Python读写Excel文件的实例
最近由于经常要用到Excel,需要根据Excel表格中的内容对一些apk进行处理,手动处理很麻烦,于是决定写脚本来处理。首先贴出网上找来的读写Excel的脚本。
1.读取Excel(需要安装xlrd):
#-*- coding: utf8 -*-
import xlrd
fname = "reflect.xls"
bk = xlrd.open_workbook(fname)
shxrange = range(bk.nsheets)
try:
sh = bk.sheet_by_name("Sheet1")
except:
print "no sheet in %s named Sheet1" % fname
#获取行数
nrows = sh.nrows
#获取列数
ncols = sh.ncols
print "nrows %d, ncols %d" % (nrows,ncols)
#获取第一行第一列数据
cell_value = sh.cell_value(1,1)
#print cell_value
row_list = []
#获取各行数据
for i in range(1,nrows):
row_data = sh.row_values(i)
row_list.append(row_data)
2.写入Excel(需安装pyExcelerator)
from pyExcelerator import *
w = Workbook() #创建一个工作簿
ws = w.add_sheet('Hey, Hades') #创建一个工作表
ws.write(0,0,'bit') #在1行1列写入bit
ws.write(0,1,'huang') #在1行2列写入huang
ws.write(1,0,'xuan') #在2行1列写入xuan
w.save('mini.xls') #保存
3.再举个自己写的读写Excel的例子
读取reflect.xls中的某些信息进行处理后写入mini.xls文件中。
#-*- coding: utf8 -*-
import xlrd
from pyExcelerator import *
w = Workbook()
ws = w.add_sheet('Sheet1')
fname = "reflect.xls"
bk = xlrd.open_workbook(fname)
shxrange = range(bk.nsheets)
try:
sh = bk.sheet_by_name("Sheet1")
except:
print "no sheet in %s named Sheet1" % fname
nrows = sh.nrows
ncols = sh.ncols
print "nrows %d, ncols %d" % (nrows,ncols)
cell_value = sh.cell_value(1,1)
#print cell_value
row_list = []
mydata = []
for i in range(1,nrows):
row_data = sh.row_values(i)
pkgdatas = row_data[3].split(',')
#pkgdatas.split(',')
#获取每个包的前两个字段
for pkgdata in pkgdatas:
pkgdata = '.'.join((pkgdata.split('.'))[:2])
mydata.append(pkgdata)
#将列表排序
mydata = list(set(mydata))
print mydata
#将列表转化为字符串
mydata = ','.join(mydata)
#写入数据到每行的第一列
ws.write(i,0,mydata)
mydata = []
row_list.append(row_data[3])
#print row_list
w.save('mini.xls')
4.现在我需要根据Excel文件中满足特定要求的apk的md5值来从服务器获取相应的apk样本,就需要这样做:
#-*-coding:utf8-*-
import xlrd
import os
import shutil
fname = "./excelname.xls"
bk = xlrd.open_workbook(fname)
shxrange = range(bk.nsheets)
try:
#打开Sheet1工作表
sh = bk.sheet_by_name("Sheet1")
except:
print "no sheet in %s named Sheet1" % fname
#获取行数
nrows = sh.nrows
#获取列数
ncols = sh.ncols
#print "nrows %d, ncols %d" % (nrows,ncols)
#获取第一行第一列数据
cell_value = sh.cell_value(1,1)
#print cell_value
row_list = []
#range(起始行,结束行)
for i in range(1,nrows):
row_data = sh.row_values(i)
if row_data[6] == "HXB":
filename = row_data[3]+".apk"
#print "%s %s %s" %(i,row_data[3],filename)
filepath = r"./1/"+filename
print "%s %s %s" %(i,row_data[3],filepath)
if os.path.exists(filepath):
shutil.copy(filepath, r"./myapk/")
补充一个使用xlwt3进行Excel文件的写操作。
import xlwt3
if __name__ == '__main__':
datas = [['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h']]#二维数组
file_path = 'D:\\test.xlsx'
wb = xlwt3.Workbook()
sheet = wb.add_sheet('test')#sheet的名称为test
#单元格的格式
style = 'pattern: pattern solid, fore_colour yellow; '#背景颜色为黄色
style += 'font: bold on; '#粗体字
style += 'align: horz centre, vert center; '#居中
header_style = xlwt3.easyxf(style)
row_count = len(datas)
