据源。其中有两个关键点:
•如何切换数据源
•如何根据不同的方法选择正确的数据源
1)、如何切换数据源
通常用 springboot 时都是使用它的默认配置,只需要在配置文件中定义好连接属性就行了,但是现在我们需要自己来配置了,spring 是支持多数据源的,多个 datasource 放在一个 HashMapTargetDataSource中,通过dertermineCurrentLookupKey获取 key 来觉定要使用哪个数据源。因此我们的目标就很明确了,建立多个 datasource 放到 TargetDataSource 中,同时重写 dertermineCurrentLookupKey 方法来决定使用哪个 key。
2)、如何选择数据源
事务一般是注解在 Service 层的,因此在开始这个 service 方法调用时要确定数据源,有什么通用方法能够在开始执行一个方法前做操作呢?相信你已经想到了那就是切面 。怎么切有两种办法:
•注解式,定义一个只读注解,被该数据标注的方法使用读库
•方法名,根据方法名写切点,比如 getXXX 用读库,setXXX 用写库
3)、代码编写
a、编写配置文件,配置两个数据源信息
只有必填信息,其他都有默认设置
mysql: datasource: #读库数目 num: 1 type-aliases-package: com.example.dxfl.dao mapper-locations: classpath:/mapper/*.xml config-location: classpath:/mybatis-config.xml write: url: jdbc:mysql://192.168.226.5:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true username: root password: 123456 driver-class-name: com.mysql.jdbc.Driver read: url: jdbc:mysql://192.168.226.6:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true username: root password: 123456 driver-class-name: com.mysql.jdbc.Driver
b、编写 DbContextHolder 类
这个类用来设置数据库类别,其中有一个 ThreadLocal 用来保存每个线程的是使用读库,还是写库。代码如下:
/**
* Description 这里切换读/写模式
* 原理是利用ThreadLocal保存当前线程是否处于读模式(通过开始READ_ONLY注解在开始操作前设置模式为读模式,
* 操作结束后清除该数据,避免内存泄漏,同时也为了后续在该线程进行写操作时任然为读模式
* @author fxb
* @date 2018-08-31
*/
public class DbContextHolder {
private static Logger log = LoggerFactory.getLogger(DbContextHolder.class);
public static final String WRITE = "write";
public static final String READ = "read";
private static ThreadLocal<String> contextHolder= new ThreadLocal<>();
public static void setDbType(String dbType) {
if (dbType == null) {
log.error("dbType为空");
throw new NullPointerException();
}
log.info("设置dbType为:{}",dbType);
contextHolder.set(dbType);
}
public static String getDbType() {
return contextHolder.get() == null ? WRITE : contextHolder.get();
}
public static void clearDbType() {
contextHolder.remove();
}
}
c、重写 determineCurrentLookupKey 方法
spring 在开始进行数据库操作时会通过这个方法来决定使用哪个数据库,因此我们在这里调用上面 DbContextHolder 类的getDbType()方法获取当前操作类别,同时可进行读库的负载均衡,代码如下:
public class MyAbstractRoutingDataSource extends AbstractRoutingDataSource {
@Value("${mysql.datasource.num}")
private int num;
private final Logger log = LoggerFactory.getLogger(this.getClass());
@Override
protected Object determineCurrentLookupKey() {
String typeKey = DbContextHolder.getDbType();
if (typeKey == DbContextHolder.WRITE) {
log.info("使用了写库");
return typeKey;
}
//使用随机数决定使用哪个读库
int sum = NumberUtil.getRandom(1, num);
log.info("使用了读库{}", sum);
