Python中各类Excel表格批量合并问题的实现思路与案例
目录
- 基本思路:
- 遍历文件示例
- 无样式单文件合并示例
- 无样式同名多sheet表格合并
- 保留表头样式同名多sheet表格合并
- 图形化界面选择指定的目录
在日常工作中,可能会遇到各类表格合并的需求。这类需求只要搞懂核心原理都很简单,本质都是万变不离其宗,相信大部分读者都能解决大部分需求。
基本思路:
- 遍历需要被合并的文件
- 读取数据,并合并数据(使用pandas最简单便捷)
- 保存数据
对样式无要求,使用Pandas对象直接写出对样式有要求,使用openpyxl加载模板
要求样式与原始表格完全一致,使用VBA复制粘贴(本文未实现)
首先我们看下遍历文件比较简单的方法:
遍历文件示例
遍历当前目录下以xlsx为后缀的Excel,排除以~或r开头的文件:
from glob import glob
glob("[!~r]*.xlsx")
['合并结果.xlsx', '多sheet表格合并.xlsx', '带表头样式合并.xlsx']
同时还想包含xls格式的文件:
glob("[!~r]*.xls*")
['test.xls', '合并结果.xlsx', '多sheet表格合并.xlsx', '带表头样式合并.xlsx']
递归遍历当前文件夹,包含子文件夹:
glob("**/[!~r]*.xls*", recursive=True)
['test.xls', '合并结果.xlsx', '多sheet表格合并.xlsx', '带表头样式合并.xlsx', 'Excel多sheet合并\\excel3.xlsx', 'Excel多sheet合并\\excel4.xlsx', 'Excel多sheet合并\\新建文件夹\\excel3.xlsx', 'Excel多sheet合并\\新建文件夹\\excel4.xlsx', 'Excel多sheet合并\\新建文件夹\\新建文件夹\\excel3.xlsx', 'Excel多sheet合并\\新建文件夹\\新建文件夹\\excel4.xlsx', '带样式合并\\HB区.xlsx', '带样式合并\\HN区.xlsx', '带样式合并\\XN区.xlsx', '带样式合并\\汇总表.xlsx']
递归遍历指定文件夹(例如搜索本机所有登录过的微信接收到的Excel文件):
import os
path = os.path.expanduser("~/Documents/WeChat Files")
glob(f"{path}/**/[!~r]*.xls*", recursive=True)
掌握了遍历文件的基本用法,我们就可以正式开始进行文件合并了:
无样式单文件合并示例
案例1:有一堆gzip压缩的csv文件,需要合并成新的csv文件
解压后的文本格式:

合并一堆gzip压缩的csv文件最终合并成一个gzip压缩的csv文件:
from glob import glob
import pandas as pd
