python做图片搜索引擎并保存到本地详情
前言
我们先说一下思路:先对目标网站发送请求,获取html源码,然后对源码里面的所以图片链接进行筛选,然后再次对图片链接发送请求,然后保存。
思路大致是这样,话不多说,直接上代码:
用到的模块:
import requests #请求库 第三方库,需要安装: pip install requests import re #筛选库,py自带,无需安装
查找接口:
打开F12打开开发者工具,点击网络、Fetch/XHR、载荷、依次点下去,可以看到查询参数有两个,分别是:word:风景图 queryWord:风景图
我们可以利用这两个查询参数进行自定义:
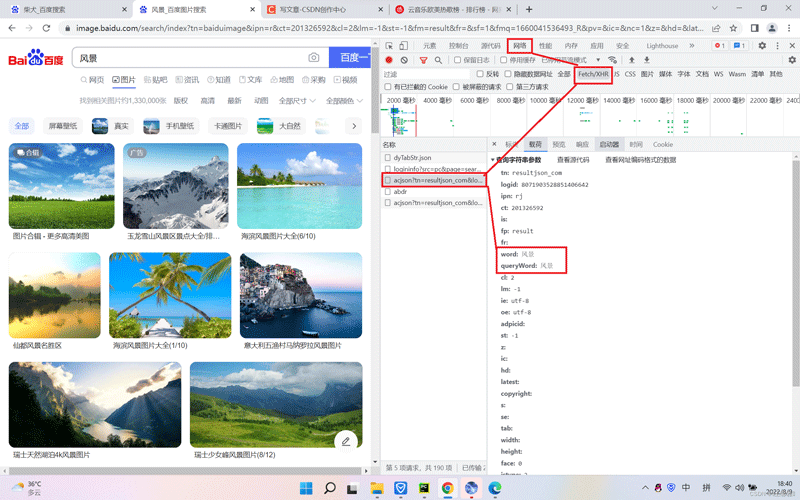
我们要查找到真实的url地址,然后对url查询参数自定义,点击旁边的标头,我们看见了刚才的查询参数:word 和queryWord这两个参数,
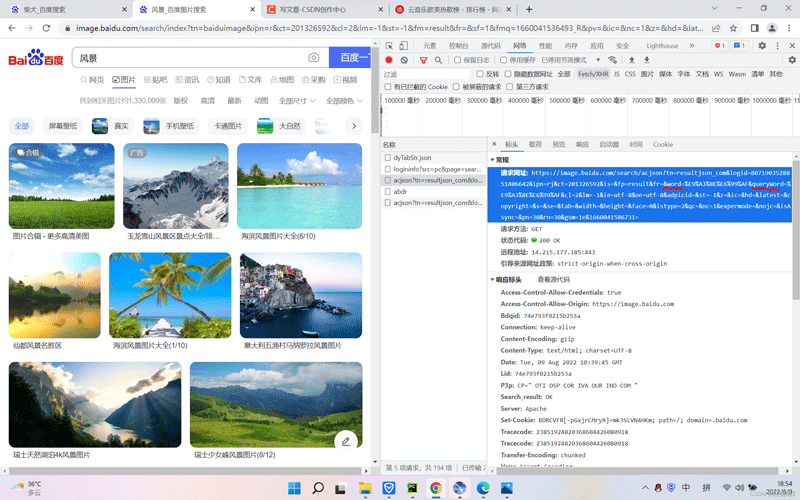
接下来,我们使用让用户输入参数值,然后进行传参到url地址里面的word和queryWord参数,
那么word和queryWord参数,url地址里面就不能有了值了,使用{}被传参,后面使用format函数对输入的参数进行传参{},最后形成我们需要的网址
word = input('请输入要搜索的图片:')
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=5853806806594529489&ipn=rj&ct=201326592&is=&fp=result&fr=ala&word={}&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1658411978178='.format(word, word)
print(url) 打开网址就是你输入的内容
下一步我们要对请求头进行伪装,防止被服务器识别为爬虫程序
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'}
判断该文件夹是否存在,存在则创建,不存在则覆盖;发送请求并打印源码
if not os.path.exists(files): #假如没有文件执行以下代码:
os.makedirs(files) #有文件夹则覆盖,没有则创建
req=requests.get(url=url,headers=headers).text #获取源码
print(req) #输出源码
正则式:
res='"thumbURL":"(.*?)"' #正则式 zhengze=re.findall(res,req) #调用findall函数进行匹配
遍历url地址并发送请求
i=1 #计数
for a in zhengze: #遍历刷选后的网址 get_image(a,i) #将遍历后的url地址传到get-image这个函数
i+=1 #每执行一次加1
print(a) #打印地址
