python使用xlsx和pandas处理Excel表格的操作步骤
目录
- 一、使用xls和xlsx处理Excel表格
- 1.1 用openpyxl模块打开Excel文档,查看所有sheet表
- 1.2 通过sheet名称获取表格
- 1.3 获取活动表的获取行数和列数
- 读取xlsx文件错误:xlrd.biffh.XLRDError: Excel xlsx file; not supported
- 二、使用pandas读取xlsx
- 2.1 读取数据
- 2.2 使用pandas查找两个列表中相同的元素
- 解决ValueError: Excel file format cannot be determined, you must specify an engine manually.
- 解决but no encoding declared; see https://python.org/dev/peps/pep-0263/ for details
- 解决MatplotlibDeprecationWarning: Support for FigureCanvases without a required_interactive_framework attribute was deprecated in Matplotlib 3.6 and will be removed two minor releases later.
- 总结
一、使用xls和xlsx处理Excel表格
xls是excel2003及以前版本所生成的文件格式;
xlsx是excel2007及以后版本所生成的文件格式;
(excel 2007之后版本可以打开上述两种格式,但是excel2013只能打开xls格式);
1.1 用openpyxl模块打开Excel文档,查看所有sheet表
openpyxl.load_workbook()函数接受文件名,返回一个workbook数据类型的值。这个workbook对象代表这个Excel文件,这个有点类似File对象代表一个打开的文本文件。
workbook = xlrd2.open_workbook("1.xlsx") # 返回一个workbook数据类型的值
sheets = workbook.sheet_names()
print(sheets)
# 结果:
# ['Sheet1', 'Sheet2']
或者
workbook = openpyxl.load_workbook("1.xlsx") # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
# 结果:
# ['Sheet1', 'Sheet2']
1.2 通过sheet名称获取表格
workbook = openpyxl.load_workbook("数据源总表(1).xlsx") # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
sheet = workbook['Sheet1'] # 获取指定sheet表
print(sheet)
# 结果:
# ['Sheet1', 'Sheet2']
# <Worksheet "Sheet1">

1.3 获取活动表的获取行数和列数
方法1:自己写一个for循环
方法2:使用
- sheet.max_row 获取行数
- sheet.max_column 获取列数
workbook = openpyxl.load_workbook("数据源总表(1).xlsx") # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
sheet = workbook['1、基本情况'] # 获取指定sheet表
print(sheet)
print('rows', sheet.max_row, 'column', sheet.max_column) # 获取行数和列数

读取xlsx文件错误:xlrd.biffh.XLRDError: Excel xlsx file; not supported
运行代码时,会出现以下报错。
xlrd.biffh.XLRDError: Excel xlsx file; not supported
(1)检查第三方库xlrd的版本:
我这里的版本为xlrd2.0.1最新版本,问题就出在这里,我们需要卸载最新版本,安装旧版本,卸载安装过程如下。
(2)在File-Settings下的Project-Python Interpreter中重新按照旧版本xlrd2,

按照上述步骤卸载xlrd后再安装xlrd2后,

可以看到错误解决了。
二、使用pandas读取xlsx
pyCharm pip安装pandas库,请移步到python之 pyCharm pip安装pandas库失败_水w的博客-CSDN博客_pandas安装失败
2.1 读取数据
import pandas as pd
#1.读取前n行所有数据
df1=pd.read_excel('d1.xlsx')#读取xlsx中的第一个sheet
data1=df1.head(10) #读取前10行所有数据
data2=df1.values #list【】 相当于一个矩阵,以行为单位
#data2=df.values() 报错:TypeError: 'numpy.ndarray' object is not callable
print("获取到所有的值:\n{0}".format(data1))#格式化输出
print("获取到所有的值:\n{0}".format(data2))
#2.读取特定行特定列
data3=df1.iloc[0].values #读取第一行所有数据
data4=df1.iloc[1,1] #读取指定行列位置数据:读取(1,1)位置的数据
data5=df1.iloc[[1,2]].values #读取指定多行:读取第一行和第二行所有数据
data6=df1.iloc[:,[0]].values #读取指定列的所有行数据:读取第一列所有数据
print("数据:\n{0}".format(data3))
print("数据:\n{0}".format(data4))
print("数据:\n{0}".format(data5))
print("数据:\n{0}".format(data6))
#3.获取xlsx文件行号、列号
print("输出行号列表{}".format(df1.index.values)) #获取所有行的编号:0、1、2、3、4
print("输出列标题{}".format(df1.columns.values)) #也就是每列的第一个元素
#4.将xlsx数据转换为字典
data=[]
for i in df1.index.values: #获取行号的索引,并对其遍历
#根据i来获取每一行指定的数据,并用to_dict转成字典
row_data=df1.loc[i,['id','name','class','data','score',]].to_dict()
data.append(row_data)
print("最终获取到的数据是:{0}".format(data))
#iloc和loc的区别:iloc根据行号来索引,loc根据index来索引。
#所以1,2,3应该用iloc,4应该有loc
读取特定的某几列的数据:
import pandas as pd file_path = r'int.xlsx' # r对路径进行转义,windows需要 df = pd.read_excel(file_path, header=0, usecols=[3, 4]) # header=0表示第一行是表头,就自动去除了, 指定读取第3和4列
2.2 使用pandas查找两个列表中相同的元素
解决:查找两个列表中相同的元素,可以把列表转为元祖/集合,进行交运算。
import pandas as pd
file_path = r'int.xlsx' # r对路径进行转义,windows需要
df = pd.read_excel(file_path, header=0, usecols=[3, 4]) # header=0表示第一行是表头,就自动去除了, 指定读取第3和4列
i, o = list(df['i']), list(df['o'])
in_links, out_links = [], []
a = set(in_links) # 转成元祖
b = set(out_links)
c = (a & b) # 集合c和b中都包含了的元素
print(a, '\n', b)
print('两个列表中相同的元素是:', list(c))

