Python机器学习性能度量利用鸢尾花数据绘制P-R曲线
目录
- 一、性能度量
- 1.错误率与精度
- 2.查准率、查全率与F1
- 二、代码实现:
- 1.基于具体二分类问题算法实现代码:
- 2.利用鸢尾花绘制P-R曲线
- 效果:
一、性能度量
性能度量目的是对学习期的泛华能力进行评估,性能度量反映了任务需求,在对比不同算法的泛华能力时,使用不同的性能度量往往会导致不同的评判结果。常用度量有均方误差,错误率与精度,查准率与查全率等。
1.错误率与精度
这两种度量既适用于二分类任务,也适用于多分类任务。错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例。
2.查准率、查全率与F1
查准率(precision)与查全率(recall)是对于需求在信息检索、Web搜索等应用评估性能度量适应度高的检测数值。对于二分类问题,可将真实类别与算法预测类别的组合划分为真正例(ture positive)、假证例(false positive)、真反例(true negative)、假反例(false negative)四种情形。显然TP+FP+TN+FN=样例总数。分类结果为混淆矩阵:
真实情况 预测结果
正例 反例
正例 TP(真正例) FN(假反例)
反例 FP(假正例) TN(真反例)
查准率P定义为:

一般来说。查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。通常只有一些简单任务中,才可能使查全率和查准率都很高。
二、代码实现:
1.基于具体二分类问题算法实现代码:
import numpy
import matplotlib
from matplotlib import pyplot as plt
# true = [真实组1,真实组2...真实组N],predict = [预测组1,预测组2...预测组N]
def evaluation(true, predict):
num = len(true) # 确定有几组
(TP, FP, FN, TN) = ([0] * num for i in range(4)) # 赋初值
for m in range(0, len(true)):
if (len(true[m]) != len(predict[m])): # 样本数都不等,显然是有错误的
print("真实结果与预测结果样本数不一致。")
else:
for i in range(0, len(true[m])): # 对每一组数据分别计数
if (predict[m][i] == 1) and ((true[m][i] == 1)):
TP[m] += 1.0
elif (predict[m][i] == 1) and ((true[m][i] == 0)):
FP[m] += 1.0
elif (predict[m][i] == 0) and ((true[m][i] == 1)):
FN[m] += 1.0
elif (predict[m][i] == 0) and ((true[m][i] == 0)):
TN[m] += 1.0
(P, R) = ([0] * num for i in range(2))
for m in range(0, num):
if (TP[m] + FP[m] == 0):
P[m] = 0 # 预防一些分母为0的情况
else:
P[m] = TP[m] / (TP[m] + FP[m])
if (TP[m] + FN[m] == 0):
R[m] = 0 # 预防一些分母为0的情况
else:
R[m] = TP[m] / (TP[m] + FN[m])
plt.title("P-R")
plt.xlabel("P")
plt.ylabel("R")
#plt.plot(P, R)
#plt.show()
if __name__ == "__main__":
# 简单举例
myarray_ture = numpy.random.randint(0, 2, (3, 100))
myarray_predict = numpy.random.randint(0, 2, (3, 100))
evaluation(myarray_ture,myarray_predict)
下面给出利用鸢尾花数据集绘制P-R曲线的代码(主要体现其微互斥性)
2.利用鸢尾花绘制P-R曲线
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
import numpy as np
iris = datasets.load_iris()
# 鸢尾花数据导入
x = iris.data
#每一列代表了萼片或花瓣的长宽,一共4列,每一列代表某个被测量的鸢尾植物,iris.shape=(150,4)
y = iris.target
#target是一个数组,存储了data中每条记录属于哪一类鸢尾植物,所以数组的长度是150,所有不同值只有三个
random_state = np.random.RandomState(0)
#给定状态为0的随机数组
n_samples, n_features = x.shape
x = np.c_[x, random_state.randn(n_samples, 200 * n_features)]
#添加合并生成特征测试数据集
x_train, x_test, y_train, y_test = train_test_split(x[y < 2], y[y < 2],
test_size=0.25,
random_state=0)
#根据此模型训练简单数据分类器
classifier = svm.LinearSVC(random_state=0)#线性分类支持向量机
classifier.fit(x_train, y_train)
y_score = classifier.decision_function(x_test)
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
precision, recall, _ =precision_recall_curve(y_test, y_score)
plt.fill_between(recall, precision,color='b')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.0])
plt.xlim([0.0, 1.0])
plt.plot(recall, precision)
plt.title("Precision-Recall")
plt.show()
效果:

P-R图直观的显示出学习器在样本上的查全率、查准率。在进行比较时,若一个休息区的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者。为取得比较合理的判断依据,将采用“平衡点”(Break-Even Point,BEP)度量对比算法的泛华性能强弱。它是“查准率=查全率”时的取值。但BEP还是过于简化,更常用F1度量(all为样例总数):
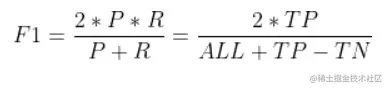
以上就是Python机器学习性能度量利用鸢尾花数据绘制P-R曲线的详细内容,更多关于Python鸢尾花数据绘制P-R曲线的资料请关注我们其它相关文章!