return DbContextHolder.READ + sum;
}
}
d、编写配置类
由于要进行读写分离,不能再用 springboot 的默认配置,我们需要手动来进行配置。首先生成数据源,使用
@ConfigurProperties 自动生成数据源:
/**
* 写数据源
*
* @Primary 标志这个 Bean 如果在多个同类 Bean 候选时,该 Bean 优先被考虑。
* 多数据源配置的时候注意,必须要有一个主数据源,用 @Primary 标志该 Bean
*/
@Primary
@Bean
@ConfigurationProperties(prefix = "mysql.datasource.write")
public DataSource writeDataSource() {
return new DruidDataSource();
}
读数据源类似,注意有多少个读库就要设置多少个读数据源,Bean 名为 read+序号。
然后设置数据源,使用的是我们之前写的 MyAbstractRoutingDataSource 类
/**
* 设置数据源路由,通过该类中的determineCurrentLookupKey决定使用哪个数据源
*/
@Bean
public AbstractRoutingDataSource routingDataSource() {
MyAbstractRoutingDataSource proxy = new MyAbstractRoutingDataSource();
Map<Object, Object> targetDataSources = new HashMap<>(2);
targetDataSources.put(DbContextHolder.WRITE, writeDataSource());
targetDataSources.put(DbContextHolder.READ+"1", read1());
proxy.setDefaultTargetDataSource(writeDataSource());
proxy.setTargetDataSources(targetDataSources);
return proxy;
}
接着需要设置 sqlSessionFactory
/**
* 多数据源需要自己设置sqlSessionFactory
*/
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(routingDataSource());
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
// 实体类对应的位置
bean.setTypeAliasesPackage(typeAliasesPackage);
// mybatis的XML的配置
bean.setMapperLocations(resolver.getResources(mapperLocation));
bean.setConfigLocation(resolver.getResource(configLocation));
return bean.getObject();
}
最后还得配置下事务,否则事务不生效
/**
* 设置事务,事务需要知道当前使用的是哪个数据源才能进行事务处理
*/
@Bean
public DataSourceTransactionManager dataSourceTransactionManager() {
return new DataSourceTransactionManager(routingDataSource());
}
4)、选择数据源
多数据源配置好了,但是代码层面如何选择选择数据源呢?这里介绍两种办法:
a、注解式
首先定义一个只读注解,被这个注解方法使用读库,其他使用写库,如果项目是中途改造成读写分离可使用这个方法,无需修改业务代码,只要在只读的 service 方法上加一个注解即可。
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface ReadOnly {
}
然后写一个切面来切换数据使用哪种数据源,重写 getOrder 保证本切面优先级高于事务切面优先级,在启动类加上@EnableTransactionManagement(order = 10),为了代码如下:
@Aspect
@Component
public class ReadOnlyInterceptor implements Ordered {
private static final Logger log= LoggerFactory.getLogger(ReadOnlyInterceptor.class);
@Around("@annotation(readOnly)")
public Object setRead(ProceedingJoinPoint joinPoint,ReadOnly readOnly) throws Throwable{
try{
DbContextHolder.setDbType(DbContextHolder.READ);
return joinPoint.proceed();
}finally {
//清楚DbType一方面为了避免内存泄漏,更重要的是避免对后续在本线程上执行的操作产生影响
DbContextHolder.clearDbType();
log.info("清除threadLocal");
}
}
@Override
public int getOrder() {
return 0;
}
}
b、方法名式
这种方法不许要注解,但是需要service中方法名称按一定规则编写,然后通过切面来设置数据库类别,比如setXXX设置为写、getXXX设置为读,代码我就不写了,应该都知道怎么写。