dfs = [pd.read_csv(file, skiprows=1, sep="|", compression="gzip")
for file in glob("gzip/*.csv.gz")]
df = pd.concat(dfs, ignore_index=True)
df.to_csv("合并后的csv压缩文件.csv.gz", index=False, compression="gzip")
最终合并结果:
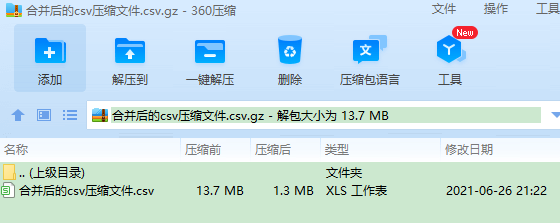
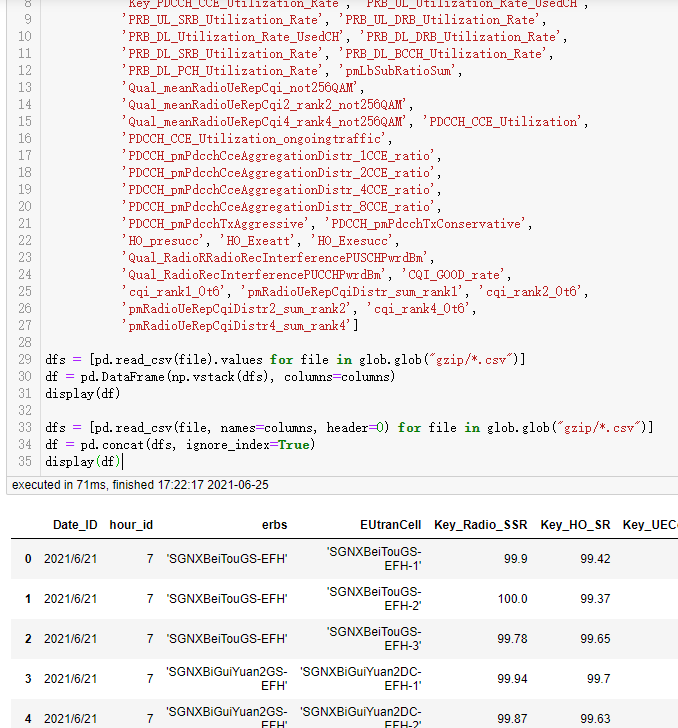
案例2:一堆csv文件,只取其中三列,表名不固定,但相对顺序一致
from glob import glob
import pandas as pd
import numpy as np
columns = ['Date_ID', 'erbs', 'EUtranCell']
dfs = [pd.read_csv(file, usecols=[0, 2, 3]).values for file in glob("csv/*.csv")]
df = pd.DataFrame(np.vstack(dfs), columns=columns)
df.to_csv("合并后的csv文件.csv", index=False)
案例3:一堆csv文件,列非常多,仅一列列名存在变动
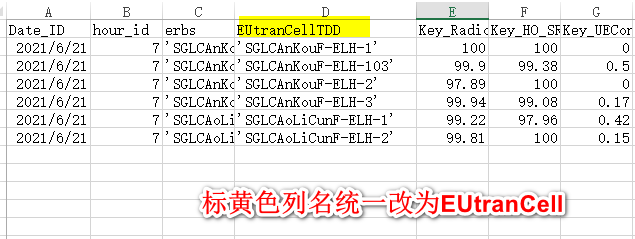
import pandas as pd
import glob
dfs = [
pd.read_csv(file).rename(
columns=lambda x:"EUtranCell" if x.startswith("EUtranCell") else x)
for file in glob.glob("csv/*.csv")
]
df = pd.concat(dfs, ignore_index=True)
df.to_csv("合并后的csv文件2.csv", index=False)
其他方法(一般不会这么写):
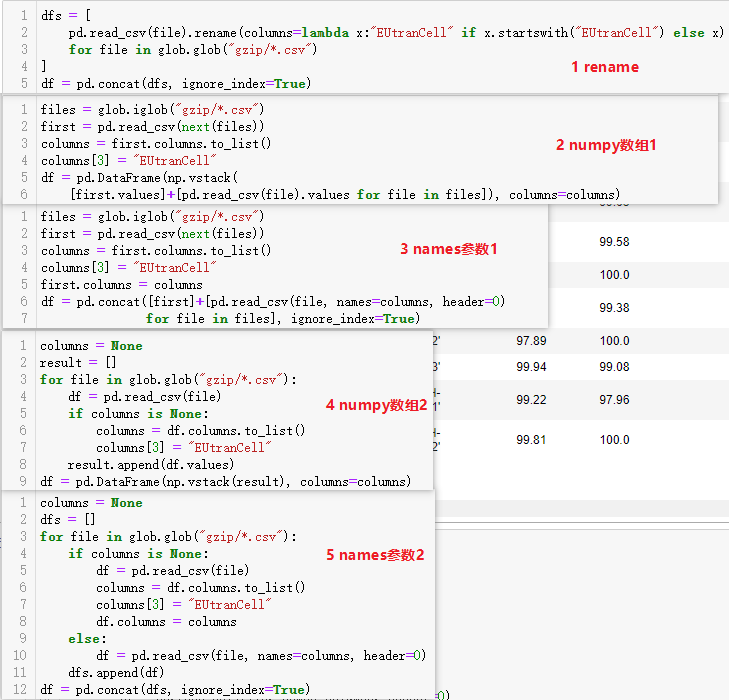
在预先能够定义好列名时,推荐以下两种写法:
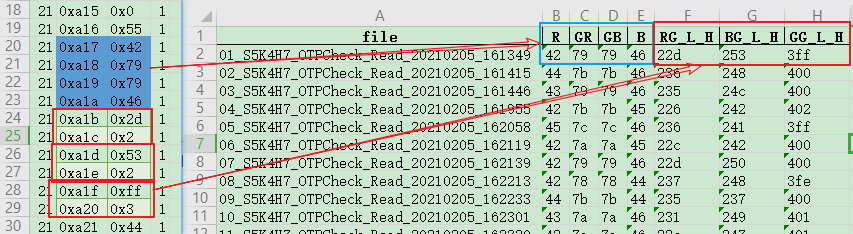
案例4:寄存器数据处理并合并
需求说明:
- 需要读取0xa17~0xa20这10个寄存器的数据,前4个寄存器数据保存到R,GR,RB,B这四列中
- 0xa1b~0xa20后6个寄存器,两两合并到RG_L_H,BG_L_H,GG_L_H这三列中
- 标识每行数据所读取的文件名
如下所示:
特殊情况:

为了方便获取文件名,我们使用pathlib来进行glob遍历:
import pandas as pd
from pathlib import Path
result = []
