C++ OpenCV实战之文档照片转换成扫描文件
目录
- 一、背景
- 二、基础知识
- 三、方案一:自动检测点
- 1、读取图片文件(进行了指定尺寸缩放)
- 2、创建直线类并计算两条直线的交点
- 3、图像边缘检测Canny
- 4、通过霍夫变换进行直线检测
- 5、求单应性矩阵
- 6、降噪和二值化
- 四、方案二:用户点选目标区域
- 1、命令行解析
- 2、鼠标事件
- 3、主函数实现
- 4、结果展示
- 五、总结
一、背景
前段时间都是基于Python的OpecCV进行一些学习和实践,但小的知识点并没有应用到实际的项目中;并且基于Python的版本的移植性、效率性都较差,在包含硬件的项目中往往都是采用基于C++的版本;
因此本次项目实战专题主要是基于C++的版本,并且从大的任务中剖析小的知识点,实际项目中算法的选型也是比较难的部分,根据需求和任务选用不同的算法,这才是真的掌握了知识点;
本次项目是照片转扫描文件,可以参考下面网址中的案例:
这已经是一个落地且成熟的项目了,下面将结合多个知识点进行实现;
二、基础知识
首先需要明确实现该任务的几个步骤:
1、视角转换:不规则四边形转变为矩形(使用透视变换算法);
2、背景降噪:去掉图中的一些噪声点(使用中值滤波算法);
3、颜色变换:二值化图像,使得呈现黑白扫描图(使用自适应高斯阈值算法);
投影变换算法介绍:
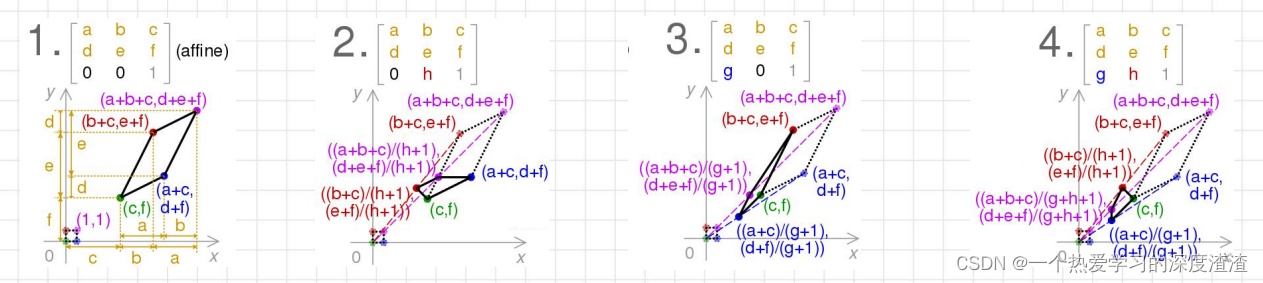
图1代表仿射变换,只需要6个自由度,并且约束条件是原来平行的线依旧平行,只需三对点对就可以求得未知参数值;
图4代表投影变换,需要四对点对,有8个自由度,可以将任意四边形变换为指定的四边形形状;
降噪算法介绍:
中值滤波算法示意图:

找到滑窗中中值的数,替换中间区域的数值;
原理上是将一些较亮、较暗的点进行降噪,也就是降噪的作用;
像高斯滤波和均值滤波,考虑到一个全局信息,是起到一个平滑的作用;
三、方案一:自动检测点
1、读取图片文件(进行了指定尺寸缩放)
// 读取图片
Mat readFile(String imagePath, int minEdge = 1080) {
Mat image = imread(imagePath);
int width = image.size().width;
int height = image.size().height;
int minline = min(width, height);
float ratio = minEdge * 1.0 / minline; // 得到缩放比例
int processWith = width * ratio;
int peocessHeight = height * ratio;
Mat resultImg; // 保存处理后图像
resize(image, resultImg, Size(processWith, peocessHeight));
return resultImg;
}
这里再定义一个显示图像的方法:
// 显示图片
void visualize(String winName, Mat image) {
namedWindow(winName, WINDOW_NORMAL);
imshow(winName, image);
waitKey(0);
}
2、创建直线类并计算两条直线的交点
先定义一个直线类,包含两个端点;
假设已知两条直线上的两点,怎么求得交点呢?
