详解spring cloud分布式整合zipkin的链路跟踪
为什么使用zipkin?
上篇主要写了:spring cloud分布式日志链路跟踪
从上篇中可以看出服务之间的调用,假设现在有十几台服务,那么在查找日志的时候比较繁琐、复杂,而且在查看调用的时候也会像蜘蛛网一样,量太大。
这时候zipkin可以把链路调用整个过程给升级起来,只需要到一个地方去查找,就可以知道哪一步出错。
zipkin也分为服务器和客户端,服务器就是zipkin,微服务就是客户端。
首先,建立服务器zipkin
在此服务build.gradle加上zipkin的依赖:
compile 'io.zipkin.java:zipkin-server' compile 'io.zipkin.java:zipkin-autoconfigure-ui'
这里可以看到它不是属于spring中的
在application.yml配置中:
server: port: 9999 spring: application: name: zipkin-server #注册到注册中心的名字,可以映射ip
配置文件非常简单
启动类:
@EnableZipkinServer //表示Zipkin是服务器
@SpringBootApplication
public class ZipkinServerProdiver {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerProdiver.class,args);
}
}
接着在对于zipkin服务器的客户端build.gradle中加上依赖:
//表示zipkin的客户端 compile group: 'org.springframework.cloud', name: 'spring-cloud-sleuth-zipkin'
这里用到那几个zipkin的客户端就在里面加入依赖
当然在客户端配置文件application.yml中,也要加入zipkin的配置:
spring: zipkin: base-url: http://localhost:9999 #代表字zipkin服务器地址 sleuth: sampler: percentage: 1.0 #0.1-1.0 也就是代表链路跟踪的数据上传的概率有多大
启动zipkin服务器:http://localhost:9999
看到这样就证明启动成功啦
下面启动项目,执行微服务之间的调用,并刷新zipkin服务器:
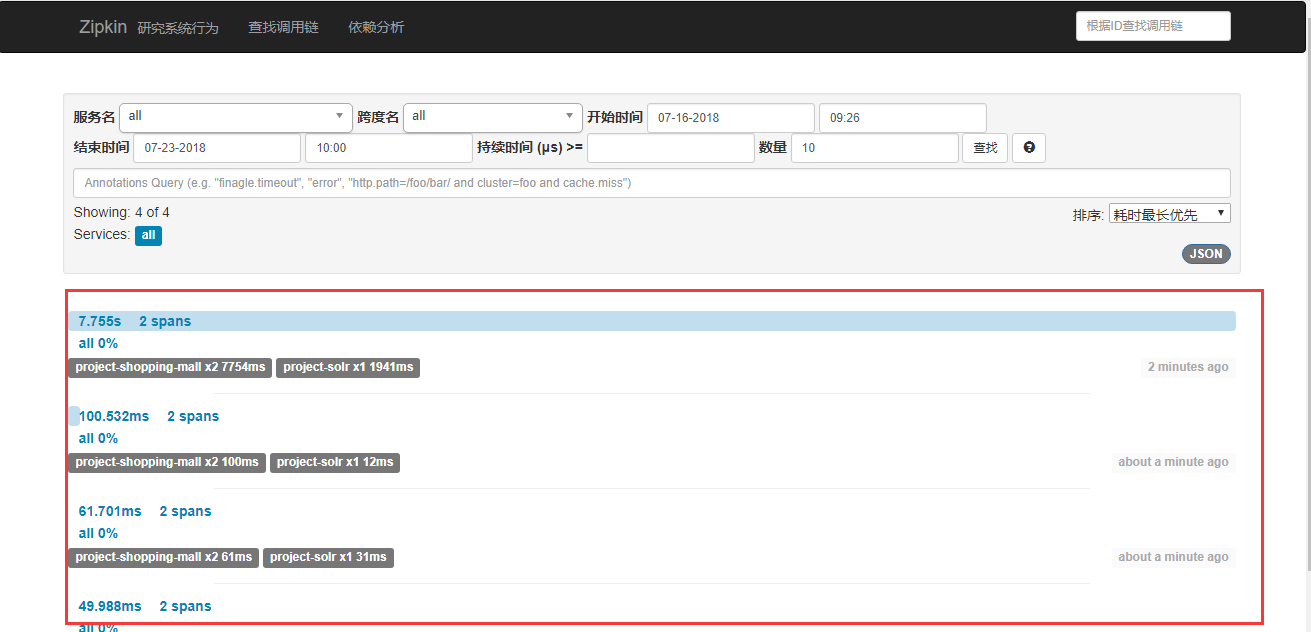
这里可以看到我执行了4次,出现了4个链路,我是根据时间来查找的,也可以根据控制台或日志中的链路编码来查找:

我在控制台随便拿一个进行查找:
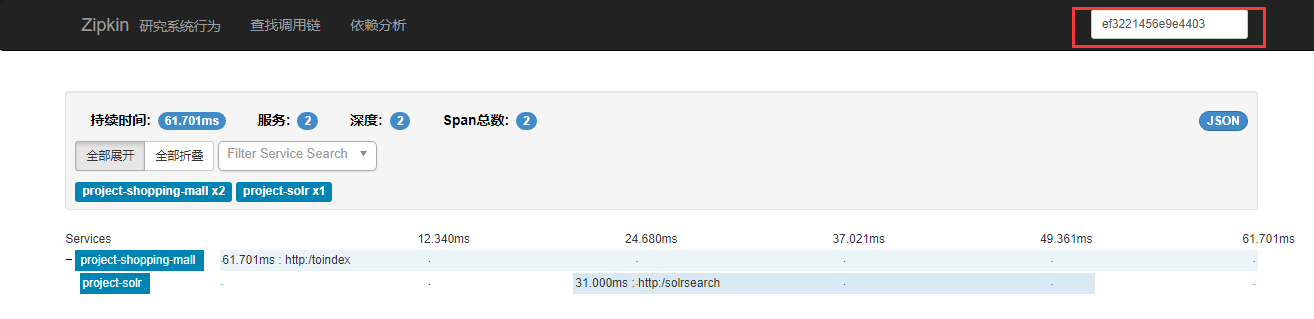
可以看到查找到了
zipkin也有链路分析:
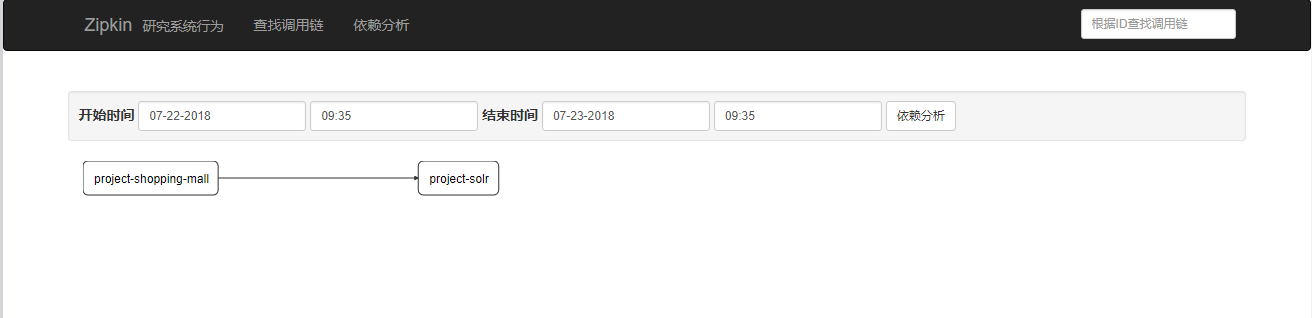
它也可以时间和链路编码来查找,这样我们想查找哪一时间段的或精准到哪一条就非常方便了
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

浅谈Spring-cloud 之 sleuth 服务链路跟踪
