MySQL中order by排序语句的原理解析
order by 是怎么工作的?
表定义
CREATE TABLE `t1` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`)) ENGINE=InnoDB;
SQL语句可以这样写:
select city,name,age from t1 where city='杭州' order by name limit 1000
全字段排序
用 explain 命令来看看这个语句的执行情况。

其中Using index condition是索引下推优化(索引下推简介),Using filesort 表示的就是需要排序,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
city索引的示意图。

从图中可以看到,满足 city='杭州’条件的行,是从 ID_X 到 ID_(X+N) 的这些记录。
通常情况下,这个语句执行流程如下所示 :
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;
- 按照排序结果取前 1000 行返回给客户端。
这个是它的排序过程,叫做全字段排序,执行流程示意图如下所示。
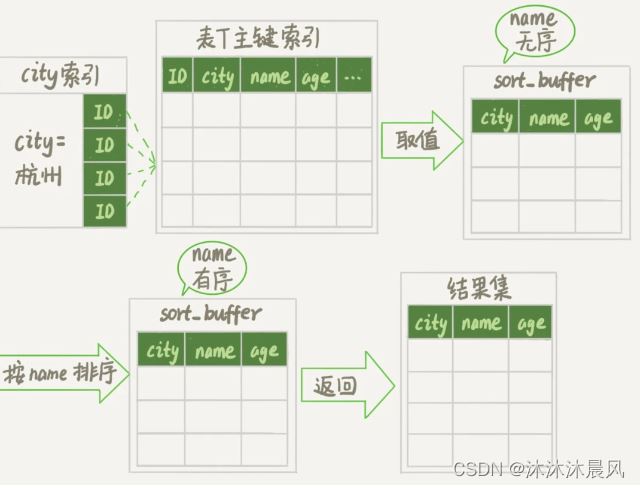
按 name 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。
- 要排序的数据量小于 sort_buffer_size,排序就在内存中完成。
- 要排序数据量太大,内存放不下,利用磁盘临时文件辅助排序。
可以用下面介绍的方法,来确定一个排序语句是否使用了临时文件。
/* 打开optimizer_trace,只对本线程有效 */ SET optimizer_trace='enabled=on'; /* @a保存Innodb_rows_read的初始值 */ select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 执行语句 */ select city, name,age from t where city='杭州' order by name limit 1000; /* 查看 OPTIMIZER_TRACE 输出 */ SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G /* @b保存Innodb_rows_read的当前值 */ select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 计算Innodb_rows_read差值 */ select @b-@a;
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files 中看到是否使用了临时文件。

number_of_tmp_files 表示的是,排序过程中使用的临时文件数。
为什么需要12个文件呢?
外部排序一般使用归并排序算法。可以这么简单理解,MySQL 将需要排序的数据分成 12 份,每一份单独排序(快速排序)后存在这些临时文件中。然后把这 12 个有序文件再合并成一个有序的大文件。
小结:
如果 sort_buffer_size 超过了需要排序的数据量的大小,number_of_tmp_files 就是 0,表示排序可以直接在内存中完成。sort_buffer_size 越小,需要分成的份数越多,number_of_tmp_files 的值就越大。
rowid排序
在上面这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
如果当行很大,这个全字段排序并不是很好。
SET max_length_for_sort_data = 16;
这个语句的意思是:如果单行太大,超过所设定的数值的时候,比如现在是超过16,MySQL就认为单行太大,换一种算法。
city、name、age 这三个字段的定义总长度是 36,我把 max_length_for_sort_data 设置为 16。
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
但这时,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了(最后收集结果之前要回表),整个执行流程就变成如下所示的样子:
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city='杭州’条件为止,也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
这个执行流程的示意图如下,叫做 rowid 排序。
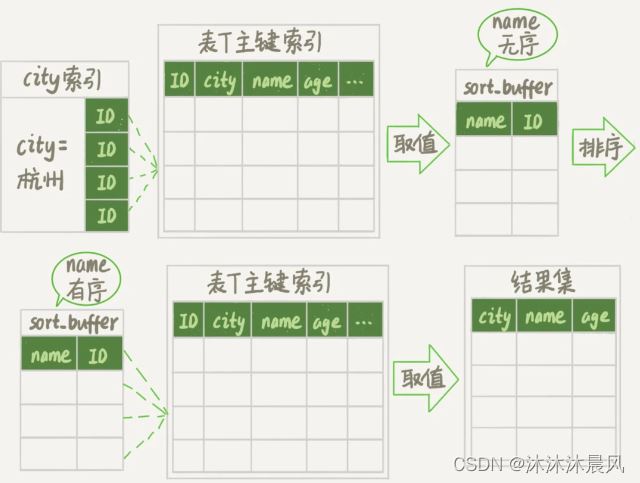
对比全字段排序流程图发现,rowid 排序多访问了一次表 t 的主键索引,就是步骤 7。
注意:最后的**“结果集”是一个逻辑概念,实际上 MySQL 服务端从排序后的 sort_buffer 中依次取出 id,然后到原表查到 city、name 和 age 这三个字段的结果,不需要在服务端再耗费内存存储结果,是直接返回给客户端的**。
全字段排序和rowid排序应该如何去选择呢?
