python读取各种文件数据方法解析
python读取.txt(.log)文件 、.xml 文件 、excel文件数据,并将数据类型转换为需要的类型,添加到list中详解
1.读取文本文件数据(.txt结尾的文件)或日志文件(.log结尾的文件)
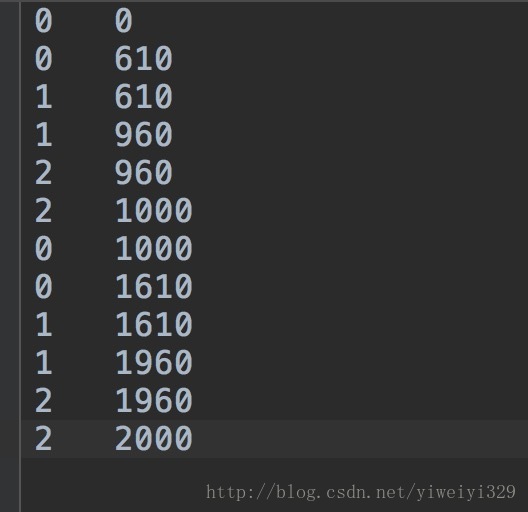
以下是文件中的内容,文件名为data.txt(与data.log内容相同),且处理方式相同,调用时改个名称就可以了:
以下是python实现代码:
# -*- coding:gb2312 -*-
import json
def read_txt_high(filename):
with open(filename, 'r') as file_to_read:
list0 = [] #文件中的第一列数据
list1 = [] #文件中的第二列数据
while True:
lines = file_to_read.readline() # 整行读取数据
if not lines:
break
item = [i for i in lines.split()]
data0 = json.loads(item[0])#每行第一个值
data1 = json.loads(item[1])#每行第二个值
list0.append(data0)
list1.append(data1)
return list0,list1
list0与list1分别为文档中的第一列数据与第二列数据。运行若是文本文件(.txt结尾的文件)输入以下:
aa,bb = read_txt_high('data.txt')
print aa
print bb
若是日志文件(.log结尾的文件),输入以下:
aa,bb = read_txt_high('data.log')
print aa
print bb
运行结果如下:

2.读取.xml结尾的文件
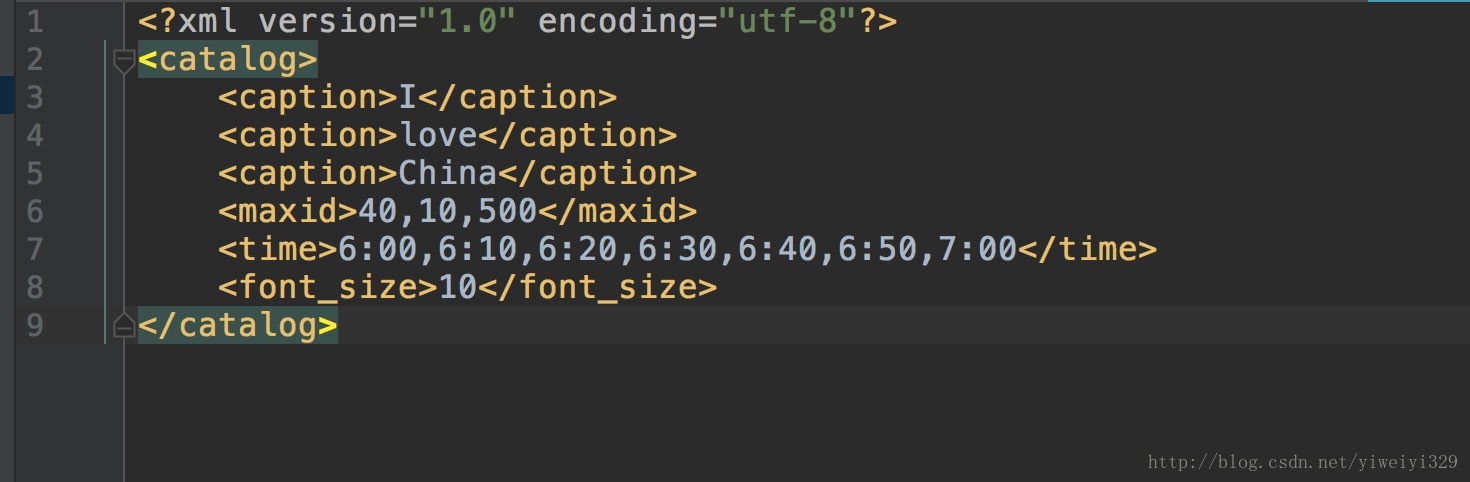
XML文件的名称为abc.xml, 内容如下图所示:
以下是实现代码:
# -*- coding:gb2312 -*-
# coding = utf-8
from pylab import *
import xml.dom.minidom
def read_xml():
dom = xml.dom.minidom.parse('abc.xml')#打开xml文档
cc=dom.getElementsByTagName('caption')
list_str = [] #字符串
for item in cc:
list_str.append(str(item.firstChild.data))
bb = dom.getElementsByTagName('maxid')
list_fig = []
for item in bb:
list_fig.append(item.firstChild.data)
su = list_fig[0].encode("gbk")
list_fig2 = su.split(",")
list_fig_num = []
for i in list_fig2:
list_fig_num.append(int(i))
ee = dom.getElementsByTagName('time')
list_tim = []
for item in ee:
list_tim.append(item.firstChild.data)
sg = list_tim[0].encode("gbk")
list_time = sg.split(",")
gg = dom.getElementsByTagName('font_size')
g1 = []
for item in gg:
g1.append(item.firstChild.data)
su = g1[0].encode("gbk")
return list_str,list_fig_num,list_time,su
调用此函数如下所示:
a,b,c,d = read_xml() print a print b print c print d
输出结果如下图所示:

3.读取excel文件数据,并将其存入list列表中
excel表格中的数据如下图所示,表格命名为data.xlsx:

首先将ID列中的数据保存到列表list_col中,实现代码如下所示:
# -*- coding: utf-8 -*-
import xlrd
import json
def read_ex_stop_PTline():
# 打开文件
workbook = xlrd.open_workbook(r'data.xlsx')
sheet = workbook.sheet_by_name('PTline')
list_col = []
for i in range(1,sheet.nrows):
c = sheet.cell(i,3).value
list_col.append(int(c))
print list_col
调用此函数,输出结果如下:

以下将linkIDsequence列数据存放到一个list中,即list_ele中,实现代码如下:
# -*- coding: utf-8 -*-
import xlrd
import json
def read_ex_stop_PTline():
# 打开文件
workbook = xlrd.open_workbook(r'data.xlsx')
sheet = workbook.sheet_by_name('PTline')
list_ele = [] #第八列的所有数据放入一个list中
for i in range(1,sheet.nrows):
c = sheet.cell(i, 8).value
cc = json.loads(c) #第八列的每个单元格处理为一个list
for j in range(len(cc)):
list_ele.append(cc[j])
print list_ele
调用函数read_ex_stop_PTline,输出结果如下图所示:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python读取txt某几列绘图的方法
晚上帮同学用Python脚本绘图,大概需求是读取一个txt文件的两列分别作为x和y的值,绘图即可,代码如下: #coding:utf-8 import numpy as np import matplotlib.pyplot as plt import pylab ## 绘制该文件中的数据 ## 需要引入pylab库,里面用到的函数和MATLAB里的非常类似 def plotData(x, y): length = len(y) pylab.figure(1) pylab.plot(x, y,
-
使用python获取csv文本的某行或某列数据的实例
站长用Python写了一个可以提取csv任一列的代码,欢迎使用.Github链接 csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格: 就可以存储为csv文件,文件内容是: No.,Name,Age,Score 1,Apple,12,98 2,Ben,13,97 3,Celia,14,96 4,Dave,15,95 假设上述csv文件保存为"A.csv",如何用Python像操作Excel一样提取其中的一列,即一个字段,利用Pyt
-
python读取txt文件并取其某一列数据的示例
菜鸟笔记 首先读取的txt文件如下: AAAAF110 0003E818 0003E1FC 0003E770 0003FFFC 90 AAAAF110 0003E824 0003E208 0003E76C 0003FFFC A5 AAAAF110 0003E814 0003E204 0003E760 0003FFFC 85 AAAAF110 0003E7F0 0003E208 0003E764 0003FFFC 68 AAAAF110 0003E7CC 0003E1FC 0003E758 000
-
使用python读取.text文件特定行的数据方法
如何用python循环读取下面.txt文件中,用红括号标出来的数据呢? 首先,观察数据可知,不同行的第一个数据元素不一样,所以考虑直接用正则表达式. 再加上,对读和写文件的操作,就行了 注:我用的是pycharm+python2.7 话不多说,直接上代码 import re f1=file('shen.txt','r') data1=f1.readlines() # print data1 f1.close() results = [] for line in data1: data2=line
-
利用Python读取txt文档的方法讲解
在G:/PythonPractise文件夹下新建一个名为record.txt的文本文档,写入如下图所示四行内容并保存. 打开python3的idle,开始写代码. 方法一代码和运行结果如下: 如上面运行结果所示,上面的结果是省略end=的写法,等价于end="\n"(回车); 下面的结果是end=""(空字符串)的写法,等价于end="\r"(换行) 方法二代码和运行结果如下: 方法三代码结果如下: 比较三种方法,方法一先将该路径下的文件返回成一
-
对python .txt文件读取及数据处理方法总结
1.处理包含数据的文件 最近利用Python读取txt文件时遇到了一个小问题,就是在计算两个np.narray()类型的数组时,出现了以下错误: TypeError: ufunc 'subtract' did not contain a loop with signature matching types dtype('<U3') dtype('<U3') dtype('<U3') 作为一个Python新手,遇到这个问题后花费了挺多时间,在网上找了许多大神们写的例子,最后终于解决了. 总
-
python 读取文本文件的行数据,文件.splitlines()的方法
一般跟踪训练的ground_truth的数据保存在文本文文件中,故每一行的数据为一张图片的标签数据,这个时候读取每一张图片的标签,具体实现如下: test_txt = '/home/zcm/tensorf/siamfc-tf-master/data/Biker/groundtruth.txt' def load_label_set(label_dir): label_folder = open(label_dir, "r") trainlines = label_folder.read
-