for file in Path("csv/PT0004B_LOG").glob("*.csv"):
df = pd.read_csv(file, header=None, usecols=[1, 2], index_col=0)
t = df[2].str[2:]
r = [str(file.name[:-4])]
r.extend(t.loc["0xa17":"0xa1a"].values)
r.extend(t.loc["0xa1c":"0xa20":2].values +
t.loc["0xa1b":"0xa20":2].str.zfill(2).values)
result.append(r)
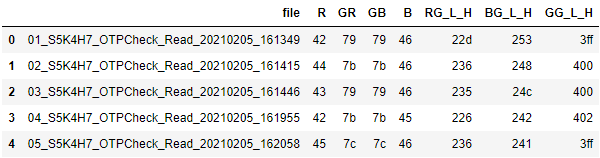
df = pd.DataFrame(
result, columns=["file", "R", "GR", "GB", "B", "RG_L_H", "BG_L_H", "GG_L_H"])
df.to_excel("combine.xlsx", index=False)
df.head()
无样式同名多sheet表格合并
如果只递归合并一个文件夹下的所有Excel的默认sheet,会非常简单,仅需4行代码搞定:
path = "Excel多sheet合并"
dfs = [pd.read_excel(file) for file in glob.glob(f"{path}/**/[!~]*.xls*", recursive=True)]
df = pd.concat(dfs, ignore_index=True)
df.to_excel("合并结果.xlsx", index=False)
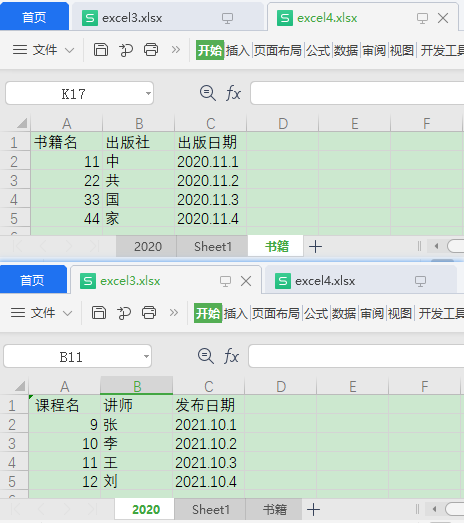
下面要求对一个文件夹下所有Excel表格,要求所有的sheet分别合并。
数据示例如下:
假设被合并的文件夹名称是Excel多sheet合并,合并代码如下:
import pandas as pd
from glob import glob
path = "Excel多sheet合并"
data = {}
for file in glob(f"{path}/**/[!~]*.xls*", recursive=True):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
with pd.ExcelWriter("多sheet表格合并.xlsx") as write:
for name, dfs in data.items():
pd.concat(dfs).to_excel(write, name, index=False)
合并结果:
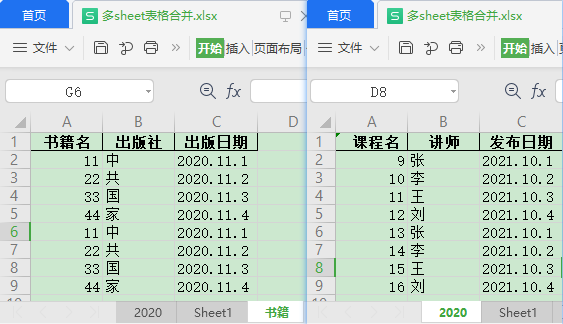
保留表头样式同名多sheet表格合并
如果要求完全带有原有样式合并会比较麻烦,本文就不作演示了,存在具体真实需求时再考虑单独开文。
