java LeetCode普通字符串模拟题解示例
目录
- 题目描述
- 模拟
- 最后
题目描述
这是 LeetCode 上的 393. UTF-8 编码验证 ,难度为 中等。
Tag : 「模拟」
给定一个表示数据的整数数组 data ,返回它是否为有效的 UTF−8 编码。
UTF-8 中的一个字符可能的长度为 1 到 4 字节,遵循以下的规则:
- 对于 1字节 的字符,字节的第一位设为 0,后面 7 位为这个符号的
unicode码。 - 对于 n 字节 的字符 (n>1),第一个字节的前 n 位都设为 1,第 n+1 位设为 0 ,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的
unicode码。
这是 UTF-8 编码的工作方式:
Char. number range | UTF-8 octet sequence
(hexadecimal) | (binary)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
注意:输入是整数数组。只有每个整数的 最低 8 个有效位 用来存储数据。这意味着每个整数只表示 1 字节的数据。
示例 1:
输入:data = [197,130,1]
输出:true
解释:数据表示字节序列:11000101 10000010 00000001。
这是有效的 utf-8 编码,为一个 2 字节字符,跟着一个 1 字节字符。
示例 2:
输入:data = [235,140,4]
输出:false
解释:数据表示 8 位的序列: 11101011 10001100 00000100.
前 3 位都是 1 ,第 4 位为 0 表示它是一个 3 字节字符。
下一个字节是开头为 10 的延续字节,这是正确的。
但第二个延续字节不以 10 开头,所以是不符合规则的。
提示:
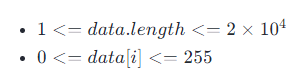
模拟
根据题意进行模拟即可。

如果上述过程满足要求,跳到下一个检查点进行检查,整个 data 都没有冲突则返回 True。
代码:
class Solution {
public boolean validUtf8(int[] data) {
int n = data.length;
for (int i = 0; i < n; ) {
int t = data[i], j = 7;
while (j >= 0 && (((t >> j) & 1) == 1)) j--;
int cnt = 7 - j;
if (cnt == 1 || cnt > 4) return false;
if (i + cnt - 1 >= n) return false;
for (int k = i + 1; k < i + cnt; k++) {
if ((((data[k] >> 7) & 1) == 1) && (((data[k] >> 6) & 1) == 0)) continue;
return false;
}
i += cnt == 0 ? 1 : cnt;
}
return true;
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
最后
这是我们「刷穿 LeetCode」系列文章的第 No.393 篇,系列开始于 2021/01/01,截止于起始日 LeetCode 上共有 1916 道题目,部分是有锁题,我们将先把所有不带锁的题目刷完。
在这个系列文章里面,除了讲解解题思路以外,还会尽可能给出最为简洁的代码。如果涉及通解还会相应的代码模板。
为了方便各位同学能够电脑上进行调试和提交代码,我建立了相关的仓库:github.com/SharingSour… 。
以上就是java LeetCode普通字符串模拟题解示例的详细内容,更多关于java LeetCode普通字符串的资料请关注我们其它相关文章!
相关推荐
-
金三银四复工高频面试题java算法LeetCode396旋转函数
目录 题目描述 前缀和 + 滑动窗口 最后 题目描述 这是 LeetCode 上的 396. 旋转函数 ,难度为 中等. Tag : 「前缀和」.「滑动窗口」 给定一个长度为 n 的整数数组 nums F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1] 返回 F(0), F(1), ..., F(n-1) 中的最大值 . 生成的测试用例让答案符合 32 位 整数. 示例 1: 输入: nums = [4,3,2,6] 输出
-
Java C++题解leetcode816模糊坐标示例
目录 题目 思路:枚举 Java C++ Rust 总结 题目 题目要求 思路:枚举 既然要输出每种可能了,那必然不能“偷懒”,就暴力枚举咯: 在每个间隔处添加逗号: 定义函数decPnt(sta, end)分别列举逗号左右两边的数能构成的可能性: 同样在每个间隔添加小数点: 注意两种不合法的结构——前导0和后缀0: 不要忘记无小数点的整数版本, 分别组合两边的不同可能性,根据要求各式加入答案. Java class Solution { String str; public List<Stri
-
Java C++题解leetcode1620网络信号最好的坐标
目录 题目 思路:暴力模拟 Java C++ Rust 题目 题目要求 思路:暴力模拟 因为数据范围小,所以是万万没想到的逐个遍历…… 遍历每个塔,然后找每个塔辐射的范围,用一个大矩阵记录每个点对应的信号大小,同时维护当前最大的信号及其对应坐标. Java class Solution { public int[] bestCoordinate(int[][] towers, int radius) { int[][] grid = new int[110][110]; int cx = 0,
-
Java C++刷题leetcode1106解析布尔表达式
目录 题目 思路:栈[计算器] Java C++ Rust 总结 题目 题目要求 思路:栈[计算器] 和计算器原理类似,分别用两个栈存操作数和操作符,然后到)就开始运算前面的内容,括号里运算都相同所以还是比较简单的. 要注意字母t.f和布尔值true.false的转换. Java class Solution { public boolean parseBoolExpr(String expression) { Deque<Character> tfs = new ArrayDeque<
