浅谈MySQL为什么会选错索引
目录
- 1.引例
- 2.优化器的逻辑
- 3.解决办法
1.引例
首先创建一张表,并对字段a,b分别建立索引:
create table t (
id int(11) not null,
a int(11) default null,
b int(11) default null,
primary key (id),
key a(a),
key b(b)
)engine=InnoDB;
然后往表中,插入十万行数据,值按整数递增:(1,1,1)、(2,2,2)、(3,3,3)…
delimiter ;; create PROCEDURE insertdata() begin declare i int; set i=1; while(i<=100000) DO insert into t values(i,i,i); set i = i+1; end while; end;; delimiter ; call insertdata();
接下来,我们执行一条sql:
mysql >explain select * from t where a between 10000 and 20000;
执行结果:

结果中的“key”字段就代表了查询中使用的索引。所以这条语句走了索引a,没什么问题。
我们再来执行如下操作:

但是这个时候session B的查询语句select * from t where a between 10000 and 20000就不会再选择索引a。
为了比较使用索引和不使用的查询性能对比,执行下面的语句:
set long_query_time=0; select * from t where a between 10000 and 20000; select * from t force(a) where a between 10000 and 20000;
下面是两种慢查询日志中的结果对比:
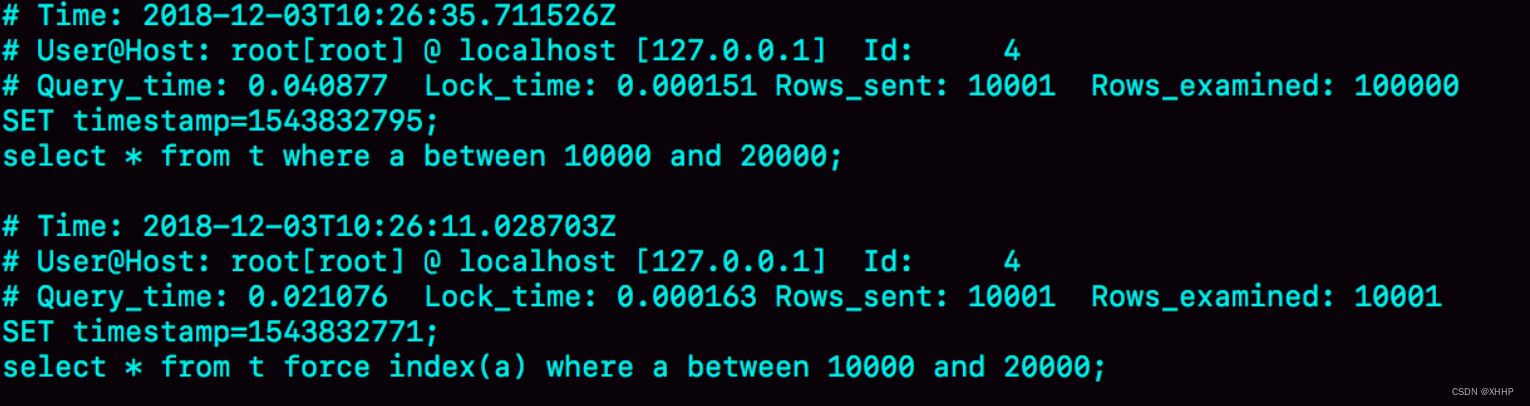
第一个查询查找了十万行,第二个查询走了索引,查找了一万行,速度明显比较快。
那为什么会选错索引呢?
2.优化器的逻辑
选择索引是优化器的工作,优化器选择索引的目的,就是想要找到一个最优的执行方案,并用最小的代价去执行。
在数据库里面,扫描行数是影响执行代价的因素之一。扫描行数越少,意味着访问磁盘次数越少。但是扫描行数并不是唯一的评价标准,还会考虑临时表,是否排序等因素。
那扫描行数是如何判断的?
MySQL在真正执行之前,只能根据统计信息来估算记录数。这个统计信息就是索引的“区分度”。 一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。
我们可以用show index的方法看到不同索引的基数值,但是可以看到统计信息并不是太准确。 可以使用analyze table t来重新统计,但是也不一定准确。

那MySQL是如何得到索引的基数呢?
答案是MySQL会采取采样统计的方法,默认会选择N个数据页,统计这些页面上的不同值,得到平均值,再乘以总的页面数。
在MySQL中,有两种存储索引统计的方式,可以通过设置innodb_stats_persisten来设置:
- 设置为on的时候,表示统计信息会持久化存储。这时,默认的N是20,M是10
- 设置为off的时候,表示统计信息只存储在内存中。这时,默认的N是8,M是16
我们再来比较两个语句预估的查询行数,如下图:

图中的row字段就代表预估的查询行数。对于第一条语句,预估的查询行数是104620.第二条语句,预估的查询行数是37116。明显第二条语句的查询行数少,那为什么没有选择索引a呢?
这是因为,如果使用索引a,每次从索引a上拿到一个值,都要回表查询。而如果选择扫描十万行的语句,则不需要回表。因此优化器评估这两条语句时,觉得回表查询更耗费时间,所以没有使用索引。但是实际中,这种方式并不是最优的。
3.解决办法
第一种解决办法是和第二条语句一样,采用force index强行选择一个索引。如果force index指定的索引在候选索引列表中,就直接选择这个索引,而不再去评估执行代价。但是这种方式不太优雅,而且改了索引名,语句也要改
第二种解决办法是考虑修改sql语句,引导MySQL使用我们期望的索引。
第三种解决办法是新建一个更合适的索引,删除掉误用的索引。
到此这篇关于浅谈MySQL为什么会选错索引的文章就介绍到这了,更多相关MySQL 选错索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL选错索引的原因以及解决方案
MySQL 中,可以为某张表指定多个索引,但在语句具体执行时,选用哪个索引是由 MySQL 中执行器确定的.那么执行器选择索引的原则是什么,以及会不会出现选错索引的情况呢? 先看这样一个例子: 创建表 Y,设置两个普通索引, 创建一个存储过程用于插入数据. MySQL: 5.7.27, 隔离级别: RR CREATE TABLE `Y` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DE
-
浅谈MySQL为什么会选错索引
目录 1.引例 2.优化器的逻辑 3.解决办法 1.引例 首先创建一张表,并对字段a,b分别建立索引: create table t ( id int(11) not null, a int(11) default null, b int(11) default null, primary key (id), key a(a), key b(b) )engine=InnoDB; 然后往表中,插入十万行数据,值按整数递增:(1,1,1).(2,2,2).(3,3,3)… delimiter ;;
-
浅谈Mysql哪些字段适合建立索引
1 数据库建立索引常用的规则如下: 1.表的主键.外键必须有索引: 2.数据量超过300的表应该有索引: 3.经常与其他表进行连接的表,在连接字段上应该建立索引: 4.经常出现在Where子句中的字段,特别是大表的字段,应该建立索引: 5.索引应该建在选择性高的字段上: 6.索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引: 7.复合索引的建立需要进行仔细分析:尽量考虑用单字段索引代替: A.正确选择复合索引中的主列字段,一般是选择性较好的字段: B .复合索引的几个字段是否经常同
-

浅谈mysql哪些情况会导致索引失效
下面有一些培训教学机构的口诀和我个人的一些总结: 为了讲解以下索引内容,我们先建立一个临时的表 test02 CREATE TABLE `sys_user` ( `id` varchar(64) NOT NULL COMMENT '主键', `name` varchar(64) DEFAULT NULL COMMENT '名字', `age` int(64) DEFAULT NULL COMMENT '年龄', `pos` varchar(64) DEFAULT NULL COMMENT '职位
-
浅谈MySQL和Lucene索引的对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过一篇<Solr与MySQL查询性能对比>,只是简单的对比了下查询性能,对于内部原理却没有解释,本文简单分析下两者的索引区别. MySQL索引实现 在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式. M
-
浅谈mysql密码遗忘和登陆报错的问题
mysql登录密码忘记,其实解决办法很简单,只需要在mysql的主配置文件my.cnf里添加一行"跳过授权表"的参数选择即可! 在my.cnf中添加下面一行: [root@test-huanqiu ~]# vim /etc/my.cnf //在[mysqld]区域里添加 ........ skip-grant-tables //跳过授权表 然后重启mysql服务,即可无密码登录 [root@test-huanqiu
-
浅谈mysql的索引设计原则以及常见索引的区别
索引定义:是一个单独的,存储在磁盘上的数据库结构,其包含着对数据表里所有记录的引用指针. 数据库索引的设计原则: 为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引. 那么索引设计原则又是怎样的? 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录. 例如,学生表中学号是具有唯一性的字段.为该字段建立唯一性索引可以很快的确定某个学生的信息. 如果使用姓名的话,可能存在同名现象,从而降低查询速度. 2.为经常需要排序.分组和联合操
-
浅谈mysql增加索引不生效的几种情况
增加索引可以提高查询效率. 增加索引就是增加一个索引文件,存放的是数据的地址,类似与我们文档的目录,在查找过程中可以不用从书的内容查找,直接根据目录对应的页码查找.索引是根据地址查找. 创建索引,索引使用的数据结构也有很多种.常见的是B-tree,哈希等.mysql默认使用的数据库索引是innerDB,innerDB的索引结构是B-tree. 但是在使用过程中哪些情况增加索引无法达到预期的效果呢?下面列举几种常见情况: 假设name age address 都已经加了索引.索引名字分别为 ind
-
浅谈Mysql主键索引与非主键索引区别
目录 什么是索引 主键索引和普通索引的区别 索引具体采用的哪种数据结构 InnoDB使用的B+ Tree的索引模型,那么为什么采用B+ 树?这和Hash索引比较起来有什么优缺点? B+ Tree的叶子节点都可以存哪些东西? 聚簇索引和非聚簇索引,在查询数据的时候有区别? Index Condition Pushdown(索引下推) 查询优化器 关于索引的题 什么是索引 MySql官方索引的定义:索引(Index)是帮助MySql高效获取数据的数据结构,索引的目的在于提高查询效率,类比字典:实际上
-
浅谈MySql整型索引和字符串索引失效或隐式转换问题
目录 问题概述 问题重现 问题引申 结论 问题概述 今天在上班时,DBA突然找出来一段sql,表示该sql存在隐式转换,不走索引.经过我们的查看后,发现是类型varchar的字段, 我们使用条件传入了数值型的值,由于担心违反保密协议,在此就不贴图了,由我重现一下类似情况给大家看一下. 问题重现 首先我们先创建一张用户表test_user,其中USER_ID为了效果我们设置为varchar类型且加上唯一索引. CREATE TABLE test_user ( ID int(11) NOT NULL