response=requests.get(url=a,headers=headers).content #获取二进制文件
设置保存类型及保存位置
file=files+word+str(i)+'张.jpg' #设置 文件夹 路径+文件名以及类型 (完整地址)
with open(file,'wb') as f: #写二级制文件类型,并修改变量名
f.write(response) #把获取到的二进制文件写入
print(word+str(i)+'张.jpg''保存成功') #提示保存成功
那么接下来奉上完整源码:
import re #筛选url
import requests #请求
import os #创建文件夹
word = input('请输入要搜索的图片:')
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=5853806806594529489&ipn=rj&ct=201326592&is=&fp=result&fr=ala&word={}&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1658411978178='.format(word, word)
#伪装浏览器
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'}
files='D:/{}/'.format(word) #创建文件夹路径
if not os.path.exists(files): #假如没有文件执行以下代码:
os.makedirs(files) #有文件夹则覆盖,没有则创建
req=requests.get(url=url,headers=headers).text #获取源码
res='"thumbURL":"(.*?)"' #正则式
zhengze=re.findall(res,req) #筛选
i=1 #计数
for a in zhengze: #遍历刷选后的网址 get_image(a,i) #将遍历后的url地址传到get-image这个函数
i+=1 #每执行一次加1
print(a) #打印地址
response=requests.get(url=a,headers=headers).content #获取二进制文件
file=files+word+str(i)+'张.jpg' #设置 文件夹 路径+文件名以及类型 (完整地址)
with open(file,'wb') as f: #写二级制文件类型,并修改变量名
f.write(response) #把获取到的二进制文件写入
print(word+str(i)+'张.jpg''保存成功') #提示保存成功
我们来看看运行结果怎么样:
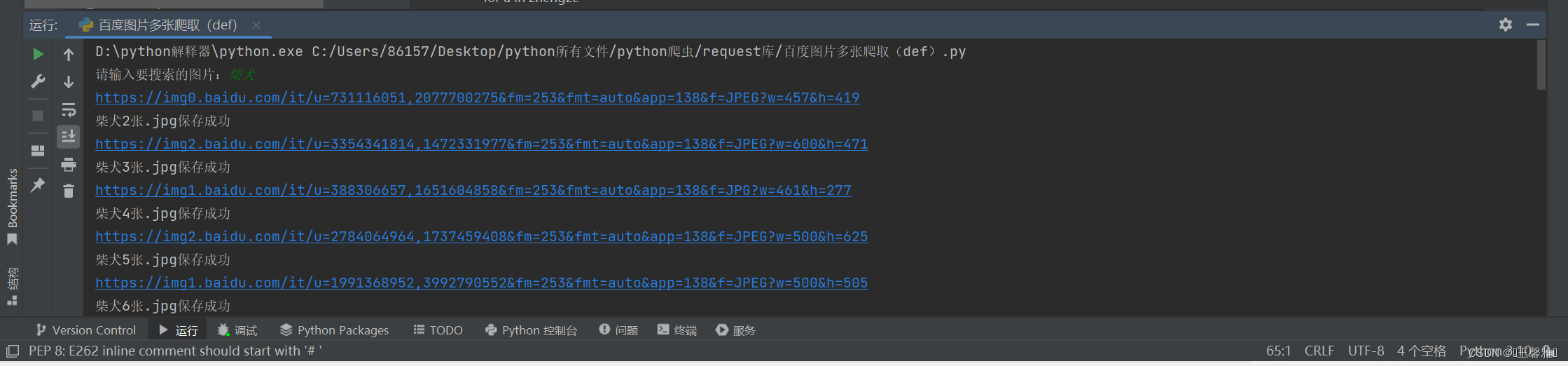
可以看到我搜索的是柴犬,对源码中的每个图片链接进行发送并保存。
那我保存的图片是否是柴犬呢?我们看看吧:
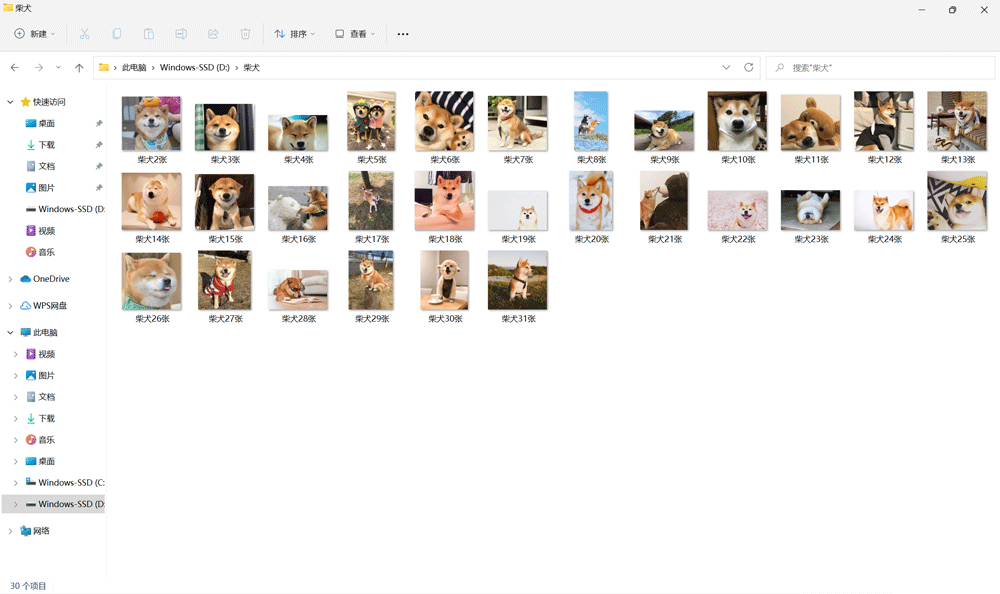
可以看到保存的就是柴犬图片并且创建了一个文件夹!