col_count = len(datas[0])
for row in range(0, row_count):
col_count = len(datas[row])
for col in range(0, col_count):
if row == 0:#设置表头单元格的格式
sheet.write(row, col, datas[row][col], header_style)
else:
sheet.write(row, col, datas[row][col])
wb.save(file_path)
输出的文件内容如下图:
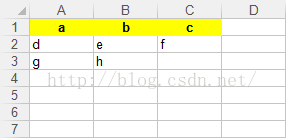
注:以上代码在Python 3.x版本测试通过。
好了,python操作Excel就这么!些了,简单吧
相关推荐
-

python中使用xlrd、xlwt操作excel表格详解
最近遇到一个情景,就是定期生成并发送服务器使用情况报表,按照不同维度统计,涉及python对excel的操作,上网搜罗了一番,大多大同小异,而且不太能满足需求,不过经过一番对源码的"研究"(用此一词让我觉得颇有成就感)之后,基本解决了日常所需.主要记录使用过程的常见问题及解决. python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库.可从这里下载https://pypi.python.org/pypi.下面分别记录python
-
用python读写excel的方法
本文实例讲述了用python读写excel的方法.分享给大家供大家参考.具体如下: 最近需要从多个excel表里面用各种方式整理一些数据,虽然说原来用过java做这类事情,但是由于最近在学python,所以当然就决定用python尝试一下了.发现python果然简洁很多.这里简单记录一下.(由于是用到什么学什么,所以不算太深入,高手勿喷,欢迎指导) 一.读excel表 读excel要用到xlrd模块,官网安装(http://pypi.python.org/pypi/xlrd).然后就可以跟着里面
-
Python中使用第三方库xlutils来追加写入Excel文件示例
目前还没有更好的方法来追写Excel,lorinnn在网上搜索到以及之后用到的方法就是使用第三方库xlutils来实现了这个功能,主体思想就是先复制一份Sheet然后再次基础上追加并保存到一份新的Excel文档中去. 使用xlutils 代码实现如下: # -*- coding: utf-8 -*- ''' Created on 2012-12-17 @author: walfred @module: XLRDPkg.write_append @description: ''' import o
-
用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
用python + openpyxl处理excel2007文档思路以及心得
寻觅工具 确定任务之后第一步就是找个趁手的库来干活. Python Excel上列出了xlrd.xlwt.xlutils这几个包,但是 它们都比较老,xlwt甚至不支持07版以后的excel 它们的文档不太友好,都可能需要去读源代码,而老姐的任务比较紧,加上我当时在期末,没有这个时间细读源代码 再一番搜索后我找到了openpyxl,支持07+的excel,一直有人在维护,文档清晰易读,参照Tutorial和API文档很快就能上手,就是它了~ 安装 这个很容易,直接pip install open
-
python抓取某汽车网数据解析html存入excel示例
1.某汽车网站地址 2.使用firefox查看后发现,此网站的信息未使用json数据,而是简单那的html页面而已 3.使用pyquery库中的PyQuery进行html的解析 页面样式: 复制代码 代码如下: def get_dealer_info(self): """获取经销商信息""" css_select = 'html body div.box div.news_wrapper div.main div.ne
-
python使用xlrd模块读写Excel文件的方法
本文实例讲述了python使用xlrd模块读写Excel文件的方法.分享给大家供大家参考.具体如下: 一.安装xlrd模块 到python官网下载http://pypi.python.org/pypi/xlrd模块安装,前提是已经安装了python 环境. 二.使用介绍 1.导入模块 复制代码 代码如下: import xlrd 2.打开Excel文件读取数据 复制代码 代码如下: data = xlrd.open_workbook('excelFile.xls') 3.使用技巧 获取一个工作表
-
python读取excel表格生成erlang数据
为了将excel数据自动转换成所需要的erlang数据,听同事说使用python会很方便简单,就自学了两天python,写了一个比较粗糙的python脚本,不过能用,有什么优化的地方请指教 代码如下: #!/usr/bin/env python # -*- coding: UTF-8 -*- import sys from openpyxl.reader.excel import load_workbook import os import os.path def gen_data(filena
-
python高手之路python处理excel文件(方法汇总)
用python来自动生成excel数据文件.python处理excel文件主要是第三方模块库xlrd.xlwt.xluntils和pyExcelerator,除此之外,python处理excel还可以用win32com和openpyxl模块. 方法一: 小罗问我怎么从excel中读取数据,然后我百了一番,做下记录 excel数据图(小罗说数据要给客户保密,我随手写了几行数据): python读取excel文件代码: #!/usr/bin/env python # -*- coding: utf-
-
Python中使用第三方库xlrd来写入Excel文件示例
继上一篇文章使用xlrd来读Excel之后,这一篇文章就来介绍下,如何来写Excel,写Excel我们需要使用第三方库xlwt,和xlrd一样,xlrd表示read xls,xlwt表示write xls,同样目前版本只支持97-03版本的Excel.xlwt下载:xlwt 0.7.4 安装xlwt 安装方式一样是python setup.py install就可以了,或者直接解压到你的工程目录中. API介绍 获取一个xls实例 复制代码 代码如下: xls = ExcelWrite.Work