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
其实以上说的都是无序的时候,如果在条件有索引,索引中数据是有序的,省掉了上述步骤,直接在索引上找到主键id,然后回表找到要查找的数据直接返回给客户端。
到此这篇关于MySQL中order by排序语句的原理的文章就介绍到这了,更多相关MySQL中order by排序语句的原理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Mysql排序和分页(order by&limit)及存在的坑
排序查询(order by) 电商中:我们想查看今天所有成交的订单,按照交易额从高到低排序,此时我们可以使用数据库中的排序功能来完成. 排序语法: select 字段名 from 表名 order by 字段1 [asc|desc],字段2 [asc|desc]; 需要排序的字段跟在order by之后: asc|desc表示排序的规则,asc:升序,desc:降序,默认为asc: 支持多个字段进行排序,多字段排序之间用逗号隔开. 单字段排序 mysql> create table test2(
-

详解MySQL中Order By排序和filesort排序的原理及实现
目录 1.Order By原理 2.filesort排序算法 3.优化排序 1.Order By原理 MySQL的Order By操作用于排序,并且会有多种不同的排序算法,他们的性能都是不一样的. 假设有一个表,建表的sql如下: CREATE TABLE `obtest` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `a` VARCHAR ( 100 ) NOT NULL, `b` VARCHAR ( 100 ) NOT NULL, `c` VARCHAR (
-
mysql和oracle默认排序的方法 - 不指定order by
目录 先说结论 1. innoDB引擎 1.1 创建表,id类型为字符串 1.2 插入数据,并查询 1.3 创建表,id字段类型为int 1.4 插入数据,并查询 1.5 结论 2. myISAM引擎 2.1 创建表, id类型为字符串 2.2 插入数据,并查询 2.3 创建表,id字段类型为int 2.4 插入数据,并查询 2.5 结论 先说结论 1. oracle: oracle 默认没有排序规则 2. mysql 2.1 innoDB引擎: 默认查询按照id正序排序 2.2 myISAM引
-
MySQL中Order By多字段排序规则代码示例
说在前面 突发奇想,想了解一下mysql order by排序是以什么规则进行的? 好了,话不多说,直接进入正题吧. MySql order by 单字段 建一测试表如下: CREATE TABLE `a` ( `code` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT into a values('中一', '我'); INSERT
-
MySQL查询优化:连接查询排序limit(join、order by、limit语句)介绍
不知道有没有人碰到过这样恶心的问题:两张表连接查询并limit,SQL效率很高,但是加上order by以后,语句的执行时间变的巨长,效率巨低. 情况是这么一个情况:现在有两张表,team表和people表,每个people属于一个team,people中有个字段team_id. 下面给出建表语句: 复制代码 代码如下: create table t_team ( id int primary key, tname varchar(100) ); create table t_people (
-
MySQL利用索引优化ORDER BY排序语句的方法
创建表&创建索引 create table tbl1 ( id int unique, sname varchar(50), index tbl1_index_sname(sname desc) ); 在已有的表创建索引语法 create [unique|fulltext|spatial] index 索引名 on 表名(字段名 [长度] [asc|desc]); MySQL也能利用索引来快速地执行ORDER BY和GROUP BY语句的排序和分组操作. 通过索引优化来实现MySQL的ORDER
-
MySQL数据库索引order by排序精讲
排序这个词,我的第一感觉是几乎所有App都有排序的地方,淘宝商品有按照购买时间的排序.B站的评论有按照热度排序的... 对于MySQL,一说到排序,你第一时间想到的是什么?关键字order by?order by的字段最好有索引?叶子结点已经是顺序的?还是说尽量不要在MySQL内部排序? 事情的起因 现在假设有一张用户的朋友表: CREATE TABLE `user` ( `id` int(10) AUTO_INCREMENT, `user_id` int(10), `friend_addr`