解决ValueError: Excel file format cannot be determined, you must specify an engine manually.
报错:我在使用python的pandas读取表格的数据,但是报错了,
import pandas as pd file_path = 'intersection.xlsx' # r对路径进行转义,windows需要 df = pd.read_excel(file_path, header=0, usecols=[0]) # header=0表示第一行是表头,就自动去除了, 指定读取第1列 print(df)
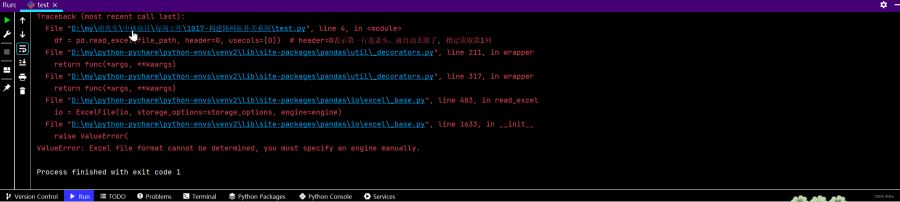
问题:问题在于原表格格式可能有些问题。
解决:最直接的办法就是把表格的内容复制到一个自己新建的表格中,然后改成之前表格的路径,
然后再安装这个openpyxl第三方库。
pip install openpyxl

重新运行代码,

ok,问题解决。
解决but no encoding declared; see https://python.org/dev/peps/pep-0263/ for details
报错:
but no encoding declared; see https://python.org/dev/peps/pep-0263/ for details
问题:xxx文件里有中文字符。
解决:在py文件的代码第一行 加上,
# -*-coding:utf8 -*-

解决MatplotlibDeprecationWarning: Support for FigureCanvases without a required_interactive_framework attribute was deprecated in Matplotlib 3.6 and will be removed two minor releases later.
报错:在使用pandas读取文件时,显示错误。
MatplotlibDeprecationWarning: Support for FigureCanvases without a required_interactive_framework attribute was deprecated in Matplotlib 3.6 and will be removed two minor releases later.
问题:matplotlib3.2以后就把mpl-data分离出去了 。
解决:卸载原来的版本,安装3.1版本。
pip uninstall matplotlib # 卸载原来的版本 pip install matplotlib==3.1.1 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com # 安装3.1版本
总结
到此这篇关于python使用xlsx和pandas处理Excel表格的文章就介绍到这了,更多相关python xlsx和pandas处理Excel表格内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
利用Python读取Excel表内容的详细过程
目录 用python读取excel表中的数据 这里再多说一下,np.hstack()函数和 np.vstack()函数: 总结 用python读取excel表中的数据 假如说有如下一张存储了数据的excel表,其中x1-x6是特征,y_label是特征对应的类别标签.我们想要使用python对以下数据进行数据分析,那么第一步就要先把excel表中的数据读取出来才行.这里我们主要使用到了python中的pandas库. 首先确定excel表存放的路径所在,比如我的路径是 ‘E:\relate_co
-
如何利用Python让Excel快速按条件筛选数据
本文即使用python实现excel快速筛选数据 有一张 12 个月份的产品销售情况表. 安装所需的 Python 第三方库 xlwings 的特色: xlwings 能够非常方便地读写 Excel 文件中的数据,并且能够进行单元格格式的修改 可以和 Matplotlib 以及 Pandas 无缝连接 可以调用 Excel 文件中 VBA 写好的程序,也可以让 VBA 调用用 Python 写的程序 开源免费,一直在更新 导入 xlwings: import xlwings as xw 通过 P
-
详解Python如何实现对比两个Excel数据差异
目录 1.引言 2.代码实战 3.总结 1.引言 小丝:鱼哥,还记得上次写的把数据库的查询结果写入到excel这个脚本不. 小鱼:嗯… 可以说不记得吗 小丝:我猜你就记得. 小鱼:你…说…啥?? 小丝:我说,你记得这个脚本. 小鱼:啊? 你说去洗澡? 小丝:鱼哥,别闹,正儿八经的. 小鱼:啊… 你说还要做SPA . 小丝:鱼哥,你这… 小鱼:啊… 你问我什么时间方便? 小丝:鱼哥!!!!!!!!!!!! 小鱼:昂,咋了. 小丝:你要是再帮我写个脚本,咱就去洗澡. 小鱼:哦,洗完澡还要吃烧烤??
-
python使用xlsx和pandas处理Excel表格的操作步骤
目录 一.使用xls和xlsx处理Excel表格 1.1 用openpyxl模块打开Excel文档,查看所有sheet表 1.2 通过sheet名称获取表格 1.3 获取活动表的获取行数和列数 读取xlsx文件错误:xlrd.biffh.XLRDError: Excel xlsx file: not supported 二.使用pandas读取xlsx 2.1 读取数据 2.2 使用pandas查找两个列表中相同的元素 解决ValueError: Excel file format cannot
-