可以参考这个网址中的数学公式:https://en.wikipedia.org/wiki/Line%E2%80%93line_intersection
// 返回两条直线的交点
Point2f linesIntersect(Line lin1, Line lin2) {
// 这里直接根据网上的数学公式求得
int x1 = lin1.p1.x, y1 = lin1.p1.y;
int x2 = lin1.p2.x, y2 = lin1.p2.y;
int x3 = lin2.p1.x, y3 = lin2.p1.y;
int x4 = lin2.p2.x, y4 = lin2.p2.y;
float D = (x1 - x2) * (y3 - y4) - (y1 - y2) * (x3 - x4);
if (fabs(D) > 1e-6) {
return Point2f(
((x1 * y2 - y1 * x2) * (x3 - x4) - (x1 - x2) * (x3 * y4 - y3 * x4)) / D,
((x1 * y2 - y1 * x2) * (y3 - y4) - (y1 - y2) * (x3 * y4 - y3 * x4)) / D);
}
return Point2f(-1, -1);
}
3、图像边缘检测Canny
Mat canny, gray; cvtColor(image, gray, COLOR_BGR2GRAY); double threshold_low = threshold(gray, canny, 0, 255, THRESH_BINARY | cv::THRESH_OTSU); Canny(gray, canny, threshold_low, threshold_low * 2); return canny;

注意:进行Canny边缘检测的效果和图像的大小有关,可以适当对大图进行缩放;
4、通过霍夫变换进行直线检测
检测到的直线分为两类,一类是水平线,一类是竖直线;
为了得到外边缘框的直线,可以先根据直线的外接矩形长宽比分为水平和竖直线,再根据中点的位置,找到边缘直线;

如上图所示,如果x>y,则将该直线分为水平线,如果y>x,则将该直线划分为水平线;
随后再根据中心点的坐标大小确定边缘线;
// 进行霍夫直线检测,保存所有检测到的直线,并且确保直线大于4条
vector<Vec4i> lines;
// 这里的参数需要根据图像大小等因素进行微调
HoughLinesP(canny, lines, 1, CV_PI / 180, 80, height/5, 200);
if (lines.size() < 4) {
cout << "Find only" << lines.size() << "lines, return directly" << endl;
}
// 将直线分为水平线和垂直线
vector<Line> horizontals, verticals;
Mat tmp = image.clone();
for (auto v : lines) {
double w = fabs(v[0] - v[2]), h = fabs(v[1] - v[3]);
Line tmp_line(Point(v[0], v[1]), Point(v[2], v[3]));
if (w > h) horizontals.push_back(tmp_line);
else verticals.push_back(tmp_line);
// 下面两行代码是实现绘制直线
//line(tmp, Point(v.val[0], v.val[1]), Point(v.val[2], v.val[3]), Scalar(255, 0, 0), 8);
//visualize("hough test", tmp);
}
// 确保水平线和垂直线至少有两条
if (horizontals.size() < 2 || verticals.size() < 2) {
cout << "Not enough edge lines... " << endl;
}
// 将水平和垂直线按中心点位置进行排序,这里的两个排序函数需要自己实现
sort(horizontals.begin(), horizontals.end(), cmpHeight);
sort(verticals.begin(), verticals.end(), cmpWidth);
// 绘制出找到的直线
line(tmp, horizontals[0].p1, horizontals[0].p2, Scalar(255, 0, 0), 8);
line(tmp, horizontals[horizontals.size()-1].p1, horizontals[horizontals.size() - 1].p2, Scalar(255, 0, 0), 8);
line(tmp, verticals[0].p1, verticals[0].p2, Scalar(255, 0, 0), 8);
line(tmp, verticals[verticals.size()-1].p1, verticals[verticals.size() - 1].p2, Scalar(255, 0, 0), 8);
visualize("hough test", tmp);
排序函数的实现:
// 对水平线进行排序
bool cmpHeight(const Line& l1, const Line& l2) {
return l1.center.y < l2.center.y;
}
// 对垂直线进行排序
bool cmpWidth(const Line& l1, const Line& l2) {
return l1.center.x < l2.center.x;
}

5、求单应性矩阵
现在已知图像上目标的四个点坐标,通过点对关系,求得二者之间的单应性变换矩阵;
int dst_width = 1080, dst_height = 1920;
vector<Point2f> dst_pts;
dst_pts.push_back(Point(0, 0));
dst_pts.push_back(Point(dst_width - 1, 0));