这篇文章主要讲述服务追踪组件zipkin,Spring Cloud Sleuth集成了zipkin组件. 一.简介 Add sleuth to the classpath of a Spring Boot application (see below for Maven and Gradle examples), and you will see the correlation data being collected in logs, as long as you are logging re
-
详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪? 当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错. 它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的. 基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护
-
详解spring cloud分布式整合zipkin的链路跟踪
为什么使用zipkin? 上篇主要写了:spring cloud分布式日志链路跟踪 从上篇中可以看出服务之间的调用,假设现在有十几台服务,那么在查找日志的时候比较繁琐.复杂,而且在查看调用的时候也会像蜘蛛网一样,量太大. 这时候zipkin可以把链路调用整个过程给升级起来,只需要到一个地方去查找,就可以知道哪一步出错. zipkin也分为服务器和客户端,服务器就是zipkin,微服务就是客户端. 首先,建立服务器zipkin 在此服务build.gradle加上zipkin的依赖: compil
-
详解spring cloud config整合gitlab搭建分布式的配置中心
在前面的博客中,我们都是将配置文件放在各自的服务中,但是这样做有一个缺点,一旦配置修改了,那么我们就必须停机,然后修改配置文件后再进行上线,服务少的话,这样做还无可厚非,但是如果是成百上千的服务了,这个时候,就需要用到分布式的配置管理了.而spring cloud config正是用来解决这个问题而生的.下面就结合gitlab来实现分布式配置中心的搭建.spring cloud config配置中心由server端和client端组成, 前提:在gitlab中的工程下新建一个配置文件config
-
详解spring cloud分布式关于熔断器
spring cloud分布式中,熔断器就是断路器,其实都是一个意思. 为什么要使用熔断器呢? 在分布式中,我们会根据业务或功能将项目拆分为多个服务单元,各个服务单元之间通过服务注册和订阅的方式相互依赖和调用功能,随着项目和业务的不断拓展,服务单元数量也逐渐增多,相互之间的依赖关系也越来越复杂,这时候,可能会某个服务单元出现问题或网络原因依赖调用出错或延迟,此时如果调用该依赖的请求不断增加,那么要调用该服务的服务将都会等待或者出现故障,如果后续连锁反应越来越多,Servlet容器的线程资源会被消
-
详解spring cloud整合Swagger2构建RESTful服务的APIs
前言 在前面的博客中,我们将服务注册到了Eureka上,可以从Eureka的UI界面中,看到有哪些服务已经注册到了Eureka Server上,但是,如果我们想查看当前服务提供了哪些RESTful接口方法的话,就无从获取了,传统的方法是梳理一篇服务的接口文档来供开发人员之间来进行交流,这种情况下,很多时候,会造成文档和代码的不一致性,比如说代码改了,但是接口文档没有改等问题,而Swagger2则给我们提供了一套完美的解决方案,下面,我们来看看Swagger2是如何来解决问题的. 一.引入Swag