python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
利用python将 Matplotlib 可视化插入到 Excel表格中
目录 数据可视化 图表插入Excel 前言: 在生活中工作中,我们经常使用Excel用于储存数据,Tableau等BI程序处理数据并进行可视化.我们也经常使用R.Python编程进行高质量的数据可视化,生成制作了不少精美优雅的图表. 但是如何将这些“优雅”延续要Excel中呢?Python绘图库有很多,我们就还是拿最基本的Matplotlib为例. 今天就为大家演示一下,如何将Matplotlib绘制的可视化图片,插入到Excel中. 其他可视化库生成的图片,也同样适用 数据可视化 目前Pyth
-
Python处理EXCEL表格导入操作分步讲解
目录 一.前期准备 二.编写代码基本思路 三.编写代码读取数据 四.结语 一.前期准备 此篇使用两种导入excel数据的方式,形式上有差别,但两者的根本方法实际上是一样的. 首先需要安装两个模块,一个是pandas,另一个是xlrd. 在顶部菜单栏中点击文件,再点击设置,然后在设置中找到以下界面,并点击“+”号. 然后会出现以下界面,在搜索框中分别搜索以上两个模块:pandas/xlrd. 选中搜索出来的模块,并点击左下角的的安装按钮,便可将模块安装到自己电脑中. 需要注意的是,xlrd的新版本
-
PHP5.6读写excel表格文件操作示例
本文实例讲述了PHP5.6读写excel表格文件操作.分享给大家供大家参考,具体如下: 测试环境:php5.6.24.这块没啥兼容问题. 需要更多栗子,请看PHPExcel的examples.还是蛮强大的. 读取excel文件: 第一步.下载开源的PHPExcel的类库文件,官方网站是http://www.codeplex.com/PHPExcel.里面也有很多示例包. 或者从本站下载:https://www.jb51.net/codes/194070.html 第二步.读取的基本代码示例: <
-
python 三种方法实现对Excel表格的读写
1.使用xlrd模块读取数据 # 将excel表格内容导入到tables列表中 def import_excel(tab): # 创建一个空列表,存储Excel的数据 tables = [] for rown in range(1, tab.nrows): array = {'设备名称': '', '框': '', '槽': '', '端口': '', 'onuid': '', '认证密码': '', 'load': '', 'checkcode': ''} array['设备名称'] = ta
-
Python入门之使用pandas分析excel数据
1.问题 在python中,读写excel数据方法很多,比如xlrd.xlwt和openpyxl,实际上限制比较多,不是很方便.比如openpyxl也不支持csv格式.有没有更好的方法? 2.方案 更好的方法可以使用pandas,虽然pandas不是专门处理excel数据,但处理excel数据确实很方便. 本文使用excel的数据来自网络,数据内容如下: 2.1.安装 使用pip进行安装. pip3 install pandas 导入pandas: import pandas as pd 下文使
-
基于python实现把json数据转换成Excel表格
json数据: [{"authenticate":-99,"last_ip":"156.2.98.429","last_time":"2020/05/23 01:41:36","member_id":5067002,"mg_id":1,"name":"yuanfang","status":0,"us
-
pandas 读取excel文件的操作代码
目录 一 read_excel() 的基本用法 二 read_excel() 的常用的参数: 三 示例 1. IO:路径 2. sheet_name:指定工作表名 3. header :指定标题行 4. names: 指定列名 5. index_col: 指定列索引 6. skiprows:跳过指定行数的数据 7. skipfooter:省略从尾部的行数据 8.dtype 指定某些列的数据类型 一 read_excel() 的基本用法 import pandas as pd file_name
-
Python办公自动化之教你用Python批量识别发票并录入到Excel表格中
一.场景描述 这里有以四张发票为例(辰哥网上搜的),将发票图片放到pic文件夹下. 随便打开一张发票 提取目标:金额.名称.纳税人识别号.开票人. 最后将每一张发票的这四个内容保存到excel中: 二.准备环境 需要用到的库如下: from PIL import Image as PI import pyocr import pyocr.builders from cnocr import CnOcr 安装的命令如下: pip install pyocr pip install cnocr 发票