解析PHP对现有搜索引擎的调用
<?php
$key = $_GET['key']; //获得关键字
$select = $_GET['select']; //获得搜索引擎的选择
switch($select) //根据搜索引擎的不同跳转到不同的页面
{
case "google": //GOOGLE
$url = "http://www.google.com/search?q=".$key;
header("Location: $url");
break;
case "yahoo": //YAHOO
$url = "http://search.yahoo.com/search?p=".$key;
header("Location: $url");
break;
case "baidu": //百度
$url = "http://www.baidu.com/s?wd=".$key;
header("Location: $url");
break;
default: //如果搜索引擎不存在,结束程序
break;
}
?>
运行结果如图36-4所示。
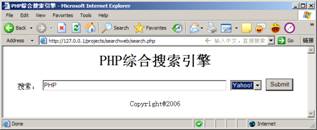
图36-4 PHP综合搜索引擎
单击【Submit】按钮后,可以看到Yahoo网站被打开了,并搜索到了相关的搜索结果,如图36-5所示。

图36-5 Yahoo的搜索结果
相关推荐
-
PHP记录搜索引擎蜘蛛访问网站足迹的方法
本文实例讲述了PHP记录搜索引擎蜘蛛访问网站足迹的方法.分享给大家供大家参考.具体分析如下: 搜索引擎的蜘蛛访问网站是通过远程抓取页面来进行的,我们不能使用JS代码来取得蜘蛛的Agent信息,但是我们可以通过image标签,这样我们就可以得到蜘蛛的agent资料了,通过对agent资料的分析,就可以确定蜘蛛的种类.性别等因素,我们在通过数据库或者文本来记录就可以进行统计了. 数据库结构: 以下为引用的内容: # # 表的结构 `naps_stats_bot` # CREATE TABLE `na
-
php获取从百度、谷歌等搜索引擎进入网站关键词的方法
本文实例讲述了php获取从百度.谷歌等搜索引擎进入网站关键词的方法.分享给大家供大家参考.具体实现方法如下: <?php function search_word_from() { $referer = isset($_SERVER['HTTP_REFERER'])?$_SERVER['HTTP_REFERER']:''; if(strstr( $referer, 'baidu.com')){ //百度 preg_match( "|baidu.+wo?r?d=([^\\&]*)|i
-
PHP统计nginx访问日志中的搜索引擎抓取404链接页面路径
我在服务器上有每天切割nginx日志的习惯,所以针对每天各大搜索引擎来访,总能记录一些404页面信息,传统上我只是偶尔分析下日志,但是对于很多日志信息的朋友,人工来筛选可能不是一件容易的事情,这不我个人自己慢慢研究了一点点,针对谷歌.百度.搜搜.360搜索.宜搜.搜狗.必应等搜索引擎的404访问生成为一个txt文本文件,直接上代码test.php. 复制代码 代码如下: <?php //访问test.php?s=google $domain='http://www.jb51.net'; $spi
-
php 判断访客是否为搜索引擎蜘蛛的函数代码
复制代码 代码如下: /** * 判断是否为搜索引擎蜘蛛 * * @author Eddy * @return bool */ function isCrawler() { $agent= strtolower($_SERVER['HTTP_USER_AGENT']); if (!empty($agent)) { $spiderSite= array( "TencentTraveler", "Baiduspider+", "BaiduGame",
-
php实现判断访问来路是否为搜索引擎机器人的方法
本文实例讲述了php实现判断访问来路是否为搜索引擎机器人的方法.分享给大家供大家参考.具体分析如下: 很多时候我们需要对网站访客来路进行识别,针对真实用户与搜索引擎作不同动作实现,那么首先就需要判断是否为搜索引擎. php判断方法非常简单,通过过滤$_SERVER['HTTP_USER_AGENT'] 参数即可进行识别,以下是摘录某开源程序的相关源码: private function getRobot() { if (empty($_SERVER['HTTP_USER_AGENT'])) {
-
使用php显示搜索引擎来的关键词
以下是相关实现代码: 复制代码 代码如下: <?php/*Plugin Name: display-search-keywordsPlugin URI: http://www.imyxiao.com/1531.htmlDescription: 当访客通过搜索引擎来到你的博客,这个插件可以显示访客搜索的关键词Version: 1.0Author:<a href="http://www.imyxiao.com/">仰肖</a>*/function unesca
-

PHP屏蔽蜘蛛访问代码及常用搜索引擎的HTTP_USER_AGENT
PHP屏蔽蜘蛛访问代码代码: 常用搜索引擎名与 HTTP_USER_AGENT对应值 百度baiduspider 谷歌googlebot 搜狗sogou 腾讯SOSOsosospider 雅虎slurp 有道youdaobot Bingbingbot MSNmsnbot Alexais_archiver function is_crawler() { $userAgent = strtolower($_SERVER['HTTP_USER_AGENT']); $spiders = array( '
-
php中获取关键词及所属来源搜索引擎名称的代码
复制代码 代码如下: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <
-
使用php记录用户通过搜索引擎进网站的关键词