相关推荐
-

python机器学习pytorch 张量基础教程
目录 正文 1.初始化张量 1.1 直接从列表数据初始化 1.2 用 NumPy 数组初始化 1.3 从另一个张量初始化 1.4 使用随机值或常量值初始化 2.张量的属性 3.张量运算 3.1 标准的类似 numpy 的索引和切片: 3.2 连接张量 3.3 算术运算 3.4单元素张量 Single-element tensors 3.5 In-place 操作 4. 张量和NumPy 桥接 4.1 张量到 NumPy 数组 4.2 NumPy 数组到张量 正文 张量是一种特殊的数据结构,与数组
-
通过gradio和摄像头获取照片和视频实现过程
目录 1.环境设置 1.1gradio安装 2.ffmpeg安装 2.简单小程序 2.1 引入gradio 2.2 定义方法 2.3 定义接口 2.4 运行 3.执行情况 3.1 终端日志输出 3.2 截图 3.3 保存 1.环境设置 1.1gradio安装 需要安装 gradio,安装办法就是 pip install gradio 2.ffmpeg安装 再次需要加入到path路径. 下载地址: https://www.jb51.net/softjc/760881.html ffmpeg.exe
-
Python机器学习利用鸢尾花数据绘制ROC和AUC曲线
目录 一.ROC与AUC 1.ROC 2.AUC 二.代码实现 效果 一.ROC与AUC 很多学习器是为了测试样本产生的一个实值或概率预测,然后将这个预测值与一个分类阈值(threshold)进行比较,若大于阈值则分为正类,否则为反类.主要看需要建立的模型侧重于想用在测试数据的泛华性能的好坏.排序本身的质量好坏体系了综合考虑学习去在不同任务下的“期望泛化性能”的好坏.ROC曲线则是从这个角度出发来研究学习器泛化性能. 1.ROC ROC的全称是“受试者工作特征”曲线,与P-R曲线相似.与P-R曲
-
前端AI机器学习在浏览器中训练模型
目录 识别鸢尾花 测试集: testing.json 训练集: training.json 完整代码 index.html index.js styles.css package.json 识别鸢尾花 本文将在浏览器中定义.训练和运行模型. 为了实现这一功能,我将构建一个识别鸢尾花的案例. 接下来,我们将创建一个神经网络.同时,根据开源数据集我们将鸢尾花分为三类:Setosa.Virginica 和 Versicolor. 每个机器学习项目的核心都是数据集. 我们需要采取的第一步是将这个数据集拆
-
Gradio机器学习模型快速部署工具应用分享
目录 1.嵌入 IFrame 2.API页面 3.验证 4.直接访问网络请求 5.在另一个 FastAPI 应用程序中安装[![图片转存失败,建议将图片保存下来直接上传 6.安全和文件访问 1.嵌入 IFrame (/assets/img/anchor.svg)]()](https://gradio.app/sharing-your-app/#embedding-with-iframes) 要改为嵌入 IFrame(例如,如果您无法将 javascript 添加到您的网站),请添加此元素: <i
-
python opencv3机器学习之EM算法
目录 引言 一.opencv3.0中自带的例子 二.trainEM实现自动聚类进行图片目标检测 引言 不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmeans聚类(输入样本数据,输出样本数据的标注).实际上,高斯混和模型GMM和kmeans都是EM算法的应用. 在opencv3.0中,EM算法的函数是trainEM,函数原型为: bool train
-
python机器学习pytorch自定义数据加载器
目录 正文 1. 加载数据集 2. 迭代和可视化数据集 3.创建自定义数据集 3.1 __init__ 3.2 __len__ 3.3 __getitem__ 4. 使用 DataLoaders 为训练准备数据 5.遍历 DataLoader 正文 处理数据样本的代码可能会逐渐变得混乱且难以维护:理想情况下,我们希望我们的数据集代码与我们的模型训练代码分离,以获得更好的可读性和模块化.PyTorch 提供了两个数据原语:torch.utils.data.DataLoader和torch.util
-
Python读取excel文件中的数据,绘制折线图及散点图
目录 一.导包 二.绘制简单折线 三.pandas操作Excel的行列 四.pandas处理Excel数据成为字典 五.绘制简单折线图 六.绘制简单散点图 一.导包 import pandas as pd import matplotlib.pyplot as plt 二.绘制简单折线 数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student. Python的表单数据如下所示: student的表单数据如下所示: 1.在利用pandas模块进行