4、测试
编写好代码来试试结果如何,下面是运行截图:

测试结果
读写分离只是数据库扩展的一个临时解决办法,并不能一劳永逸,随着负载进一步增大,只有一个库用于写入肯定是不够的,而且单表的数据库是有上限的,mysql 最多千万级别的数据能保持较好的查询性能。最终还是会变成--分库分表架构的。
总结
以上所述是小编给大家介绍的springboot基于Mybatis mysql实现读写分离,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
springboot 多模块将dao(mybatis)项目拆分出去
前言: 以前我们在建项目的时候, 要么将所有的package建在一个项目里面, 在处理引用的时候, 真的很方便. 不用担心, 有些东西配置不到或者读取不到. 或者, 将package独立出去, 到一个项目中或者子项目中. 这时候, 项目中的引用处理, 还是有些麻烦的. 不过好处更多, 不再表述. 在 idea 里面, 推荐使用 多模块 建项目, 而不再是 eclipse 里面的那种方式. 那这里, 就试着将一个springboot 的项目拆分到子模块中去, 看看效果如何. 项目拆分: 1. 目录
-

详解SpringBoot 快速整合Mybatis(去XML化+注解进阶)
序言:使用MyBatis3提供的注解可以逐步取代XML,例如使用@Select注解直接编写SQL完成数据查询,使用@SelectProvider高级注解还可以编写动态SQL,以应对复杂的业务需求. 一. 基础注解 MyBatis 主要提供了以下CRUD注解: @Select @Insert @Update @Delete 增删改查占据了绝大部分的业务操作,掌握这些基础注解的使用是很必要的.例如下面这段代码无需XML即可完成数据查询: @Mapper public interface UserMa
-
详解SpringBoot和Mybatis配置多数据源
目前业界操作数据库的框架一般是 Mybatis,但在很多业务场景下,我们需要在一个工程里配置多个数据源来实现业务逻辑.在SpringBoot中也可以实现多数据源并配合Mybatis框架编写xml文件来执行SQL.在SpringBoot中,配置多数据源的方式十分便捷, 下面开始上代码: 在pom.xml文件中需要添加一些依赖 <!-- Spring Boot Mybatis 依赖 --> <dependency> <groupId>org.mybatis.spring.b
-
springboot整合mybatis将sql打印到日志的实例详解
在前台请求数据的时候,sql语句一直都是打印到控制台的,有一个想法就是想让它打印到日志里,该如何做呢? 见下面的mybatis配置文件: <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-
-
SpringBoot连接MYSQL数据库并使用JPA进行操作
今天给大家介绍一下如何SpringBoot中连接Mysql数据库,并使用JPA进行数据库的相关操作. 步骤一:在pom.xml文件中添加MYSQl和JPA的相关Jar包依赖,具体添加位置在dependencies中,具体添加的内容如下所示. <!--数据库相关配置--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-
-
SpringBoot Mybatis Plus公共字段自动填充功能
一.应用场景 平时在建对象表的时候都会有最后修改时间,最后修改人这两个字段,对于这些大部分表都有的字段,每次在新增和修改的时候都要考虑到这几个字段有没有传进去,很麻烦.mybatisPlus有一个很好的解决方案.也就是公共字段自动填充的功能.一般满足下面条件的字段就可以使用此功能: 这个字段是大部分表都会有的. 这个字段的值是固定的,或则字段值是可以在后台动态获取的. 常用的就是last_update_time,last_update_name这两个字段. 二.配置MybatisPlus 导包:
-
springboot+springmvc+mybatis项目整合
介绍: 上篇给大家介绍了ssm多模块项目的搭建,在搭建过程中spring整合springmvc和mybatis时会有很多的东西需要我们进行配置,这样不仅浪费了时间,也比较容易出错,由于这样问题的产生,Pivotal团队提供了一款全新的框架,该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置.通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者. 特点: 1. 创建独立的Spring应用
-
SpringBoot整合MyBatis逆向工程及 MyBatis通用Mapper实例详解
一.添加所需依赖,当前完整的pom文件如下: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd&q
-
Springboot上传excel并将表格数据导入或更新mySql数据库的过程
本文主要描述,Springboot-mybatis框架下上传excel,并将之导入mysql数据库的过程,如果用户id已存在,则进行更新修改数据库中该项信息,由于用到的是前后端分离技术,这里记录的主要是后端java部分,通过与前端接口进行对接实现功能,使用layui等前端框架与之对接,也可以自己写前端代码,本文以Controller开始,从导入过程开始讲述,其中包括字典表的转换 1.在pom.xml文件中导入注解,主要利用POI <dependency> <groupId>org.