dst_pts.push_back(Point(0, dst_height - 1));
dst_pts.push_back(Point(dst_width - 1, dst_height - 1));
Mat warpedImg = Mat::zeros(dst_height, dst_width, CV_8UC3);
Mat homo = getPerspectiveTransform(ori_pts, dst_pts);
warpPerspective(image, warpedImg, homo, warpedImg.size());
visualize("result", warpedImg);
结果图:

6、降噪和二值化
降噪采用中值滤波,阈值过滤采用自适应的二值化;
void postProcess(Mat& image) {
medianBlur(image, image, 7);
cvtColor(image, image, COLOR_BGR2GRAY);
threshold(image, image, 0, 255, THRESH_BINARY | cv::THRESH_OTSU);
}

四、方案二:用户点选目标区域
方案一是完全基于自动化的方式,用户只需要传入图像,程序会自动选择合适的区域;
优点在于其节省了用户的人工成本,使得程序更为简便;
缺点在于算法具有局限性,对背景及区域选取有要求,比如不能在区域外出现干扰物体,也无法满足用户的一些特别需求,比如选定大区域中的小区域;
方案二的优势在于其强大的灵活性,用户可以根据自己的需求选择相应的区域,程序将对所选区域进行转换;
1、命令行解析
加入命令行参数的功能,用户可以从命令行传入参数;
int main(int argc, char** argv)
{
const String keys =
"{help h usage ? | | print this message }"
"{path |D: / project / OpenCV / card.jpg| path to file }"
;
// 采用opencv命令行解析的方式
CommandLineParser myParser(argc, argv, keys);
String path = myParser.get<String>("path");
cout << path << endl;
}
2、鼠标事件
主要实现用户点击鼠标时的一些交互功能:
// 这几个参数为默认参数
void onMouse(int event, int x, int y, int flags, void* userdata) {
// 当点数为四个时,判断当前用户鼠标选取的拖动点是哪一个
if (srcPts.size() == 4) {
for (int i = 0; i < 4; i++) {
Point2f v = srcPts[i];
if ((event == EVENT_LBUTTONDOWN) & (abs(v.x - x) < 20) & (abs(v.y - y) < 20)) {
isDragging = true;
drag_index = i;
}
}
}
// 用户点击鼠标左键时,加入点
else if (event == EVENT_LBUTTONDOWN) {
srcPts.push_back(Point2f(x, y));
}
// 取消拖动
if (event == EVENT_LBUTTONUP) {
isDragging = false;
}
// 如果鼠标移动并且一直按着,就改变原来的点
if ((event == EVENT_MOUSEMOVE) && isDragging) {
srcPts[drag_index].x = x;
srcPts[drag_index].y = y;
}
}
3、主函数实现
定义了鼠标函数之后,需要将其中的操作在窗口进行展示:
namedWindow(winNameOri, WINDOW_NORMAL);
namedWindow(winNameRes, WINDOW_NORMAL);
setMouseCallback(winNameOri, onMouse, nullptr);
bool done = false;
while (!done) {
if (srcPts.size() < 4) {
img = oriImg.clone();
for (int i = 0; i < srcPts.size(); i++) {
circle(img, srcPts[i], 10, Scalar(255, 255, 0), 5);
putText(img, labels[i].c_str(), srcPts[i], FONT_HERSHEY_SIMPLEX, 1, Scalar(255, 255, 255), 2);
}
imshow(winNameOri, img);
}
if (srcPts.size() == 4) {
img = oriImg.clone();
for (int i = 0; i < 4; i++) {
circle(img, srcPts[i], 10, Scalar(255, 255, 0), 5);
line(img, srcPts[i], srcPts[(i + 1) % 4], Scalar(0, 255, 0), 5);
putText(img, labels[i].c_str(), srcPts[i], FONT_HERSHEY_SIMPLEX, 1, Scalar(255, 255, 255), 2);
}
imshow(winNameOri, img);
}
4、结果展示
后面的求取单应性矩阵以及降噪和二值化同方案一一致,在这里就不进行展示了;
结果图:

五、总结
本次项目是基于C++实现的,后续我也用Python进行了代码的转换,但在直线检测部分用相同函数却得到不同的效果,这个问题还没有进行解决;
采用C++进行编写代码,能够对整个项目的每个变量以及流程更加熟悉,本次项目可以说是一个多个知识点的集合项目,不仅仅包含边缘检测、直线检测、图像变换等,其中也有很多值得思考的小点;
以上就是C++ OpenCV实战之文档照片转换成扫描文件的详细内容,更多关于C++ OpenCV照片转扫描文件的资料请关注我们其它相关文章!