-
python多线程性能测试之快速mock数据
目录 背景 安装相关类包 快速 mock kafka 批量测试数据 appmetrics 使用方法 Meters 背景 在我们测试工作中,性能测试也是避免不了的,因此在性能测试前期准备工作中,需要 mock 足够批量的数据进行压测.那么怎么能在短时间内快速 mock 出想要的格式数据和足够量的数据进行压测?那么往下看. 安装相关类包 pip install kafka pip install appmetrics pip install faker pip install pykafka 快速
-
Python机器学习入门(二)数据理解
目录 1.数据导入 1.1使用标准Python类库导入数据 1.2使用Numpy导入数据 1.3使用Pandas导入数据 2.数据理解 2.1数据基本属性 2.1.1查看前10行数据 2.1.2查看数据维度,数据属性和类型: 2.1.3查看数据描述性统计 2.2数据相关性和分布分析 2.2.1数据相关矩阵 2.2.2数据分布分析 3.数据可视化 3.1单一图表 3.1.1直方图 3.1.2密度图 3.1.3箱线图 3.2多重图表 3.2.1相关矩阵图 3.2.2散点矩阵图 总结 统计学是什么?概
-
Python机器学习利用随机森林对特征重要性计算评估
目录 1 前言 2 随机森林(RF)简介 3 特征重要性评估 4 举个例子 5 参考文献 1 前言 随机森林是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能,因此,随机森林也被誉为"代表集成学习技术水平的方法". 2 随机森林(RF)简介 只要了解决策树的算法,那么随机森林是相当容易理解的.随机森林的算法可以用如下几个步骤概括: 1.用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个
-
利用Python多处理库处理3D数据详解
今天我们将介绍处理大量数据时非常方便的工具.我不会只告诉您可能在手册中找到的一般信息,而是分享一些我发现的小技巧,例如tqdm与 multiprocessingimap一起使用.并行处理档案.绘制和处理 3D 数据以及如何搜索如果您有点云,则用于对象网格中的类似对象. 那么我们为什么要求助于并行计算呢?如今,如果您处理任何类型的数据,您可能会面临与"大数据"相关的问题.每次我们有不适合 RAM 的数据时,我们都需要一块一块地处理它.幸运的是,现代编程语言允许我们生成在多核处理器
-
Python机器学习入门(二)之Python数据理解
目录 1.数据导入 1.1使用标准Python类库导入数据 1.2使用Numpy导入数据 1.3使用Pandas导入数据 2.数据理解 2.1数据基本属性 2.1.1查看前10行数据 2.1.2查看数据维度,数据属性和类型: 2.1.3查看数据描述性统计 2.2数据相关性和分布分析 2.2.1数据相关矩阵 2.2.2数据分布分析 3.数据可视化 3.1单一图表 3.1.1直方图 3.1.2密度图 3.1.3箱线图 3.2多重图表 3.2.1相关矩阵图 3.2.2散点矩阵图 总结 统计学是什么?概
-
Python机器学习入门(三)数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的
-
Python机器学习入门(三)之Python数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的
-
Python利用networkx画图绘制Les Misérables人物关系
目录 数据集介绍 数据处理 画图 networkx自带的数据集 完整代码 数据集介绍 <悲惨世界>中的人物关系图,图中共77个节点.254条边. 数据集截图: 打开README文件: Les Misérables network, part of the Koblenz Network Collection =========================================================================== This directory con
-
利用Python对中国500强排行榜数据进行可视化分析
目录 一.前言 二.数据采集 1.开始爬取 获取企业列表 获取企业对应url 获取每一个企业相关数据 2.保存到Excel 三.可视化分析 1.省份分布 导入相关可视化库 统计数据 地图可视化 2.营业收入年增率 3.营业收入年减率 4.利润年增率 5.利润年减率 6.排名上升最快20家企业 7.排名下降最快20家企业 8.资产区间分布 9.市值区间分布 10.营业收入区间分布 11.利润区间分布 12.中国500强企业-排名前10营业收入.利润.资产.市值.股东权益 四.总结 一.前言 今天来