到此这篇关于python做图片搜索引擎并保存到本地详情的文章就介绍到这了,更多相关python图片搜索引擎内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

10分钟用Python快速搭建全文搜索引擎详解流程
有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个 代码所在 Git:https://github.com/asciimoo/searx 官方很贴心,很方便的是已经提供了docker 镜像,基本pull下来就可以很方便的使用了,执行命令 cid=$(sudo docker ps -a | grep searx | awk '{print $1}') echo searx cid is $cid if [ "$cid" != "" ];then su
-
Python大批量搜索引擎图像爬虫工具详解
python图像爬虫包 最近在做一些图像分类的任务时,为了扩充我们的数据集,需要在搜索引擎下爬取额外的图片来扩充我们的训练集.搞人工智能真的是太难了
-
Python搜索引擎实现原理和方法
如何在庞大的数据中高效的检索自己需要的东西?本篇内容介绍了Python做出一个大数据搜索引擎的原理和方法,以及中间进行数据分析的原理也给大家做了详细介绍. 布隆过滤器 (Bloom Filter) 第一步我们先要实现一个布隆过滤器. 布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素.也就是说如果一个要搜索的词并不存在与我的数据中,那么它可以以很快的速度返回目标不存在. 让我们看看以下布隆过滤器的代码: class Bloomfilter(object): ""&
-
用python做一个搜索引擎(Pylucene)的实例代码
1.什么是搜索引擎? 搜索引擎是"对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集.信息整理和用户查询三部分".如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫):然后信息整理模块对采集的信息进行分词.去停用词.赋权重等操作后建立索引表(一般是倒排索引)构成索引库:最后用户查询模块就可以识别用户的检索需求并提供检索服务啦. 图1 搜索引擎的一般结构 2. 使用python实现一个简单搜索引擎 2.1 问题分析 从图1看,一个完整的搜索
-
以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
在这篇文章中,我们将分析一个网络爬虫. 网络爬虫是一个扫描网络内容并记录其有用信息的工具.它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,然后对其他网页进行同样的操作. 如果爬虫正在分析的网页中有一些链接,那么爬虫将会根据这些链接分析更多的页面. 搜索引擎就是基于这样的原理实现的. 这篇文章中,我特别选了一个稳定的."年轻"的开源项目pyspider,它是由 binux 编码实现的. 注:据认为pyspider持续监控网络,它假定网页在一