需求说明:
有很多区域表:
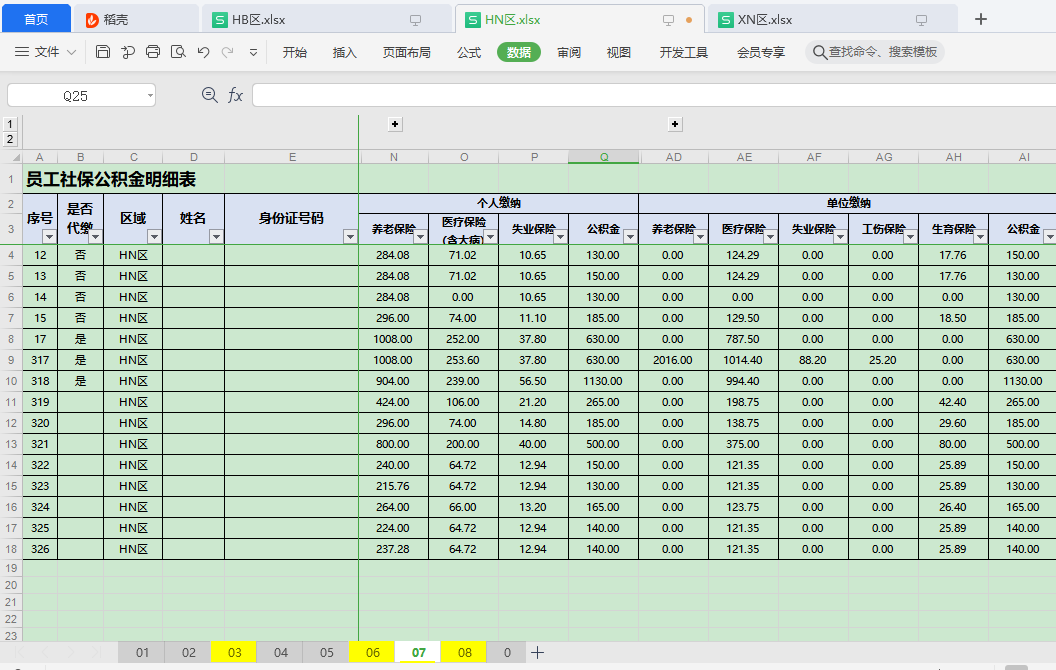
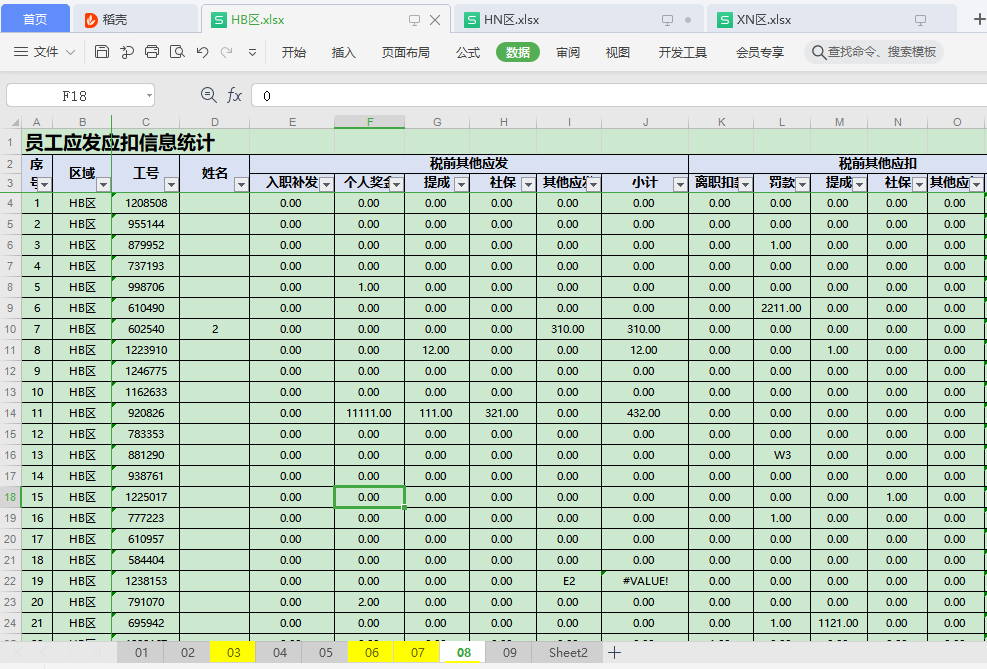
现在需要将每个区域的表格黄色的sheet合并到一张汇总表中。
为了保持表头样式的一致性,我们可以事先建立好模板,或者直接任选一个被合并的文件作为模板。
首先我们读取数据:
import pandas as pd
from glob import glob
path = "带样式合并"
# 定义被读取的sheet名和跳过的行数
sheet_start_num = {'03': 3, '06': 2, '07': 3, '08': 3}
data = {}
for file in glob(f"{path}/**/[!~r汇]*.xls*", recursive=True):
for sheet_name, skiprows in sheet_start_num.items():
excel = pd.ExcelFile(file)
df = excel.parse(sheet_name=sheet_name, skiprows=skiprows, header=None)
data.setdefault(sheet_name, []).append(df.values)
然后通过openpyxl加载模板,将数据写入各个子表中:
from openpyxl import load_workbook
workbook = load_workbook(filename="带样式合并/汇总表.xlsx")
for sheet_name, sheet_data in data.items():
sheet = workbook[sheet_name]
sheet.delete_rows(sheet_start_num[sheet_name] + 1, sheet.max_row)
for row in np.vstack(sheet_data).tolist():
sheet.append(row)
workbook.save(filename="带表头样式合并.xlsx")
最终就实现了带表头样式多sheet合并。
图形化界面选择指定的目录
如果我们希望将其做成图形化界面,可以使用tk的如下组件选择被合并的目录,或保存的位置:
from tkinter import filedialog filedialog.askdirectory(initialdir=".")
filedialog.asksaveasfilename(title="保存",
initialdir=".",
defaultextension="xlsx",
filetypes=[("Excel 工作簿", "*.xlsx"),
("Excel 97-2003 工作簿", "*.xls")])
我们以多Excel多Sheet合并为例,可以编写如下代码的py脚本:
from tkinter import filedialog
import pandas as pd
from glob import glob
path = filedialog.askdirectory(initialdir=".")
data = {}
for file in glob(f"{path}/**/[!~]*.xls*", recursive=True):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
save_name = filedialog.asksaveasfilename(title="保存",
initialdir=".",
defaultextension="xlsx",
filetypes=[("Excel 工作簿", "*.xlsx"),
("Excel 97-2003 工作簿", "*.xls")])
with pd.ExcelWriter(save_name) as write:
for name, dfs in data.items():
pd.concat(dfs).to_excel(write, name, index=False)
也可以考虑使用Gooey工具转换为图形化界面:
from glob import glob
import pandas as pd
from gooey import Gooey, GooeyParser
def combine_excel(path, save_name):
data = {}
for file in glob(f"{path}/**/[!~]*.xls*", recursive=True):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
with pd.ExcelWriter(save_name) as write:
for name, dfs in data.items():
pd.concat(dfs).to_excel(write, name, index=False)
@Gooey
def main():
parser = GooeyParser(description="多Excel多Sheet合并程序 - @小小明")
parser.add_argument('path', help="被合并的Excel文件目录", widget="DirChooser")
parser.add_argument('save_name', help="合并后保存的文件(以Excel文件形式保存)", widget="FileSaver")
args = parser.parse_args()
print("输入路径:", args.path)
print("保存位置:", args.save_name)
combine_excel(args.path, args.save_name)
print("合并完成!")