python读取各种文件数据方法解析
python读取.txt(.log)文件 ..xml 文件 .excel文件数据,并将数据类型转换为需要的类型,添加到list中详解 1.读取文本文件数据(.txt结尾的文件)或日志文件(.log结尾的文件) 以下是文件中的内容,文件名为data.txt(与data.log内容相同),且处理方式相同,调用时改个名称就可以了: 以下是python实现代码: # -*- coding:gb2312 -*- import json def read_txt_high(filename): with o
-
Python读取txt文件数据的方法(用于接口自动化参数化数据)
小试牛刀: 1.需要python如何读取文件 2.需要python操作list 3.需要使用split()对字符串进行分割 代码运行截图 : 代码(copy) #encoding=utf-8 #1.range中填写的数据 跟txt中行数保持一致 默认按照空格分隔 f_space = open(r"C:\Users\Administrator\Desktop\Space.txt","r") line_space = f_space.readlines() for i
-
python 读取.csv文件数据到数组(矩阵)的实例讲解
利用numpy库 (缺点:有缺失值就无法读取) 读: import numpy my_matrix = numpy.loadtxt(open("1.csv","rb"),delimiter=",",skiprows=0) 写: numpy.savetxt('2.csv', my_matrix, delimiter = ',') 可能遇到的问题: SyntaxError: (unicode error) 'unicodeescape' codec
-
python读取npy文件数据实例
目录 1. 读取与保存 2. 实战案例 附:python中 .npy文件的读写操作实例 总结 Numpy binary files (NPY, NPZ) 注:.npy文件是numpy专用的二进制文件. 1. 读取与保存 import numpy as np arr = np.array([[1, 2, 3], [4, 5, 6]]) np.save('weight.npy', arr) loadData = np.load('weight.npy') print("----type----&qu
-
使用Python读取大文件的方法
背景 最近处理文本文档时(文件约2GB大小),出现memoryError错误和文件读取太慢的问题,后来找到了两种比较快Large File Reading 的方法,本文将介绍这两种读取方法. 准备工作 我们谈到"文本处理"时,我们通常是指处理的内容.Python 将文本文件的内容读入可以操作的字符串变量非常容易.文件对象提供了三个"读"方法: .read()..readline() 和 .readlines().每种方法可以接受一个变量以限制每次读取的数据量,但它们
-
实例讲解python读取各种文件的方法
目录 1.yaml文件 2.CSV文件 3.ini文件 总结 1.yaml文件 # house.yaml-------------------------------------------------------------------------- # 1."数据结构"可以用类似大纲的"缩排"方式呈现 # 2.连续的项目通过减号"-"来表示,也可以用逗号来分割 # 3.key/value对用冒号":"来分隔 # 4.数组用
-
Python读取excel文件中的数据,绘制折线图及散点图
目录 一.导包 二.绘制简单折线 三.pandas操作Excel的行列 四.pandas处理Excel数据成为字典 五.绘制简单折线图 六.绘制简单散点图 一.导包 import pandas as pd import matplotlib.pyplot as plt 二.绘制简单折线 数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student. Python的表单数据如下所示: student的表单数据如下所示: 1.在利用pandas模块进行
-
Python读取CSV文件并进行数据可视化绘图
介绍:文件 sitka_weather_07-2018_simple.csv是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度.数据文件存储与data文件夹下,接下来用Python读取该文件数据,再基于数据进行可视化绘图.(详细细节请看代码注释) sitka_highs.py import csv # 导入csv模块 from datetime import datetime import matplotlib.pyplot as plt filename = 'd
-
python读取xml文件方法解析
关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码.这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python来读取xml文件. 什么是xml? xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言. abc.xml <?xml version="1.0" encoding="utf-8"?> <catalog> <maxid
-
Python实现读取TXT文件数据并存进内置数据库SQLite3的方法
本文实例讲述了Python实现读取TXT文件数据并存进内置数据库SQLite3的方法.分享给大家供大家参考,具体如下: 当TXT文件太大,计算机内存不够时,我们可以选择按行读取TXT文件,并将其存储进Python内置轻量级splite数据库,这样可以加快数据的读取速度,当我们需要重复读取数据时,这样的速度加快所带来的时间节省是非常可观的,比如,当我们在训练数据时,要迭代10万次,即要从文件中读取10万次,即使每次只加快0.1秒,那么也能节省几个小时的时间了. #创建数据库并把txt文件的数据存进