-
springboot基于Mybatis mysql实现读写分离
近日工作任务较轻,有空学习学习技术,遂来研究如果实现读写分离.这里用博客记录下过程,一方面可备日后查看,同时也能分享给大家(网上的资料真的大都是抄来抄去,,还不带格式的,看的真心难受). 完整代码:https://github.com/FleyX/demo-project/tree/master/dxfl 1.背景 一个项目中数据库最基础同时也是最主流的是单机数据库,读写都在一个库中.当用户逐渐增多,单机数据库无法满足性能要求时,就会进行读写分离改造(适用于读多写少),写操作一个库,读操作多个库
-
SpringBoot+MyBatis+AOP实现读写分离的示例代码
目录 一. MySQL 读写分离 1.1.如何实现 MySQL 的读写分离? 1.2.MySQL 主从复制原理? 1.3.MySQL 主从同步延时问题(精华) 二.SpringBoot+AOP+MyBatis实现MySQL读写分离 2.1.AbstractRoutingDataSource 2.2.如何切换数据源 2.3.如何选择数据源 三 .代码实现 3.0.工程目录结构 3.1.引入Maven依赖 3.2.编写配置文件,配置主从数据源 3.3.Enum类,定义主库从库 3.4.ThreadL
-
spring集成mybatis实现mysql数据库读写分离
前言 在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈.幸运的是目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库的数据更新同步到另一台服务器上.网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力.如下图所示: 应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据.为了便于应用程序访问读写分离后的数据库,通常在应用服务器使用专门的数
-
SpringBoot整合Sharding-JDBC实现MySQL8读写分离
目录 一.前言 二.项目目录结构 三.pom文件 四.配置文件(基于YAML)及SQL建表语句 五.Mapper.xml文件及Mapper接口 六 .Controller及Mocel文件 七.结果 八.Sharding-JDBC不同版本上的配置 一.前言 这是一个基于SpringBoot整合Sharding-JDBC实现读写分离的极简教程,笔者使用到的技术及版本如下: SpringBoot 2.5.2 MyBatis-Plus 3.4.3 Sharding-JDBC 4.1.1 MySQL8集群
-
详解如何利用amoeba(变形虫)实现mysql数据库读写分离
关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的.由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用: amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk: 前期准备工作: 1.两个数据库,一主一从,主从同步: master: 172.22.10.237:3306 :主库负责写入操作: slave: 10.4.66.58
-
MySQL Router实现MySQL的读写分离的方法
1.简介 MySQL Router是MySQL官方提供的一个轻量级MySQL中间件,用于取代以前老版本的SQL proxy. 既然MySQL Router是一个数据库的中间件,那么MySQL Router必须能够分析来自前面客户端的SQL请求是写请求还是读请求,以便决定这个SQL请求是发送给master还是slave,以及发送给哪个master.哪个slave.这样,MySQL Router就实现了MySQL的读写分离,对MySQL请求进行了负载均衡. 因此,MySQL Router的前提是后端
-
Linux如何使用 MyCat 实现 MySQL 主从读写分离
目录 Linux-使用 MyCat 实现 MySQL 主从读写分离 一.MySQL 读写分离 1.MySQL 读写分离的概述 2.读写分离工作原理 3.为什么要读写分离 3.实现读写分离的方式 4.常见的中间件程序 二.MyCAT简述 1.什么是 MyCAT 2.MyCat 服务安装与配置 三.MyCat 服务启动与启动设置 四.配置 MySQL 主从 五.实战节点宕机后自动切换 Slave 节点 1.mycat 配置文件优化调整 2.停主节点: 3.恢复主节点: Linux-使用 MyCat
-
SpringBoot详解如何实现读写分离
目录 前言 1.项目引入依赖 2.yml配置 3.启动 4.测试 5.中间所遇到的问题 前言 根据公司业务需求,项目需要读写分离,所以记录下读写分离的过程. 分为两个部分: 1.项目的读写分离. 2.mysql数据库的主从复制. 本篇使用的依赖包为sharding-jdbc-spring-boot-starter,也有考虑直接用dynamic-datasource-spring-boot-starter,但是需要在程序中显式的声明所指定的数据源,并且在从库>=2 的时候需要自己写算法进行读库的选
-
Spring+MyBatis实现数据库读写分离方案
推荐第四种 方案1 通过MyBatis配置文件创建读写分离两个DataSource,每个SqlSessionFactoryBean对象的mapperLocations属性制定两个读写数据源的配置文件.将所有读的操作配置在读文件中,所有写的操作配置在写文件中. 优点:实现简单 缺点:维护麻烦,需要对原有的xml文件进行重新修改,不支持多读,不易扩展 实现方式 <bean id="abstractDataSource" abstract="true" class=
-
python实现mysql的读写分离及负载均衡
Oracle数据库有其公司开发的配套rac来实现负载均衡,目前已知的最大节点数能到128个,但是其带来的维护成本无疑是很高的,并且rac的稳定性也并不是特别理想,尤其是节点很多的时候. 但是,相对mysql来说,rac的实用性要比mysql的配套集群软件mysql-cluster要高很多.因为从网上了解到情况来看,很少公司在使用mysql-cluster,大多数企业都会选择第三方代理软件,例如MySQL Proxy.Mycat.haproxy等,但是这会引起另外一个问题:单点故障(包括mysql