相关推荐
-

C++ OpenCV实现之实现红绿灯识别
目录 前言 一.轮廓识别相关原理 什么是轮廓检测 轮廓提取函数findContours 二.案例实现 Step1:初始化配置 Step2:进行帧处理 Step3:膨胀腐蚀处理 Step4:红绿灯提示判断 Step5:轮廓提取 Step6:判断是否相交 完整代码 三.总结 前言 本文以实现行车过程当中的红绿灯识别为目标,核心的内容包括:OpenCV轮廓识别原理以及OpenCV红绿灯识别的实现具体步骤 一.轮廓识别相关原理 什么是轮廓检测 目前轮廓检测方法有两类,一类是利用传统的边缘检测算子检测目标
-
C++ OpenCV实战之手写数字识别
目录 前言 一.准备数据集 二.KNN训练 三.模型预测及结果显示 四.源码 总结 前言 本案例通过使用machine learning机器学习模块进行手写数字识别.源码注释也写得比较清楚啦,大家请看源码注释!!! 一.准备数据集 原图如图所示:总共有0~9数字类别,每个数字共20个.现在需要将下面图片切分成训练数据图片.测试数据图片.该图片尺寸为560x280,故将其切割成28x28大小数据图片.具体请看源码注释. const int classNum = 10; //总共有0~9个数字类别
-
C++ OpenCV实战之零部件的自动光学检测
目录 一.背景 二.基础知识 三.代码实现 1.实现多窗口展示 2.降噪处理 3.背景去除 4.连通图实现 5.计算连通域面积 6.轮廓检测 四.总结 一.背景 首先任务背景是AOI(自动光学检测) 最重要的目的在于:将前景和物体进行分割与分类: 场景示意图: 需要注意,在螺母的传送带上,需要有前光和背光,给物体打光才能够拍摄清晰的图像: 二.基础知识 首先分为以下几步: 1.噪声抑制(预处理) 2.背景移除(分割) 3.二值化 4.连通域.轮廓查找算法 降噪算法 先使用中值滤波对椒盐噪声进行过
-
C++ OpenCV实战之手势识别
目录 前言 一.手部关键点检测 1.1 功能源码 1.2 功能效果 二.手势识别 2.1算法原理 2.2功能源码 三.结果显示 3.1功能源码 3.2效果显示 四.源码 总结 前言 本文将使用OpenCV C++ 实现手势识别效果.本案例主要可以分为以下几个步骤: 1.手部关键点检测 2.手势识别 3.效果显示 接下来就来看看本案例具体是怎么实现的吧!!! 一.手部关键点检测 如图所示,为我们的手部关键点所在位置.第一步,我们需要检测手部21个关键点.我们使用深度神经网络DNN模块来完成这件事.
-
C++ OpenCV实战之标记点检测的实现
在实际应用中,能够直接利用霍夫圆检测这些理想方法的应用场景是非常少的,更多的是利用拟合的办法去寻找圆形. 大致思路如下,首先先选择要处理的ROI部分,记录下该图的左上点在原图的坐标,如果原图过大,要先进行等比例缩放:然后利用自适应阈值和Canny边缘提取进行处理,再进行闭运算与轮廓检测,计算点集面积,通过筛选面积阈值去除杂点,最后进行轮廓检测,拟合椭圆,效果如下: 1.导入原图: 2.截取ROI 3.进行自适应阈值化与Canny边缘提取 4.进行闭运算,然后轮廓检测,然后计算点集面积,通过面积阈
-
C++ OpenCV实战之形状识别
目录 前言 一.图像预处理 二.形状识别 三.源码 四.结果显示 总结 前言 本案例通过使用OpenCV中的approxPolyDP进行多边形近似,进而进行基础形状识别(圆.三角形.矩形.星形…).下面就一起来看看具体是如何实现的吧. 一.图像预处理 原图如图所示: 首先第一步先进行图像预处理,得到二值图像. Mat gray; cvtColor(src, gray, COLOR_BGR2GRAY); Mat gaussian; GaussianBlur(gray, gaussian, Size
-
C++ OpenCV实战之文档照片转换成扫描文件
目录 一.背景 二.基础知识 三.方案一:自动检测点 1.读取图片文件(进行了指定尺寸缩放) 2.创建直线类并计算两条直线的交点 3.图像边缘检测Canny 4.通过霍夫变换进行直线检测 5.求单应性矩阵 6.降噪和二值化 四.方案二:用户点选目标区域 1.命令行解析 2.鼠标事件 3.主函数实现 4.结果展示 五.总结 一.背景 前段时间都是基于Python的OpecCV进行一些学习和实践,但小的知识点并没有应用到实际的项目中:并且基于Python的版本的移植性.效率性都较差,在包含硬件的项目
-
python 循环读取txt文档 并转换成csv的方法
如下所示: # -*- coding: utf-8 -*- """ Created on Fri Jul 29 15:49:06 2016 @author: user """ import os #从文件中读取某一行 linecache.checkcache可以刷新cache ,linecache可以缓存某一行的信息 import linecache def GetFileNameAndExt(filename): (filepath,tempf