-
Python实战之手写一个搜索引擎
一.前言 这篇文章,我们将会尝试从零搭建一个简单的新闻搜索引擎 当然,一个完整的搜索引擎十分复杂,这里我们只介绍其中最为核心的几个模块 分别是数据模块.排序模块和搜索模块,下面我们会逐一讲解,这里先从宏观上看一下它们之间的工作流程 二.工作流程 三.数据模块 数据模块的主要作用是爬取网络上的数据,然后对数据进行清洗并保存到本地存储 一般来说,数据模块会采用非定向爬虫技术广泛爬取网络上的数据,以保证充足的数据源 但是由于本文只是演示,所以这里我们仅会采取定向爬虫爬取中国社会科学网上的部分文章素材
-
Python中使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索需要进行中文分词,使用jieba. 直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立.搜索解析等细节问题. haystack支持多种搜索引擎,不仅仅是whoosh,使用solr.elas
-
浅谈用Python实现一个大数据搜索引擎
搜索是大数据领域里常见的需求.Splunk和ELK分别是该领域在非开源和开源领域里的领导者.本文利用很少的Python代码实现了一个基本的数据搜索功能,试图让大家理解大数据搜索的基本原理. 布隆过滤器 (Bloom Filter) 第一步我们先要实现一个布隆过滤器. 布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素.也就是说如果一个要搜索的词并不存在与我的数据中,那么它可以以很快的速度返回目标不存在. 让我们看看以下布隆过滤器的代码: class Bloomfilter(
-
Python无损音乐搜索引擎实现代码
研究了一段时间酷狗音乐的接口,完美破解了其vip音乐下载方式,想着能更好的追求开源,故写下此篇文章,本文仅供学习参考.虽然没什么技术含量,但都是自己一点一点码出来,一点一点抓出来的. 一.综述: 根据酷狗的搜索接口以及无损音乐下载接口,做出爬虫系统.采用flask框架,前端提取搜索关键字,后端调用爬虫系统采集数据,并将数据前端呈现: 运行环境:windows/linux python2.7 二.爬虫开发: 通过抓包的方式对酷狗客户端进行抓包,抓到两个接口: 1.搜索接口: http://son
-
python基于搜索引擎实现文章查重功能
前言 文章抄袭在互联网中普遍存在,很多博主都收受其烦.近几年随着互联网的发展,抄袭等不道德行为在互联网上愈演愈烈,甚至复制.黏贴后发布标原创屡见不鲜,部分抄袭后的文章甚至标记了一些联系方式从而使读者获取源码等资料.这种恶劣的行为使人愤慨. 本文使用搜索引擎结果作为文章库,再与本地或互联网上数据做相似度对比,实现文章查重:由于查重的实现过程与一般情况下的微博情感分析实现流程相似,从而轻易的扩展出情感分析功能(下一篇将在此篇代码的基础上完成数据采集.清洗到情感分析的整个过程). 由于近期时间上并不充