if __name__ == '__main__':
main()
还可以通过Gooey展示合并进度:
from glob import glob
import pandas as pd
from gooey import Gooey, GooeyParser
def combine_excel(path, save_name):
data = {}
files = glob(f"{path}/**/[!~]*.xls*", recursive=True)
for i, file in enumerate(files, 1):
for name, df in pd.read_excel(file, sheet_name=None).items():
data.setdefault(name, []).append(df)
yield f"合并进度:{i}/{len(files)}"
with pd.ExcelWriter(save_name) as write:
items = data.items()
for i, (name, dfs) in enumerate(items, 1):
pd.concat(dfs).to_excel(write, name, index=False)
yield f"保存进度:{i}/{len(items)}"
@Gooey(progress_regex=r"^..进度:(?P<current>\d+)/(?P<total>\d+)$",
progress_expr="current / total * 100",
timing_options={
'show_time_remaining': False,
'hide_time_remaining_on_complete': True,
})
def main():
parser = GooeyParser(description="多Excel多Sheet合并程序 - @小小明")
parser.add_argument('path', help="被合并的Excel文件目录", widget="DirChooser")
parser.add_argument('save_name', help="合并后保存的文件(以Excel文件形式保存)", widget="FileSaver")
args = parser.parse_args()
print("输入路径:", args.path)
print("保存位置:", args.save_name)
for msg in combine_excel(args.path, args.save_name):
print(msg)
print("合并完成!")
if __name__ == '__main__':
main()
到此这篇关于Python中各类Excel表格批量合并问题的实现思路与案例的文章就介绍到这了,更多相关Python Excel表格批量合并内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何使用Python对Excel表格进行拼接合并
目录 准备工作 一.横向拼接 1.1 一般拼接 1.2 指定键进行拼接,即指定某一列作为两个表的连接依据. 1.2.1 多对一 1.2.2 多对多 1.2.3 用on来指定多个连接键 1.2.4 指定左右连接键 1.2.5 索引当作连接键 1.3 连接的方式 1.3.1 内连接(inner) 1.3.2 左连接(left) 1.3.3 右连接(right) 1.3.4 外连接(outer) 二.纵向拼接 2.1 普通合并 2.2 重叠数据的合并 三.整合代码 准备工作 我准备了两个表格数据,以此
-

Python将多个excel表格合并为一个表格
生活中经常会碰到多个excel表格汇总成一个表格的情况,比如你发放了一份表格让班级所有同学填写,而你负责将大家的结果合并成一个.诸如此类的问题有很多.除了人工将所有表格的内容一个一个复制到汇总表格里,那么如何用Python自动实现这些工作呢~ 我不知道有没有其他更方便的合并方法,先用Python实现这个功能,自己用就很方便了. 比如,在文件夹下有如下7个表格(想象一下有100个或更多的表格需要合并) 作为样例,每个表格的内容均为 运行程序,将7个表格合并成了test.xls 打开test.xls
-
Python实现合并excel表格的方法分析
本文实例讲述了Python实现合并excel表格的方法.分享给大家供大家参考,具体如下: 需求 将一个文件夹中的excel表格合并成我们想要的形式,主要要pandas中的concat()函数 思路 用os库将所需要处理的表格放到同一个列表中,然后遍历列表,依次把所有文件纵向连接起来. 最开始的第一种思路是先拿一个文件出来,然后让这个文件依次去和列表中的剩余文件合并: 第二种是用文件夹中第一个文件和剩余的文件合并,使用range(1,len(file)),可以省去单独取第一个文件的步骤. 遇到的问
-
python合并同类型excel表格的方法
本文实例为大家分享了python合并同类型excel表格的具体代码,供大家参考,具体内容如下 python脚本如下,验证有效. #!/usr/bin/env python # -*- coding: UTF-8 -*- import os, csv class CSVTopoIreator: def __init__(self, filename): self.infile = open(filename, 'rb') self.reader = csv.reader(self.infile)
-
Python实现将Excel内容批量导出为PDF文件