-

Java编程实现的模拟行星运动示例
本文实例讲述了Java编程实现的模拟行星运动.分享给大家供大家参考,具体如下: 期待了很久的Java语言程序设计也拉下了帷幕,在几个月的时间里基本掌握了java的简单用法,学习了java的主要基础知识,面向对象思想,多线程并发控制,swing界面设计,动画制作等,最后结课了也打算制作一个课程设计能够尽可能多的涵盖所学知识,将其进行串联,因此考虑实现了一个简单的模拟行星运动的小软件,主要思路如下: 利用动画实现行星运动的模拟,主面板里有一个中心行星,同时绘制了椭圆轨道,有一颗运动的行星围绕着中心行
-
Java C++题解leetcode 1684统计一致字符串的数目示例
目录 题目 思路:模拟 Java C++ Rust 题目 题目要求 思路:模拟 用一个哈希表记录可出现的字母,然后逐一遍历每个单词每个字母,符合条件则结果加一. Java class Solution { public int countConsistentStrings(String allowed, String[] words) { boolean[] hash = new boolean[26]; for (var a : allowed.toCharArray()) hash[a -
-
Java调用JavaScript实现字符串计算器代码示例
如果表达式是字符串的形式,那么一般我们求值都会遇到很大的问题. 这里有一种直接调用JavaScript的方法来返回数值,无疑神器. 代码如下: package scc; import javax.script.ScriptEngine; import javax.script.ScriptEngineManager; import javax.script.ScriptException; public class Counter { public static void main(String
-
Java实现去掉字符串重复字母的方法示例
本文实例讲述了Java实现去掉字符串重复字母的方法.分享给大家供大家参考,具体如下: package demo; public class Ctrl { public static void main(String[] args){ String s = "akkbcccrsa"; System.out.println("我们测试结果:"); System.out.print("原字符串:"); System.out.println(s); Ct
-
java数据结构与算法数组模拟队列示例详解
目录 一.什么是队列 二.用数组来模拟队列 一.什么是队列 队列是一个有序列表,可以用数组或者链表来实现. 遵循先入先出的原则,即:先存入队列的数据,要先取出.后存入的的数据,后取出. 看一张队列的模拟图,1,2,3表示同一个队列Queue.在队列中有2个指针,front表示队首,rear表示队尾. 图1中表示队列里还没有数据,所以front跟rear初始化都是-1. 当图2中有数据进行存入的时候,front没变,而rear则随着数据的增多而改变.存入了4个数据,于是rear=3. 再看图3,f
-
Go Java 算法之字符串解码示例详解
目录 字符串解码 方法一:栈(Java) 方法二:递归(Go) 字符串解码 给定一个经过编码的字符串,返回它解码后的字符串. 编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正重复 k 次.注意 k 保证为正整数. 你可以认为输入字符串总是有效的:输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的. 此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入. 示例 1: 输入:
-
java实现统计字符串中字符及子字符串个数的方法示例
本文实例讲述了java实现统计字符串中字符及子字符串个数的方法.分享给大家供大家参考,具体如下: 这里用java实现统计字符串中的字符(包括数字.大写字母.小写字母以及其他字符)个数,以及字符串的子字符串的个数. 运行效果图如下: 具体代码如下: import java.util.Scanner; public class Counter { static Scanner scanner = new Scanner(System.in); public static void count(Str
-
Java实现对字符串中的数值进行排序操作示例
本文实例讲述了Java实现对字符串中的数值进行排序操作.分享给大家供大家参考,具体如下: 问题: 对"34 9 -7 12 67 25"这个字符串中的数值从小到大排序! 解决方法: 先介绍几个eclipse快捷键:输入for再按下"alt+/"可快速写一个for循环 选中某一个小写单词 Ctrl+Shift+x 可变大写,选中某一个大写单词 Ctrl+Shift+y 可变小写 下面请看具体实现代码: import java.util.Arrays; public
-
java实现将字符串中首字母转换成大写,其它全部转换成小写的方法示例
本文实例讲述了java实现将字符串中首字母转换成大写,其它全部转换成小写的方法.分享给大家供大家参考,具体如下: public class TestSubstring { public static void main(String[] args) { String s = getConvert("adsJKJ3K21AfaAD134F13241d134134s141faAAFDF"); System.out.println(s); } //将一个字符串中的首字母转换成大写,其它的全部
-
java实现统计字符串中大写字母,小写字母及数字出现次数的方法示例
本文实例讲述了java实现统计字符串中大写字母,小写字母及数字出现次数的方法.分享给大家供大家参考,具体如下: public class TestSubstring { public static void main(String[] args) { getCount("adsJKJ3K21AfaAD134F13241d134134s141faAAFDF"); } //统计字符串中,大写字母,小写字母,数字出现的次数 public static void getCount(String