-
MySQL中order by排序语句的原理解析
order by 是怎么工作的? 表定义 CREATE TABLE `t1` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`)) ENGINE=InnoDB; SQL语句可以这样写: se
-
解决mybatis中order by排序无效问题
1.#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号.如:order by #{user_id},如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id". 2.$将传入的数据直接显示生成在sql中.如:order by ${user_id},如果传入的值是111,那么解析成sql时的值为order by 111, 如果传入的值是id,则解析成的sql为order b
-
MySQL中order by的使用详情
目录 1.简介 2.正文 2.1 单个列排序 2.2 多个列排序 2.3 排序的方式 2.4 order by结合limit 1.简介 在使用select语句时可以结合order by对查询的数据进行排序.如果不使用order by默认情况下MySQL返回的数据集,与它在底层表中的顺序相同,可能与你添加数据到表中的顺序一致,也可能不一致(在你对表进行修改.删除等操作时MySQL会对内存进行整理,此时数据的顺序会发生改变)因此如果我们希望得到的数据是有顺序的,就应该明确排序方式. 2.正文 首先准
-
MySQL中order by的执行过程
目录 一 .测试数据 二. 全字段排序 三.rowid 排序 四.全字段排序 与 rowid 排序 比较 前言: 在开发过程中,一定会经常碰到需要根据指定的字段排序来显示结果的需求.还是以前文的订单表为例,假设查询“张三”的所有订单,并且按照订单价格排序返回前 1000 个订单号以及价格. 一 .测试数据 测试的这个订单表my_order的结构是这样的: CREATE TABLE `my_order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `oid` v
-
深入了解MySQL中索引优化器的工作原理
目录 本文导读 一.MySQL 优化器是如何选择索引的 1.MySQL数据库组成 2.MySQL数据库成本计算 二.MySQL查询成本 三.SELECT 执行过程 总结 本文导读 本文将解读MySQL数据库查询优化器(CBO)的工作原理.简单介绍了MySQL Server的组成,MySQL优化器选择索引额原理以及SQL成本分析,最后通过 select 查询总结整个查询过程. 一.MySQL 优化器是如何选择索引的 下面我们来看这张表,SUB_ODR_ID字段创建了相关的 2 个索引,根据我们前面
-
深入解析mysql中order by与group by的顺序问题
mysql 中order by 与group by的顺序是:selectfromwheregroup byorder by注意:group by 比order by先执行,order by不会对group by 内部进行排序,如果group by后只有一条记录,那么order by 将无效.要查出group by中最大的或最小的某一字段使用 max或min函数.例:select sum(click_num) as totalnum,max(update_time) as update_time,
-
MySQL中的SQL标准语句详解
目录 前言 对数据库的操作 对表的操作 表的创建 表的插入 表的修改 表的删除 表的查询 条件查询 前言 例如MySQL中的LIMIT语句就是MySQL独有的方言,其它数据库都不支持!当然,Oracle或SQL Server都有自己的方言. 语法要求: SQL语句可以单行或多行书写,以分号结尾: 可以用空格和缩进来来增强语句的可读性: 关键字不区别大小写,建议使用大写: 对数据库的操作 #语法: CREATE DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHAR
-
图文详解Mysql中如何查看Sql语句的执行时间
目录 一.初始SQL准备 二.Mysql查看Sql语句的执行时间 三.不同查询的执行时间 总结 Mysql中如何查看Sql语句的执行时间 一.初始SQL准备 初始化表 -- 用户表 create table t_users( id int primary key auto_increment, -- 用户名 username varchar(20), -- 密码 password varchar(20), -- 真实姓名 real_name varchar(50), -- 性别 1表示男 0表示