复制代码 代码如下: $rfr = $_SERVER['HTTP_REFERER'];//if(!$rfr) $rfr='http://'.$_SERVER['HTTP_HOST']; if($rfr){ $p=parse_url($rfr); parse_str($p['query'],$pa); $p['host']=strtolower($p['host']); $arr_sd_key=array( 'baidu.com'=>'word', 'google.com'=>'
-
解析PHP对现有搜索引擎的调用
复制代码 代码如下: <?php $key = $_GET['key']; //获得关键字 $select = $_GET['select']; //获得搜索引擎的选择 switch($select) //根据搜索引擎的不同跳转到不同的页面 { case "google":
-
Jquery Ajax解析XML数据(同步及异步调用)简单实例
复制代码 代码如下: $.ajax({ async: true, // 默认true(异步请求) cache: true, // 默认true,设置为 false 将不会从浏览器缓存中加载请求信息. type: "POST", // 默认:GET 请求方式:[POST/GET] dataType: "xml", //默认["xml&quo
-
解析如何在C语言中调用shell命令的实现方法
1.system(执行shell 命令)相关函数 fork,execve,waitpid,popen表头文件 #include<stdlib.h>定义函数 int system(const char * string);函数说明 system()会调用fork()产生子进程,由子进程来调用/bin/sh-cstring来执行参数string字符串所代表的命令,此命令执行完后随即返回原调用的进程.在调用system()期间SIGCHLD 信号会被暂时搁置,SIGINT和SIGQUIT 信号则会
-
解析C#中委托的同步调用与异步调用(实例详解)
委托的Invoke方法用来进行同步调用.同步调用也可以叫阻塞调用,它将阻塞当前线程,然后执行调用,调用完毕后再继续向下进行.同步调用的例子: 复制代码 代码如下: using System;using System.Threading;public delegate int AddHandler(int a, int b);public class Foo { static void Main() { Console.WriteLine("**********SyncInvokeTest***
-
python基于搜索引擎实现文章查重功能
前言 文章抄袭在互联网中普遍存在,很多博主都收受其烦.近几年随着互联网的发展,抄袭等不道德行为在互联网上愈演愈烈,甚至复制.黏贴后发布标原创屡见不鲜,部分抄袭后的文章甚至标记了一些联系方式从而使读者获取源码等资料.这种恶劣的行为使人愤慨. 本文使用搜索引擎结果作为文章库,再与本地或互联网上数据做相似度对比,实现文章查重:由于查重的实现过程与一般情况下的微博情感分析实现流程相似,从而轻易的扩展出情感分析功能(下一篇将在此篇代码的基础上完成数据采集.清洗到情感分析的整个过程). 由于近期时间上并不充
-
浅谈C++11的std::function源码解析
目录 1.源码准备 2.std::function简介 3.源码解析 3.1.std::function解析 3.2.std::_Function_handler解析 3.3._Any_data解析 3.4.std::_Function_base解析 4.总结 1.源码准备 本文是基于gcc-4.9.0的源代码进行分析,std::function是C++11才加入标准的,所以低版本的gcc源码是没有std::function的,建议选择4.9.0或更新的版本去学习,不同版本的gcc源码差异应该不
-
Feign调用服务时丢失Cookie和Header信息的解决方案
目录 Feign调用服务丢失Cookie和Header信息 服务调用方 服务接受方 Feign调用存在的问题 ①feign远程调用丢失请求头 ②异步调用Feign丢失上下文问题 Feign调用服务丢失Cookie和Header信息 今天在使用Feign调用其他微服务的接口时,发现了一个问题:因为我的项目采用了无状态登录,token信息是存放在cookie中的,所以调用接口时,因为cookie中没有token信息,我的请求被拦截器拦截了. 参考几篇文章,靠谱的解决方法是:将cookie信息放到请
-
Python中的命令行参数解析工具之docopt详解
前言 docopt 是一个开源的库,代码地址:https://github.com/docopt/docopt.它在 README 中就已经做了详细的介绍,并且还附带了很多例子可供学习,这篇文章也是翻译一下 README 中内容-- docopt 最大的特点在于不用考虑如何解析命令行参数,而是当你把心中想要的格式按照一定的规则写出来后,解析也就完成了. docopt的安装 docopt有很多种版本,分别支持不同的语言,最简答的docopt支持python脚本,docopt.java支持java脚
-
Android开发之XML文件解析的使用
前言 本文主要介绍在Android中怎样来解析XML文件.主要采用的是SAX机制,SAX全称为Simple API for XML,它既是一种接口,也是一个软件包.作为接口,SAX是事件驱动型XML解析的一个标准接口.XML文件解析一般有2种方法,DOM和SAX.其中DOM需要先将xml文档全部读入到电脑内存中,当文档内容太大时,该方法并不适用.SAX就比较好的解决了该问题,它是逐行解析的,可以随时中断.但是SAX的操作比较复杂.因此,这2种方法各有优缺点,看具体应用情况.在前面的文章Qt学习
-
Linux系统中C语言编程创建函数fork()执行解析
最近在看进程间的通信,看到了fork()函数,虽然以前用过,这次经过思考加深了理解.现总结如下: 1.函数本身 (1)头文件 #include<unistd.h> #include<sys/types.h> (2)函数原型 pid_t fork( void); (pid_t 是一个宏定义,其实质是int 被定义在#include<sys/types.h>中) 返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID:否则,出错返回-1 (3)函数说明 一