-
详解spring cloud config实现datasource的热部署
关于spring cloud config的基本使用,前面的博客中已经说过了,如果不了解的话,请先看以前的博客 spring cloud config整合gitlab搭建分布式的配置中心 spring cloud config分布式配置中心的高可用 今天,我们的重点是如何实现数据源的热部署. 1.在客户端配置数据源 @RefreshScope @Configuration// 配置数据源 public class DataSourceConfigure { @Bean @RefreshScope
-
详解Spring cloud使用Ribbon进行Restful请求
写在前面 本文由markdown格式写成,为本人第一次这么写,排版可能会有点乱,还望各位海涵. 主要写的是使用Ribbon进行Restful请求,测试各个方法的使用,代码冗余较高,比较适合初学者,介意轻喷谢谢. 前提 一个可用的Eureka注册中心(文中以之前博客中双节点注册中心,不重要) 一个连接到这个注册中心的服务提供者 一个ribbon的消费者 注意:文中使用@GetMapping.@PostMapping.@PutMapping.@DeleteMapping等注解需要升级 spring
-
Spring Cloud Sleuth整合zipkin过程解析
这篇文章主要介绍了Spring Cloud Sleuth整合zipkin过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 SpringCloud Sleuth 简介 Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案. Spring Cloud Sleuth借鉴了Dapper的术语. Span:基本的工作单元.Span包括一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-va
-
详解spring cloud构建微服务架构的网关(API GateWay)
前言 在我们前面的博客中讲到,当服务A需要调用服务B的时候,只需要从Eureka中获取B服务的注册实例,然后使用Feign来调用B的服务,使用Ribbon来实现负载均衡,但是,当我们同时向客户端暴漏多个服务的时候,客户端怎么调用我们暴漏的服务了,如果我们还想加入安全认证,权限控制,过滤器以及动态路由等特性了,那么就需要使用Zuul来实现API GateWay了,下面,我们先来看下Zuul怎么使用. 一.加入Zuul的依赖 <dependency> <groupId>org.spri
-
详解spring cloud使用Hystrix实现单个方法的fallback
本文介绍了spring cloud-使用Hystrix实现单个方法的fallback,分享给大家,具体如下: 一.加入Hystrix依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> </dependency> 二.编写Controller package c