-
opencv python简易文档之图像处理算法
目录 将图片转为灰度图 HSV 图像阈值 图像平滑 形态学-腐蚀操作 形态学-膨胀操作 开运算与闭运算 梯度运算 礼帽与黑帽 图像梯度处理 Canny边缘检测 图像金字塔 图像轮廓 直方图 直方图均衡化: 自适应均衡化: 傅里叶变换 模板匹配 总结 上一篇已经给大家介绍了opencv python图片基本操作的相关内容,这里继续介绍图像处理算法,下面来一起看看吧 将图片转为灰度图 import cv2 #opencv读取的格式是BGR img=cv2.imread('cat.jpg') # 将图
-
OpenCV实现彩色照片转换成素描卡通片
本文实例为大家分享了OpenCV实现彩色照片转换成素描卡通片的具体代码,供大家参考,具体内容如下 #include"stdafx.h" //#include<cv.h> //#include<highgui.h> #include <opencv2/highgui/highgui.hpp> #include <opencv2/imgproc/imgproc.hpp> #include <opencv2/core/core.hpp&g
-
opencv python简易文档之图片基本操作指南
前言 最近在学习opencv,使用的是python接口.于是想着写些相关的笔记供以后参考,有不足之处希望大家指出. 使用python学习opencv需要下载opencv第三方库. 使用pip安装即可. 安装命令: pip install opencv-python pip install opencv-contrib-python(opencv的贡献库) 引入opencv import cv2 读取图片: img=cv2.imread('cat.jpg') # cat.jpg路径为相对路径 #
-
python实现word文档批量转成自定义格式的excel文档的思路及实例代码
支持按照文件夹去批量处理,也可以单独一个文件进行处理,并且可以自定义标识符 最近在开发一个答题类的小程序,到了录入试题进行测试的时候了,发现一个问题,试题都是word文档格式的,每份有100题左右,拿到的第一份试题,光是段落数目就有800个.而且可能有几十份这样的试题. 而word文档是没有固定格式的,想批量录入关系型数据库mysql,必须先转成excel文档.这个如果是手动一个个粘贴到excel表格,那就头大了. 我最终需要的excel文档结构是这样的:每道题独立占1行,每1列是这道题的一项内
-
python实现将html表格转换成CSV文件的方法
本文实例讲述了python实现将html表格转换成CSV文件的方法.分享给大家供大家参考.具体如下: 使用方法:python html2csv.py *.html 这段代码使用了 HTMLParser 模块 #!/usr/bin/python # -*- coding: iso-8859-1 -*- # Hello, this program is written in Python - http://python.org programname = 'html2csv - version 20
-
C#中将DataTable转换成CSV文件的方法
DataTable用于在.net项目中,用于缓存数据,DataTable表示内存中数据的一个表.CSV文件最早用在简单的数据库里,由于其格式简单,并具备很强的开放性,所以起初被扫图家用作自己图集的标记.CSV文件是个纯文本文件,每一行表示一张图片的许多属性. 在.net项目中运用C#将DataTable转化为CSV文件,现在提供一个较为通用的方法,具体代码如下: /// <summary> /// 将DataTable转换成CSV文件 /// </summary> /// <
-
用python把ipynb文件转换成pdf文件过程详解
这两天一直在做课件,我个人一直不太喜欢PPT这个东西--能不用就不用,我个人特别崇尚极简风. 谁让我们是程序员呢,所以就爱上了Jupyter写课件,讲道理markdown也是个非常不错的写书格式啊. 安装Jupyter其实非常简单,你会python就应该会用jupyter,起码简单的 pip install jupyter, jupyter notebook 要会对伐- 好那接下来就是使用jupyter了,启动jupyter后,使用浏览器访问相应IP:Port就可以使用了.没错,jupyter就
-
python3如何将docx转换成pdf文件
本文实例为大家分享了python3将docx转换成pdf文件的具体代码,供大家参考,具体内容如下 直接上代码 # -*- encoding:utf-8 -*- """ author:lgh """ from win32com.client import Dispatch, constants, gencache def doc2pdf(input, output): w = Dispatch('Word.Application') try: #