目录 序言 实现代码 序言 上一篇咱们实现了多个表格数据合并到一个表格,本次咱们来学习如何将表格数据分开导出为PDF文件. 部分数据 然后需要安装一下这个软件 wkhtmltopdf 不知道怎么下载的可以在电脑端左侧扫一下找到我要 效果展示 数据单独导出为一个PDF 实现代码 import pdfkit import openpyxl import os target_dir = '经销商预算' if not os.path.exists(target_dir): os.mkdir(target
-
python实现读取excel表格详解方法
目录 一.python读取excel表格数据 1.读取excel表格数据常用操作 2.xlrd模块主要操作 3.读取单元格内容为日期时间的方式 4.读取合并单元格的数据 二.python写入excel表格数据 一.python读取excel表格数据 1.读取excel表格数据常用操作 import xlrd # 打开excel表格 data_excel = xlrd.open_workbook('data/dataset.xlsx') # 获取所有sheet名称 names = data_exc
-
Python中的pandas表格模块、文件模块和数据库模块
目录 一.Series数据结构 1.Series的创建 2.Series属性 2.Series缺失数据处理 二.DataFrame数据结构 1.DataFrame的创建 2.DataFrame属性 3.DataFrame取值 4.DataFrame值替换 5.处理丢失数据 6.合并数据 二.读取CSV文件 三.导入导出数据 1.读取文件导入数据 2.写入文件导出数据 3.实例 四.pandas读取json文件 五.pandas读取sql语句 pandas官方文档:https://pandas.p
-
python实现处理Excel表格超详细系列
目录 前言 xls和xlsx excel后缀.xls和.xlsx有什么区别 基本操作 1:用openpyxl模块打开Excel文档,查看所有sheet表 1.2:通过sheet名称获取表格 1.2:获取活动表 2:获取表格的尺寸 2.1:获取单元格中的数据 2.2:获取单元格的行.列.坐标 3:获取区间内的数据 操作 创建新的excel 修改单元格.excel另存为 添加数据 插入有效数据 插入空行空列 删除行.列 移动指定区间的单元格(move_range) 字母列号与数字列号之间的转换 字体
-
零基础使用Python读写处理Excel表格的方法
引 由于需要解决大批量Excel处理的事情,与其手工操作还不如写个简单的代码来处理,大致选了一下感觉还是Python最容易操作. 安装库Python环境 首先当然是配环境,不过选Python的一个重要原因就是Mac内是自带Python环境的,不需要额外的配置环境,省下了一笔工作,如果你用的是Windows系统,那就还需要配置一下Python的环境了,我Mac的Python版本是2.7. 第三方库 Python自己是不支持直接操作Excel的,但是Python强大之处就在于有大量好用的第三方库,这
-
Python脚本操作Excel实现批量替换功能
大家好,给大家分享下如何使用Python脚本操作Excel实现批量替换. 使用的工具 Openpyxl,一个处理excel的python库,处理excel,其实针对的就是WorkBook,Sheet,Cell这三个最根本的元素~ 明确需求原始excel如下 我们的目标是把下面excel工作表的sheet1表页A列的内容"替换我吧"批量替换为B列的"我用来替换的x号选手" 实现替换后的效果图,C列为B列替换A列的指定内容后的结果 实现以上功能的同时,我也实现excel
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
如何在Python中导入EXCEL数据
目录 一.前期准备 二.编写代码基本思路 三.编写代码读取数据 3.1 3.2 四.结语 一.前期准备 此篇使用两种导入excel数据的方式,形式上有差别,但两者的根本方法实际上是一样的. 首先需要安装两个模块,一个是pandas,另一个是xlrd. 在顶部菜单栏中点击文件,再点击设置,然后在设置中找到以下界面,并点击“+”号. 然后会出现以下界面,在搜索框中分别搜索以上两个模块:pandas/xlrd. 选中搜索出来的模块,并点击左下角的的安装按钮,便可将模块安装到自己电脑中. 需要注意的是,
-
Python中字典(dict)合并的四种方法总结
本文主要给大家介绍了关于Python中字典(dict)合并的四种方法,分享出来供大家参考学习,话不多说了,来一起看看详细的介绍: 字典是Python语言中唯一的映射类型. 映射类型对象里哈希值(键,key)和指向的对象(值,value)是一对多的的关系,通常被认为是可变的哈希表. 字典对象是可变的,它是一个容器类型,能存储任意个数的Python对象,其中也可包括其他容器类型. 字典类型与序列类型的区别: 1. 存取和访问数据的方式不同. 2. 序列类型只用数字类型的键(从序列的开始按数值顺序索引
-
ASP.NET中GridView 重复表格列合并的实现方法
这几天做一个项目有用到表格显示数据的地方,客户要求重复的数据列需要合并,就总结了一下GridView 和 Repeater 关于重复数据合并的方法. 效果图如下: GridView : 前台代码 : <div> <asp:GridView ID="gvIncome" runat="server" AutoGenerateColumns="False"> <Columns> <asp:TemplateFie